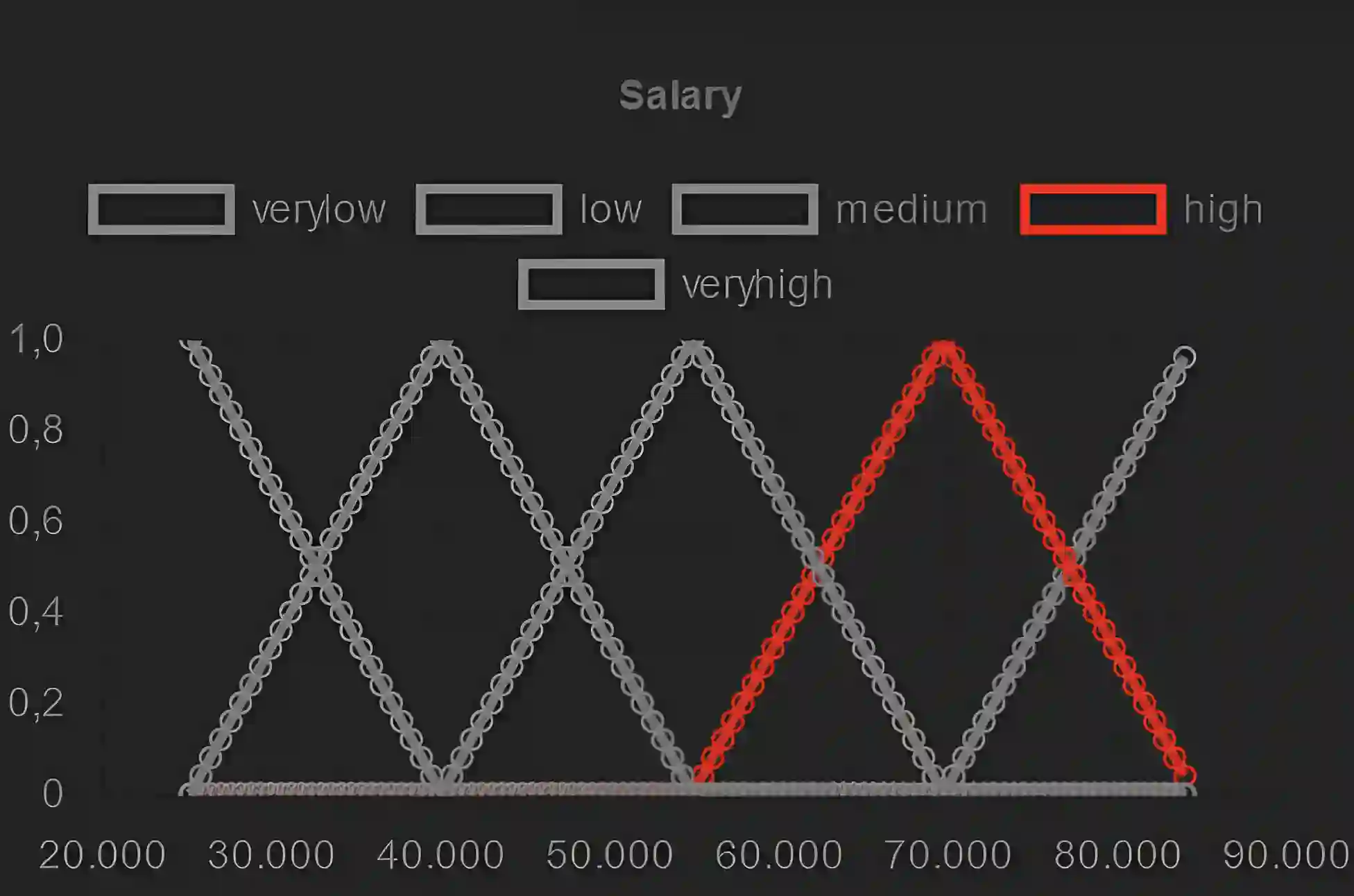
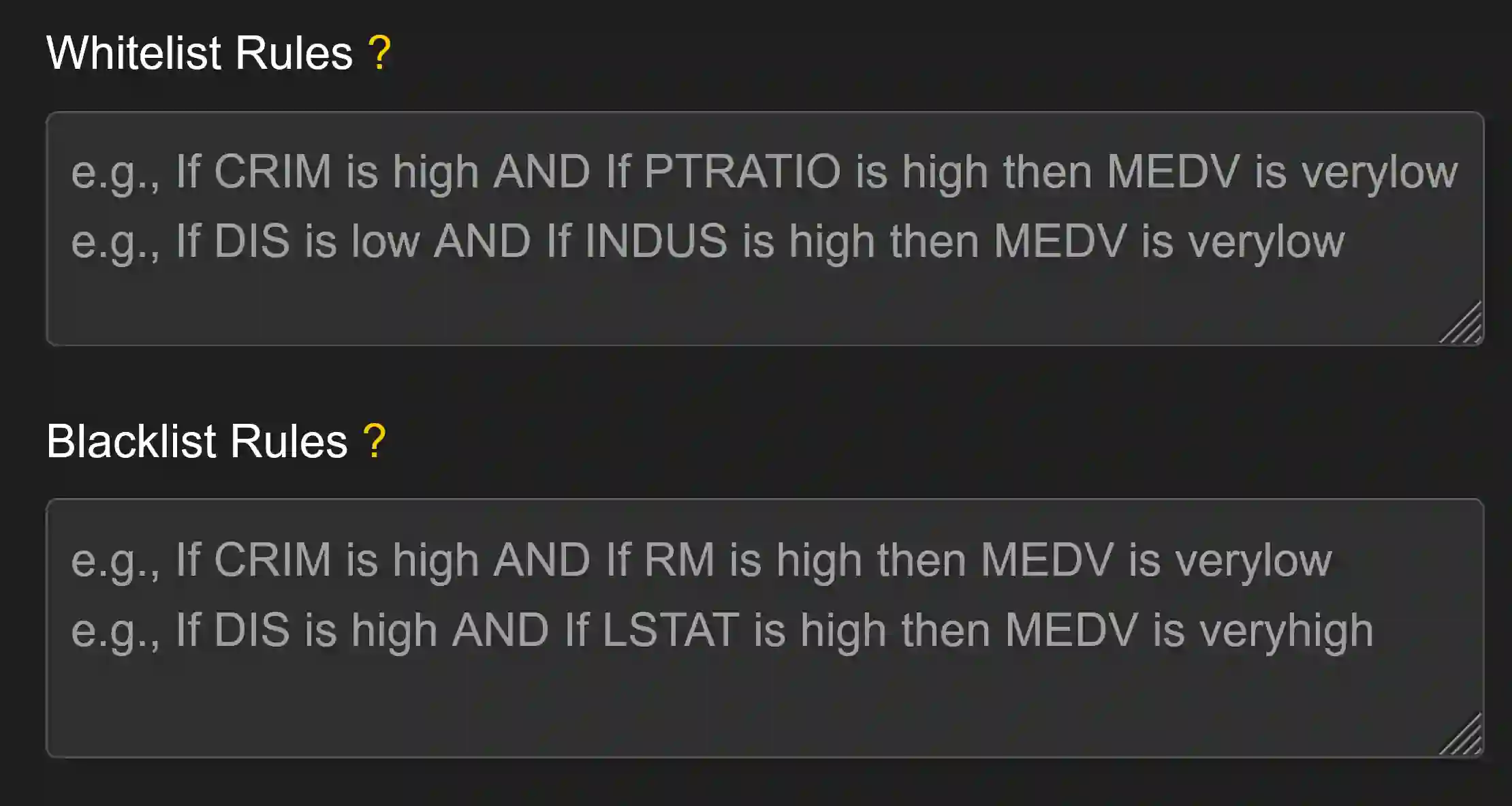
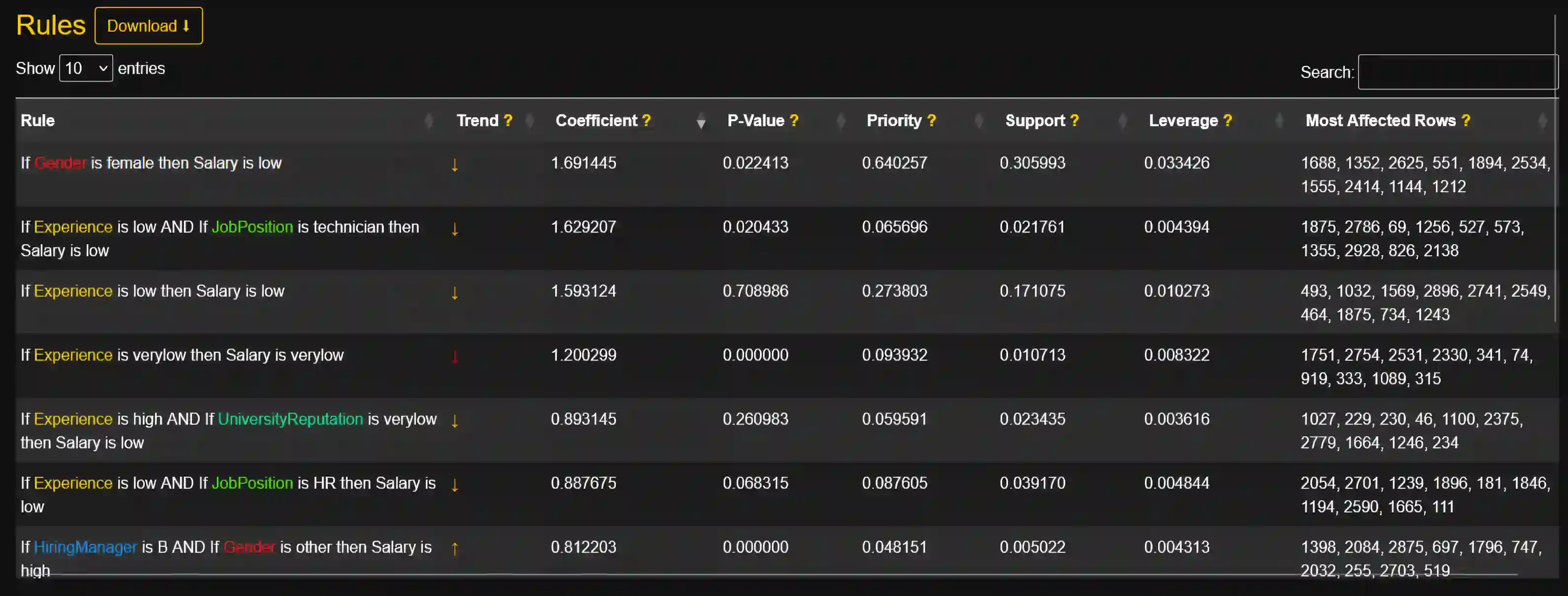
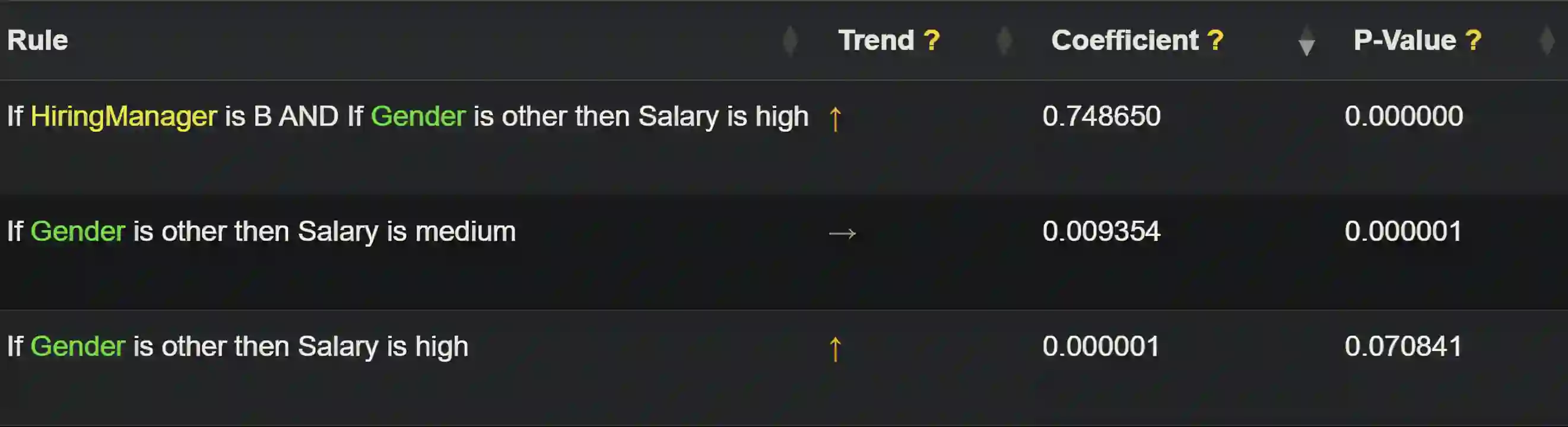
Artificial intelligence models trained from data can only be as good as the underlying data is. Biases in training data propagating through to the output of a machine learning model are a well-documented and well-understood phenomenon, but the machinery to prevent these undesired effects is much less developed. Efforts to ensure data is clean during collection, such as using bias-aware sampling, are most effective when the entity controlling data collection also trains the AI. In cases where the data is already available, how do we find out if the data was already manipulated, i.e., ``poisoned'', so that an undesired behavior would be trained into a machine learning model? This is a challenge fundamentally different to (just) improving approximation accuracy or efficiency, and we provide a method to test training data for flaws, to establish a trustworthy ground-truth for a subsequent training of machine learning models (of any kind). Unlike the well-studied problem of approximating data using fuzzy rules that are generated from the data, our method hinges on a prior definition of rules to happen before seeing the data to be tested. Therefore, the proposed method can also discover hidden error patterns, which may also have substantial influence. Our approach extends the abilities of conventional statistical testing by letting the ``test-condition'' be any Boolean condition to describe a pattern in the data, whose presence we wish to determine. The method puts fuzzy inference into a regression model, to get the best of the two: explainability from fuzzy logic with statistical properties and diagnostics from the regression, and finally also being applicable to ``small data'', hence not requiring large datasets as deep learning methods do. We provide an open source implementation for demonstration and experiments.
翻译:通过数据训练的人工智能模型,其性能上限取决于底层数据的质量。训练数据中的偏差传递至机器学习模型输出是一种已被充分记录和理解的现象,但防止这些不良影响的机制却远未成熟。在数据收集阶段确保数据清洁的措施(如采用偏差感知采样)通常在数据收集方同时负责AI训练时最为有效。当数据已预先存在时,我们如何判断数据是否已被操纵(即“投毒”),从而导致机器学习模型习得非期望行为?这一挑战本质上不同于(单纯)提升近似精度或效率,我们提出了一种检测训练数据缺陷的方法,旨在为后续机器学习模型(任何类型)的训练建立可信的基础事实。与从数据生成模糊规则以近似数据的经典问题不同,我们的方法依赖于在观测待测数据之前预先定义规则。因此,所提方法还能发现可能产生重大影响的隐藏误差模式。本方法通过允许“测试条件”为描述数据中特定模式的任意布尔条件(其存在性需被判定),扩展了传统统计测试的能力。该方法将模糊推理融入回归模型,从而融合二者优势:既获得模糊逻辑的可解释性,又兼具回归的统计特性与诊断能力,最终还能适用于“小数据”场景,无需像深度学习方法那样依赖大规模数据集。我们提供了开源实现以供演示和实验验证。