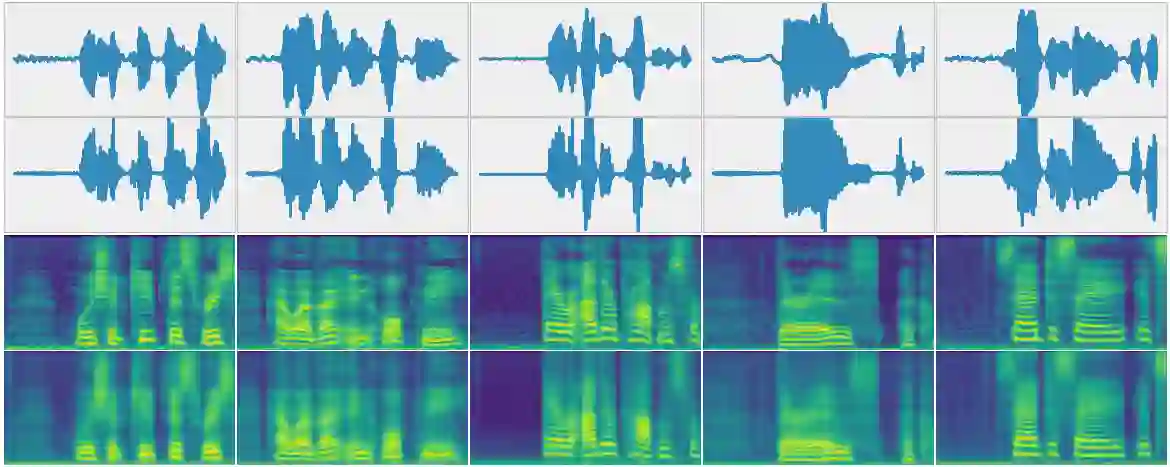
Implicit neural representations (INRs) are a rapidly growing research field, which provides alternative ways to represent multimedia signals. Recent applications of INRs include image super-resolution, compression of high-dimensional signals, or 3D rendering. However, these solutions usually focus on visual data, and adapting them to the audio domain is not trivial. Moreover, it requires a separately trained model for every data sample. To address this limitation, we propose HyperSound, a meta-learning method leveraging hypernetworks to produce INRs for audio signals unseen at training time. We show that our approach can reconstruct sound waves with quality comparable to other state-of-the-art models.
翻译:隐式神经表征(INRs)是一个快速发展的研究领域,为多媒体信号的表示提供了替代方案。近年来,INRs 的应用包括图像超分辨率、高维信号压缩以及三维渲染。然而,这些解决方案通常聚焦于视觉数据,将其适配到音频领域并非易事。此外,每个数据样本都需要单独训练的模型。为解决这一局限,我们提出了 HyperSound——一种利用超网络进行元学习的方法,能够在训练时生成未见过的音频信号的 INRs。实验表明,我们的方法重建声波的质量可与其它最先进模型相媲美。