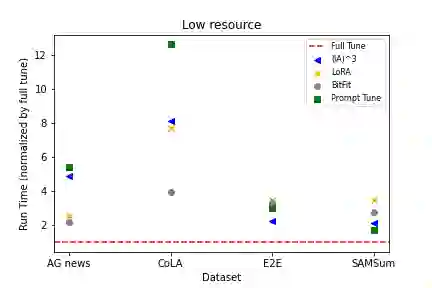
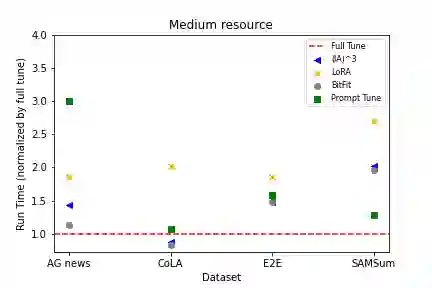
As foundation models continue to exponentially scale in size, efficient methods of adaptation become increasingly critical. Parameter-efficient fine-tuning (PEFT), a recent class of techniques that require only modifying a small percentage of the model parameters, is currently the most popular method for adapting large language models (LLMs). Several PEFT techniques have recently been proposed with varying tradeoffs. We provide a comprehensive and uniform benchmark of various PEFT techniques across a representative LLM, the FLAN-T5 model, and evaluate model performance across different data scales of classification and generation datasets. Based on this, we provide a framework for choosing the optimal fine-tuning techniques given the task type and data availability. Contrary to popular belief, we also empirically prove that PEFT techniques converge slower than full tuning in low data scenarios, and posit the amount of data required for PEFT methods to both perform well and converge efficiently. Lastly, we further optimize these PEFT techniques by selectively choosing which parts of the model to train, and find that these techniques can be applied with significantly fewer parameters while maintaining and even improving performance.
翻译:随着基础模型规模呈指数级增长,高效的适配方法变得愈发关键。参数高效微调(PEFT)作为近期兴起的一类仅需修改模型少量参数的技术,目前已成为适配大语言模型(LLMs)最主流的方法。近期提出的多种PEFT技术在性能与成本之间存在不同权衡。我们针对代表性LLM——FLAN-T5模型,对多种PEFT技术进行了全面统一的基准测试,并在不同数据规模的分类与生成数据集上评估模型性能。基于此,我们根据任务类型与数据可用性,构建了最优微调技术的选择框架。与普遍认知相反,我们通过实证证明在低数据场景下PEFT技术收敛速度慢于全量微调,并提出了PEFT方法实现良好性能与高效收敛所需的数据量阈值。最后,我们通过选择性训练模型特定部分进一步优化PEFT技术,发现这些技术可在显著减少参数量的同时维持甚至提升性能表现。