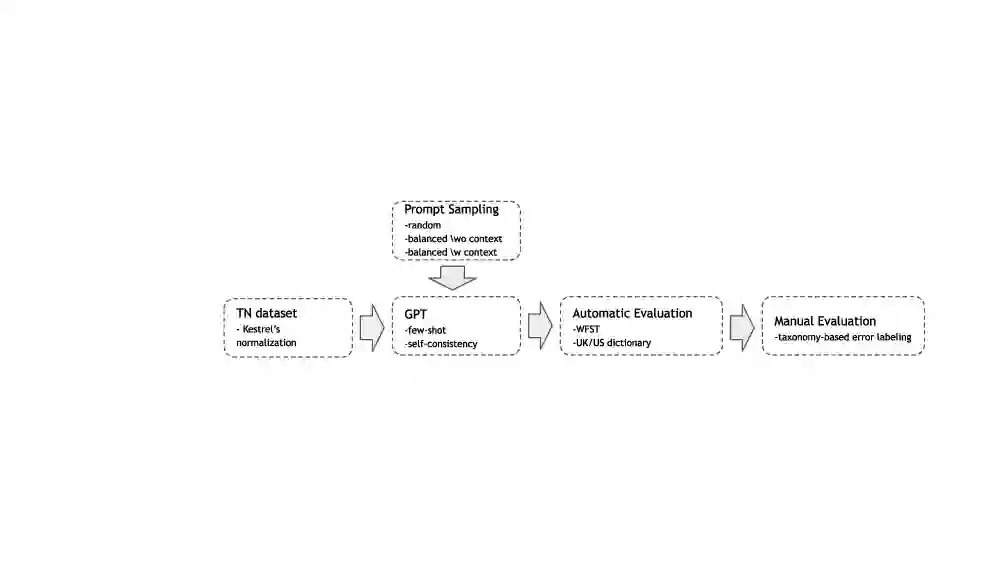
Text normalization - the conversion of text from written to spoken form - is traditionally assumed to be an ill-formed task for language models. In this work, we argue otherwise. We empirically show the capacity of Large-Language Models (LLM) for text normalization in few-shot scenarios. Combining self-consistency reasoning with linguistic-informed prompt engineering, we find LLM based text normalization to achieve error rates around 40\% lower than top normalization systems. Further, upon error analysis, we note key limitations in the conventional design of text normalization tasks. We create a new taxonomy of text normalization errors and apply it to results from GPT-3.5-Turbo and GPT-4.0. Through this new framework, we can identify strengths and weaknesses of GPT-based TN, opening opportunities for future work.
翻译:文本规范化——将文本从书面形式转换为口语形式——传统上被认为是一项语言模型难以处理的任务。在本研究中,我们提出了相反的观点。我们通过实验证明了大型语言模型(LLM)在少样本场景下进行文本规范化的能力。通过将自一致性推理与语言信息驱动的提示工程相结合,我们发现基于LLM的文本规范化能够实现比顶级规范化系统降低约40%的错误率。此外,经过错误分析,我们指出了传统文本规范化任务设计中的关键局限性。我们创建了一个新的文本规范化错误分类体系,并将其应用于GPT-3.5-Turbo和GPT-4.0的结果。通过这一新框架,我们能够识别基于GPT的文本规范化的优势与不足,为未来研究开辟了机遇。