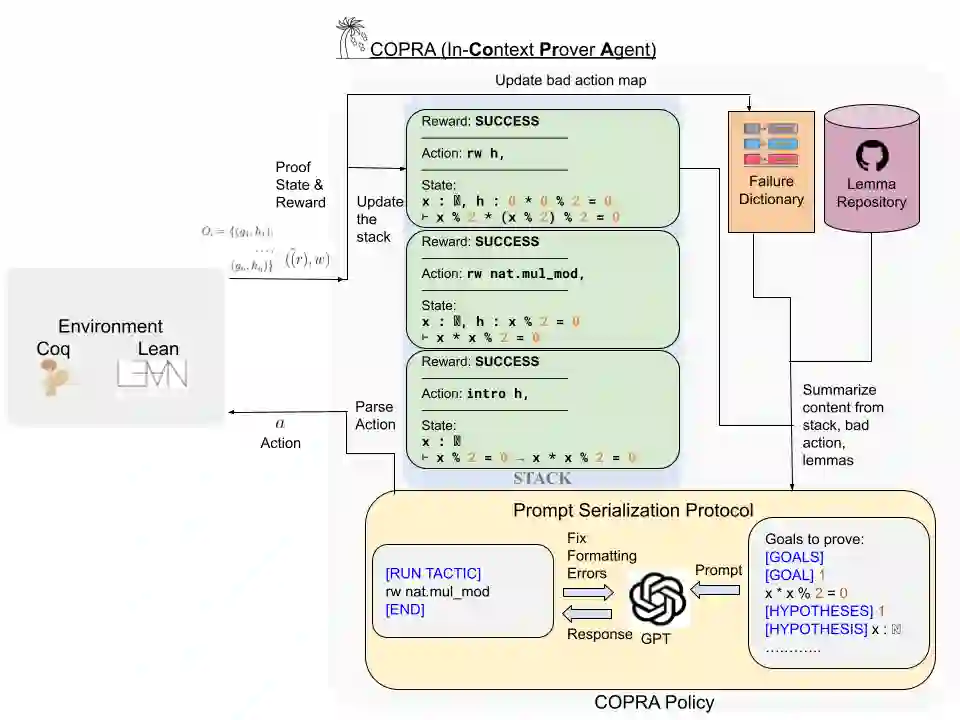
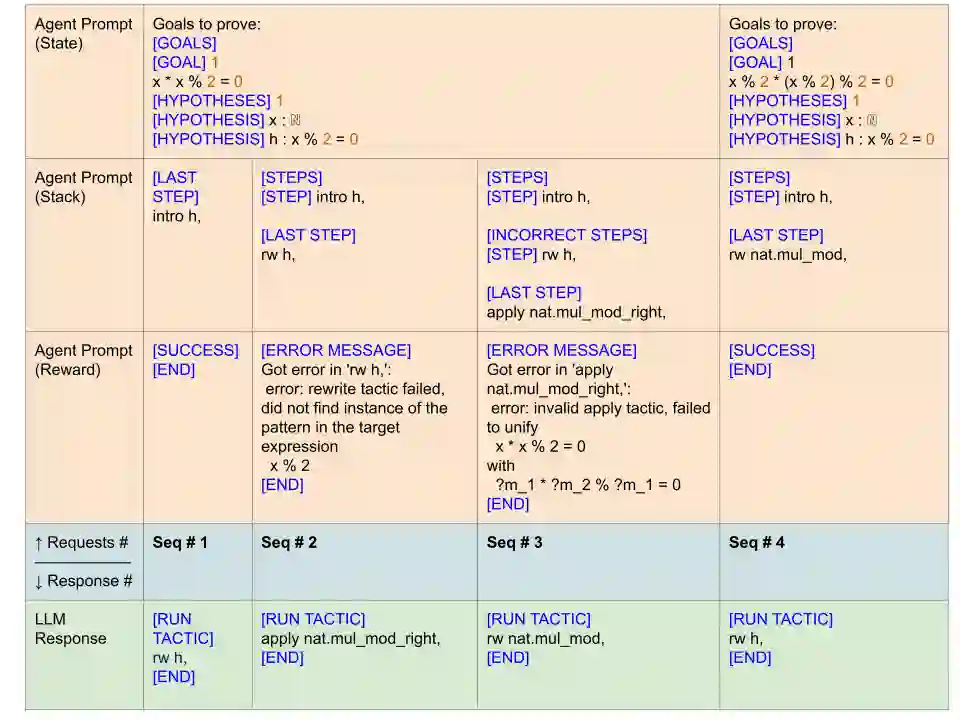
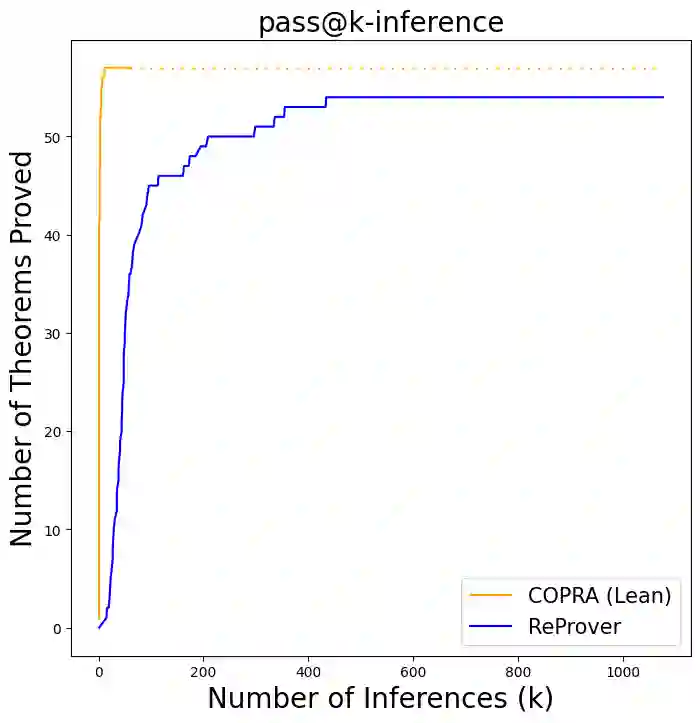
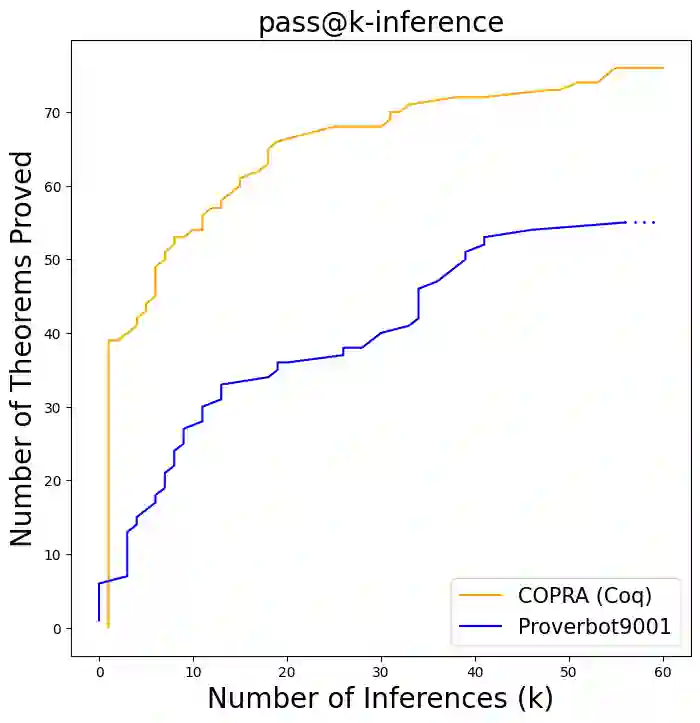
Language agents, which use a large language model (LLM) capable of in-context learning to interact with an external environment, have recently emerged as a promising approach to control tasks. We present the first language-agent approach to formal theorem-proving. Our method, COPRA, uses a high-capacity, black-box LLM (GPT-4) as part of a policy for a stateful backtracking search. During the search, the policy can select proof tactics and retrieve lemmas and definitions from an external database. Each selected tactic is executed in the underlying proof framework, and the execution feedback is used to build the prompt for the next policy invocation. The search also tracks selected information from its history and uses it to reduce hallucinations and unnecessary LLM queries. We evaluate COPRA on the miniF2F benchmark for Lean and a set of Coq tasks from the Compcert project. On these benchmarks, COPRA is significantly better than one-shot invocations of GPT-4, as well as state-of-the-art models fine-tuned on proof data, at finding correct proofs quickly.
翻译:语言智能体利用具备上下文学习能力的大语言模型(LLM)与外部环境交互,近期已成为控制任务中的一种有前景的方法。我们提出了首个面向形式定理证明的语言智能体方法。我们的方法COPRA采用高容量黑盒LLM(GPT-4)作为有状态回溯搜索策略的一部分。在搜索过程中,该策略可选择证明策略,并从外部数据库中检索引理和定义。每个选定的策略在底层证明框架中执行,执行反馈用于构建下一次策略调用的提示。搜索还会跟踪历史中的选定信息,用于减少幻觉和不必要的LLM查询。我们在针对Lean的miniF2F基准测试以及来自Compcert项目的一组Coq任务上评估了COPRA。在这些基准测试中,COPRA在快速找到正确证明方面显著优于GPT-4的一次性调用,以及基于证明数据微调的最新模型。