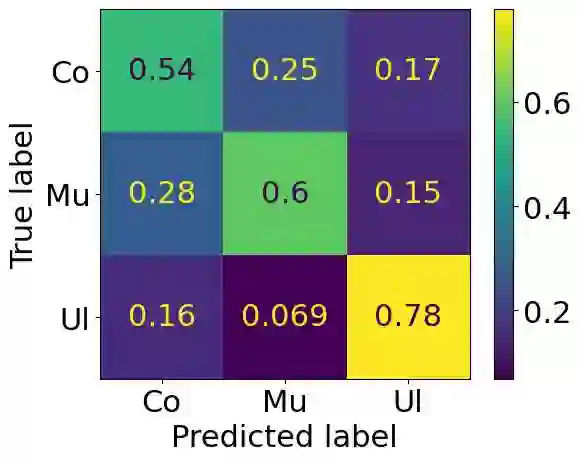
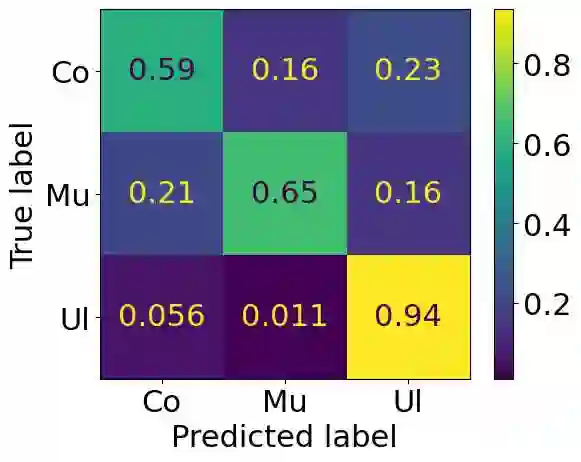
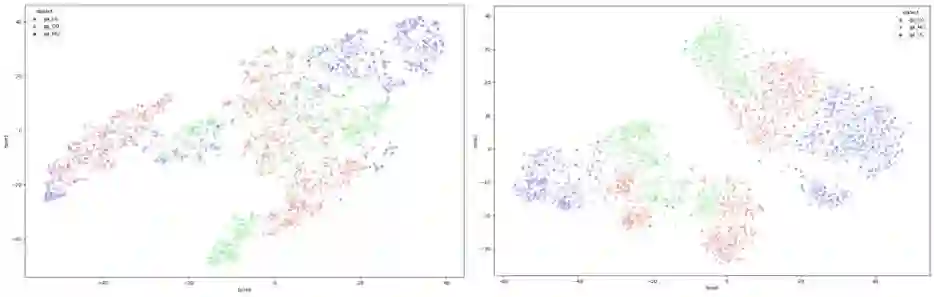
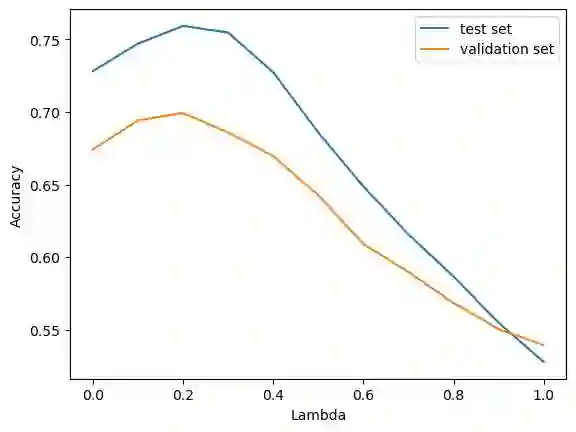
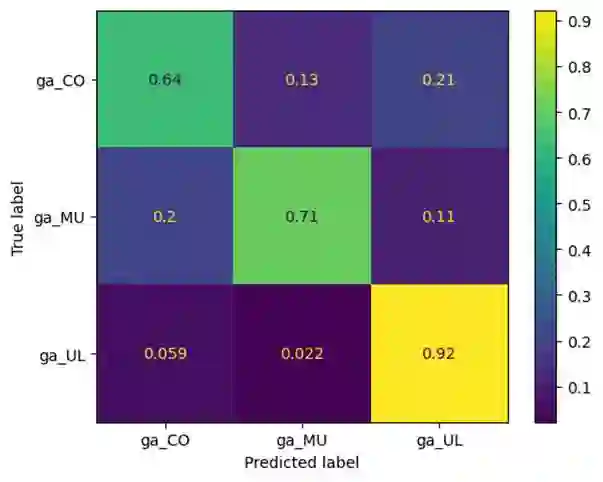
The Irish language is rich in its diversity of dialects and accents. This compounds the difficulty of creating a speech recognition system for the low-resource language, as such a system must contend with a high degree of variability with limited corpora. A recent study investigating dialect bias in Irish ASR found that balanced training corpora gave rise to unequal dialect performance, with performance for the Ulster dialect being consistently worse than for the Connacht or Munster dialects. Motivated by this, the present experiments investigate spoken dialect identification of Irish, with a view to incorporating such a system into the speech recognition pipeline. Two acoustic classification models are tested, XLS-R and ECAPA-TDNN, in conjunction with a text-based classifier using a pretrained Irish-language BERT model. The ECAPA-TDNN, particularly a model pretrained for language identification on the VoxLingua107 dataset, performed best overall, with an accuracy of 73%. This was further improved to 76% by fusing the model's outputs with the text-based model. The Ulster dialect was most accurately identified, with an accuracy of 94%, however the model struggled to disambiguate between the Connacht and Munster dialects, suggesting a more nuanced approach may be necessary to robustly distinguish between the dialects of Irish.
翻译:爱尔兰语方言和口音多样且丰富,这加剧了为这一低资源语言创建语音识别系统的难度,因为此类系统必须在语料库有限的情况下应对高度变异。最近一项关于爱尔兰语自动语音识别中方言偏差的研究发现,均衡的训练语料库会导致方言性能不均衡,其中阿尔斯特方言的表现始终低于康诺特或芒斯特方言。受此启发,本实验研究了爱尔兰语的口语方言识别,旨在将此类系统集成到语音识别流程中。测试了两种声学分类模型:XLS-R 和 ECAPA-TDNN,并结合基于文本的分类器(使用预训练的爱尔兰语BERT模型)。预训练于VoxLingua107数据集进行语言识别的ECAPA-TDNN模型总体表现最佳,准确率达73%。通过将该模型输出与文本模型融合,准确率进一步提升至76%。阿尔斯特方言的识别准确率最高,达94%,但模型难以区分康诺特和芒斯特方言,这表明可能需要更精细的方法来稳健区分爱尔兰语的各地方言。