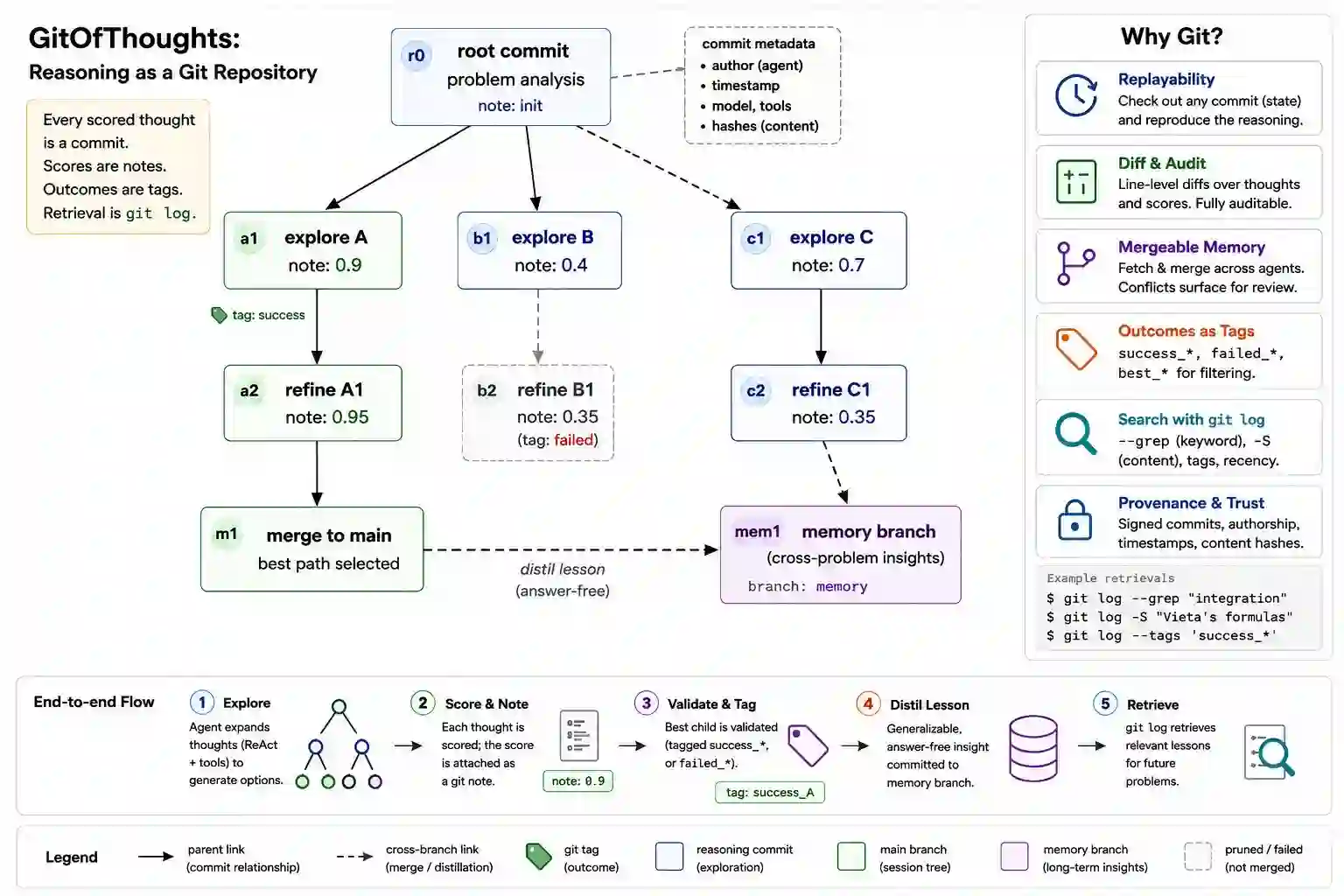
Large language model reasoning leaves no trace once it is done. The steps of a chain of thought disappear when the context window closes, a pruned search branch is just gone, and memory buffers cannot be diffed, merged, or audited. Code, infrastructure, and experiments are all version-controlled. Reasoning is not. GitOfThoughts stores an agent's reasoning tree as a git repository. Every scored thought becomes a commit, scores become notes, outcomes become tags, and retrieval is just git log over the agent's own history. We use this to test something simple. Does giving an agent memory from past problems actually make it more accurate? We tried five memory stores (none, a markdown file, a vector database, a graph, and git) across two benchmarks, two model sizes, and several pre-registered repeat experiments. The answer, on new problems, is no, including one promising early result that did not hold up when we repeated it. Memory only helps once the problem being solved is nearly identical to something already in memory (cosine similarity above about 0.8); below that, it does nothing. In other words, the model is finding the answer rather than learning the method. Even a model 4.5x larger still cannot pull a reusable method out of a worked example; it just gets better at spotting near-copies. The only thing that reliably helped on new problems was generating several answers and picking the most common one (self-consistency). So the case for using git as the memory store is not that it retrieves better. It is that it gives auditability, history, and the ability to merge two agents' memories, at no cost to accuracy.
翻译:暂无翻译