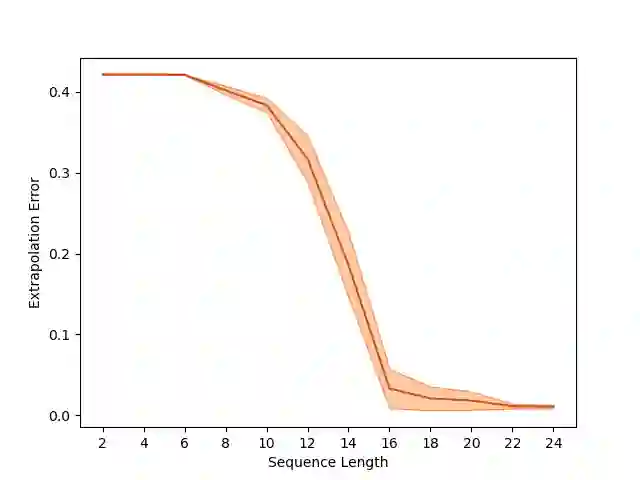
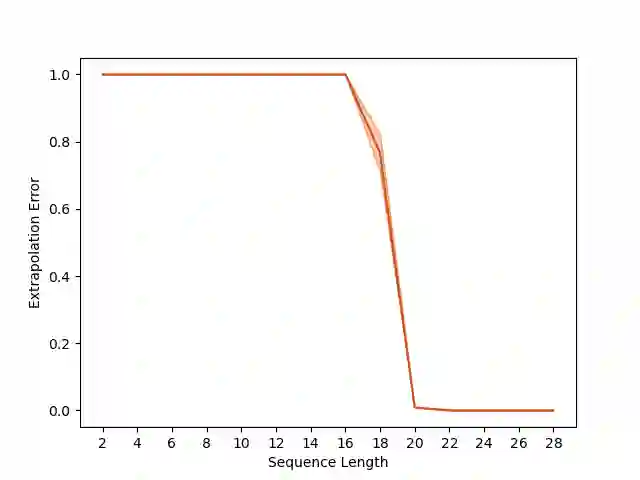
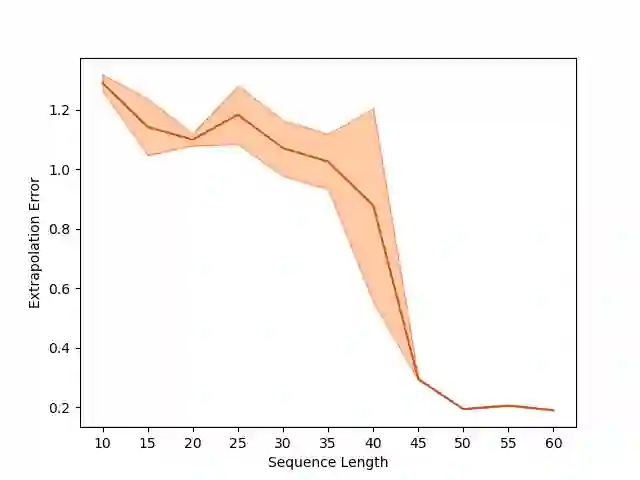
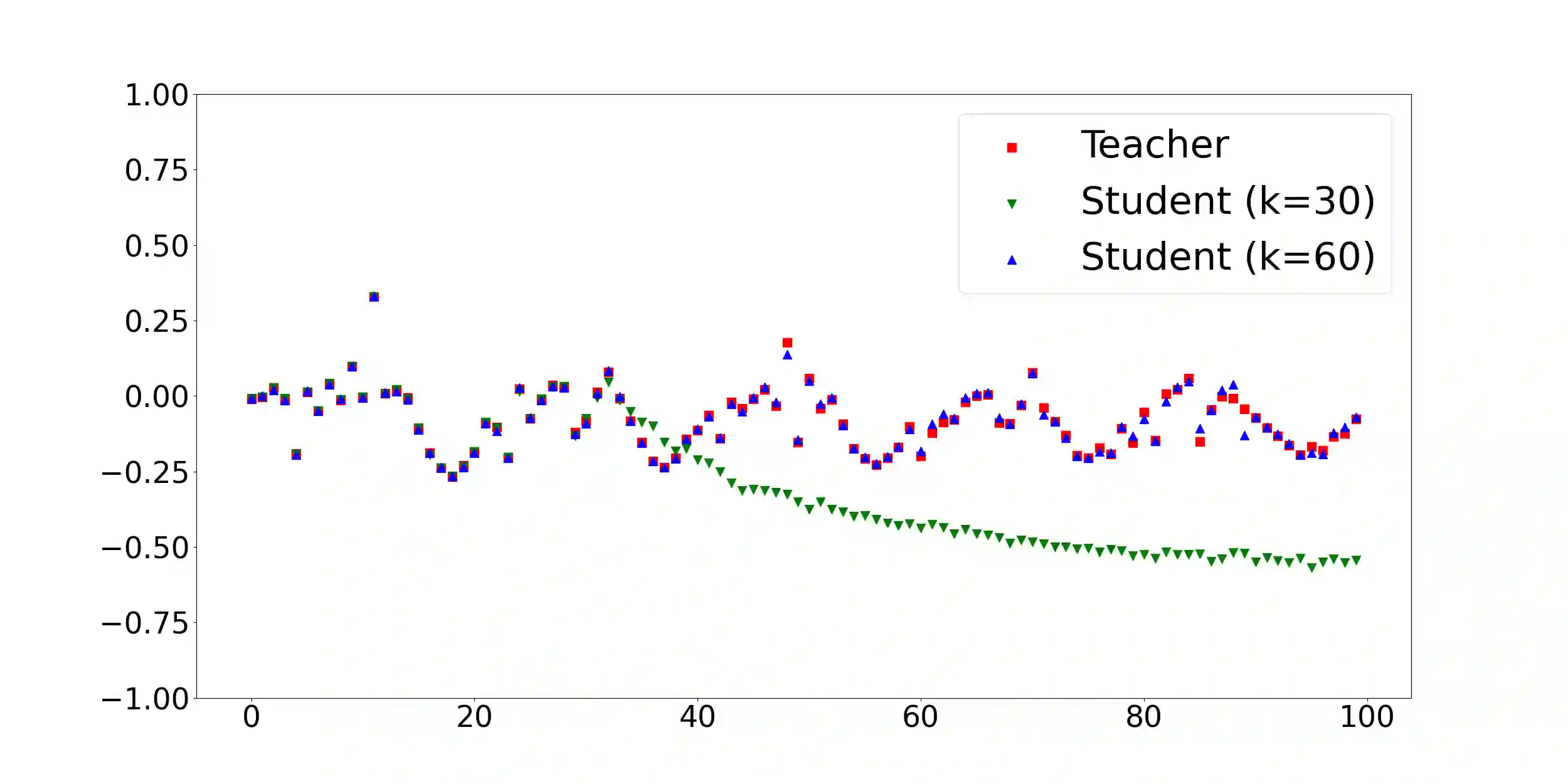
Overparameterization in deep learning typically refers to settings where a trained neural network (NN) has representational capacity to fit the training data in many ways, some of which generalize well, while others do not. In the case of Recurrent Neural Networks (RNNs), there exists an additional layer of overparameterization, in the sense that a model may exhibit many solutions that generalize well for sequence lengths seen in training, some of which extrapolate to longer sequences, while others do not. Numerous works have studied the tendency of Gradient Descent (GD) to fit overparameterized NNs with solutions that generalize well. On the other hand, its tendency to fit overparameterized RNNs with solutions that extrapolate has been discovered only recently and is far less understood. In this paper, we analyze the extrapolation properties of GD when applied to overparameterized linear RNNs. In contrast to recent arguments suggesting an implicit bias towards short-term memory, we provide theoretical evidence for learning low-dimensional state spaces, which can also model long-term memory. Our result relies on a dynamical characterization which shows that GD (with small step size and near-zero initialization) strives to maintain a certain form of balancedness, as well as on tools developed in the context of the moment problem from statistics (recovery of a probability distribution from its moments). Experiments corroborate our theory, demonstrating extrapolation via learning low-dimensional state spaces with both linear and non-linear RNNs.
翻译:深度学习中的过参数化通常指训练后的神经网络具备多种方式拟合训练数据的表征能力,其中部分泛化能力优异,而其他则表现不佳。在循环神经网络(RNN)的情形中,存在另一层面的过参数化:模型可能产生众多在训练所见序列长度上泛化良好的解,但其中仅部分能外推至更长序列,其余则无法实现。大量研究探讨了梯度下降(GD)拟合具有优异泛化解的过参数化神经网络的倾向性。然而,关于GD拟合具有外推能力的过参数化RNN解的特性,直至近期才被揭示且理解尚浅。本文分析了GD应用于过参数化线性RNN时的外推特性。与近期主张存在隐式短期记忆偏好的论点相反,我们从理论层面论证了低维状态空间的学习过程——该空间同时具备建模长期记忆的能力。该结论基于两项关键支撑:其一,通过动力学特征表明小步长、近零初始化的GD倾向于维持特定形式的平衡态;其二,借助统计学矩问题(从分布矩恢复概率分布)框架下发展的分析工具。实验验证了我们的理论,证实了线性及非线性RNN均能通过学习低维状态空间实现外推。