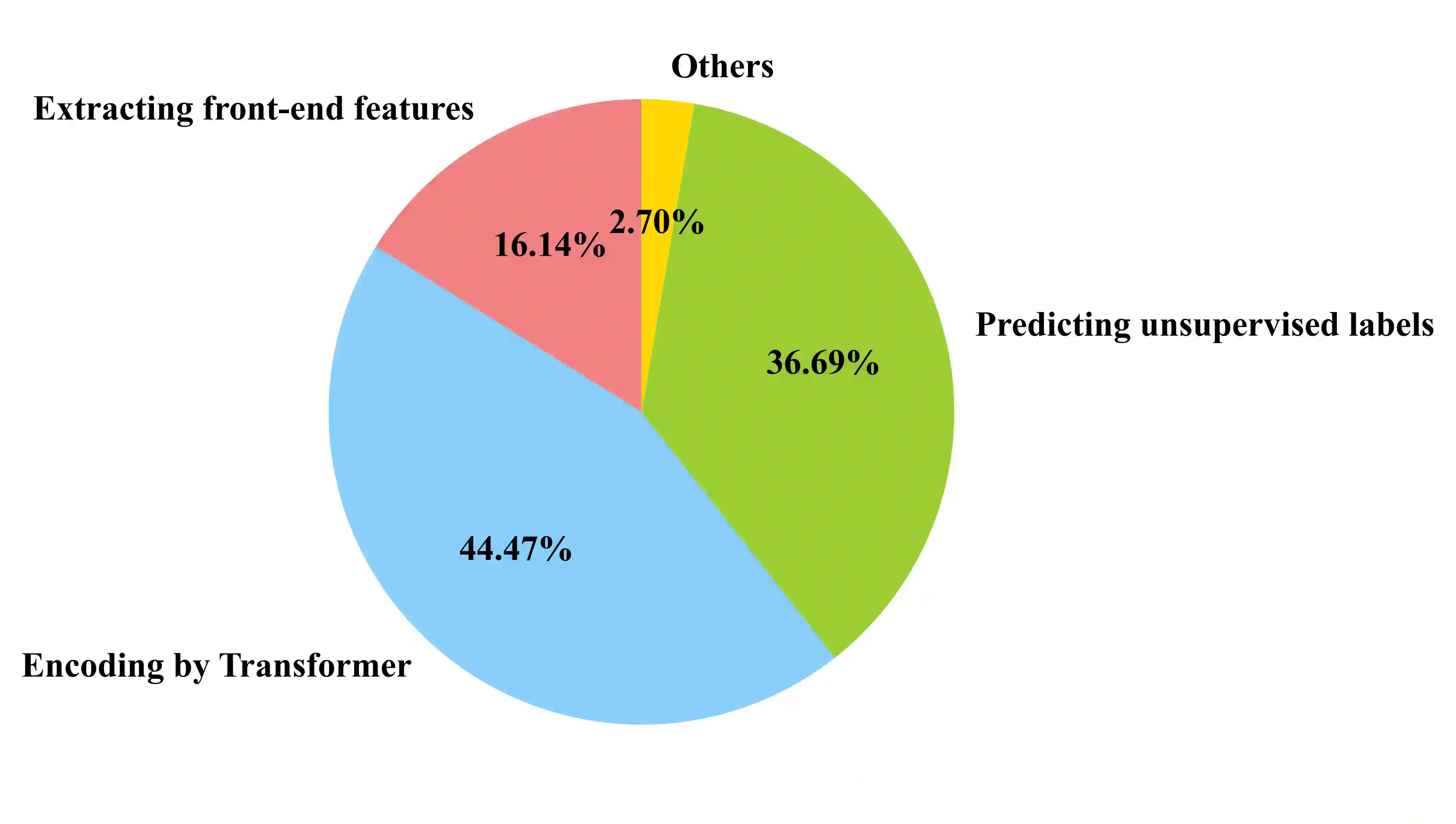
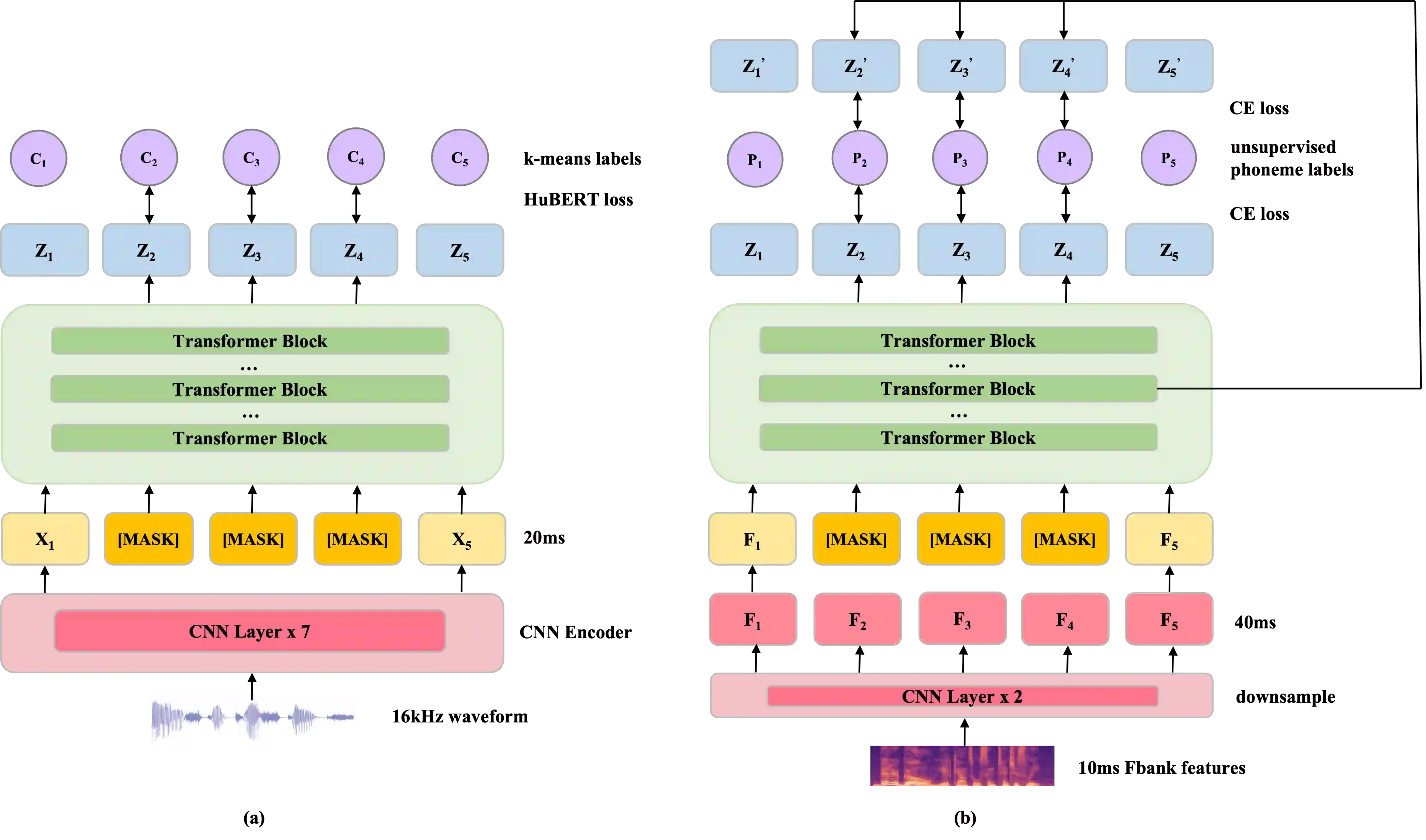
Recent years have witnessed significant advancements in self-supervised learning (SSL) methods for speech-processing tasks. Various speech-based SSL models have been developed and present promising performance on a range of downstream tasks including speech recognition. However, existing speech-based SSL models face a common dilemma in terms of computational cost, which might hinder their potential application and in-depth academic research. To address this issue, we first analyze the computational cost of different modules during HuBERT pre-training and then introduce a stack of efficiency optimizations, which is named Fast-HuBERT in this paper. The proposed Fast-HuBERT can be trained in 1.1 days with 8 V100 GPUs on the Librispeech 960h benchmark, without performance degradation, resulting in a 5.2x speedup, compared to the original implementation. Moreover, we explore two well-studied techniques in the Fast-HuBERT and demonstrate consistent improvements as reported in previous work.
翻译:近年来,自监督学习方法在语音处理任务中取得了显著进展。多种基于语音的自监督模型已被开发出来,并在包括语音识别在内的多项下游任务中展现出良好性能。然而,现有基于语音的自监督模型普遍面临计算成本高昂的困境,这可能阻碍其潜在应用和深入的学术研究。为解决这一问题,我们首先分析了HuBERT预训练过程中不同模块的计算成本,随后引入了一系列效率优化策略,并将其命名为 Fast-HuBERT。所提出的 Fast-HuBERT 在 Librispeech 960小时基准上使用8块V100 GPU仅需1.1天即可完成训练,且性能无下降,与原始实现相比实现了5.2倍的加速。此外,我们在 Fast-HuBERT 中探索了两项已有充分研究的技术,并验证了其与前人工作一致的性能提升。