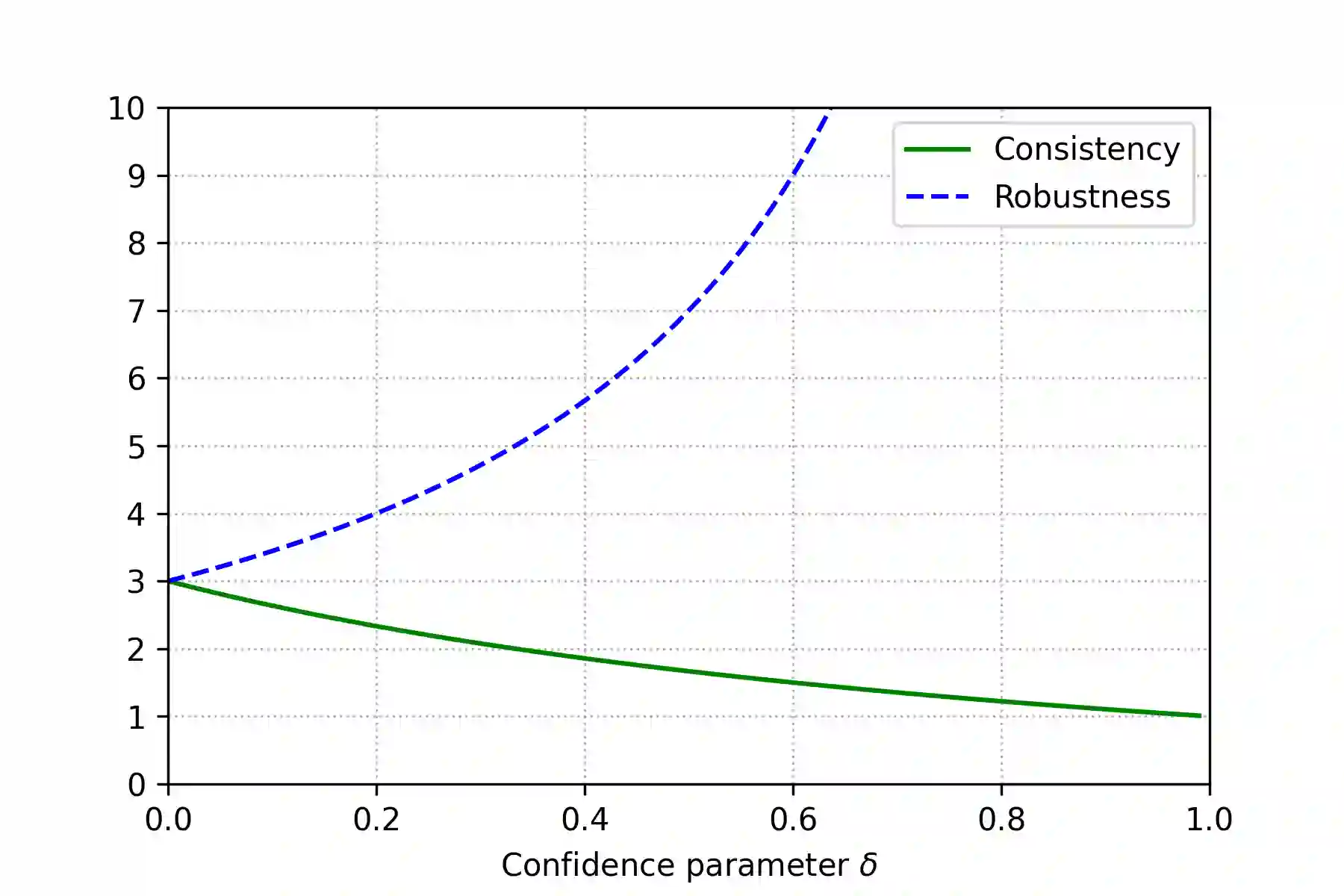
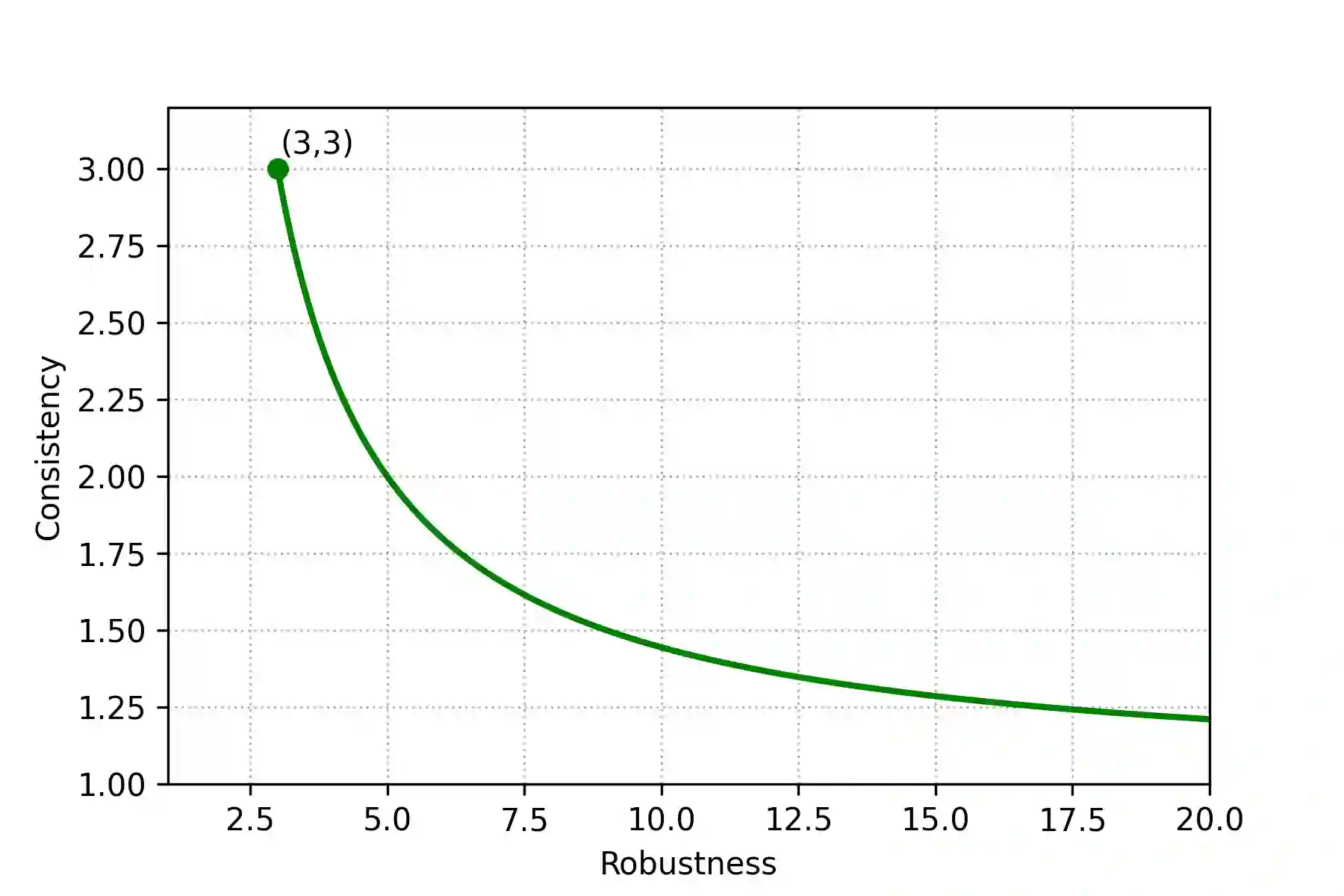
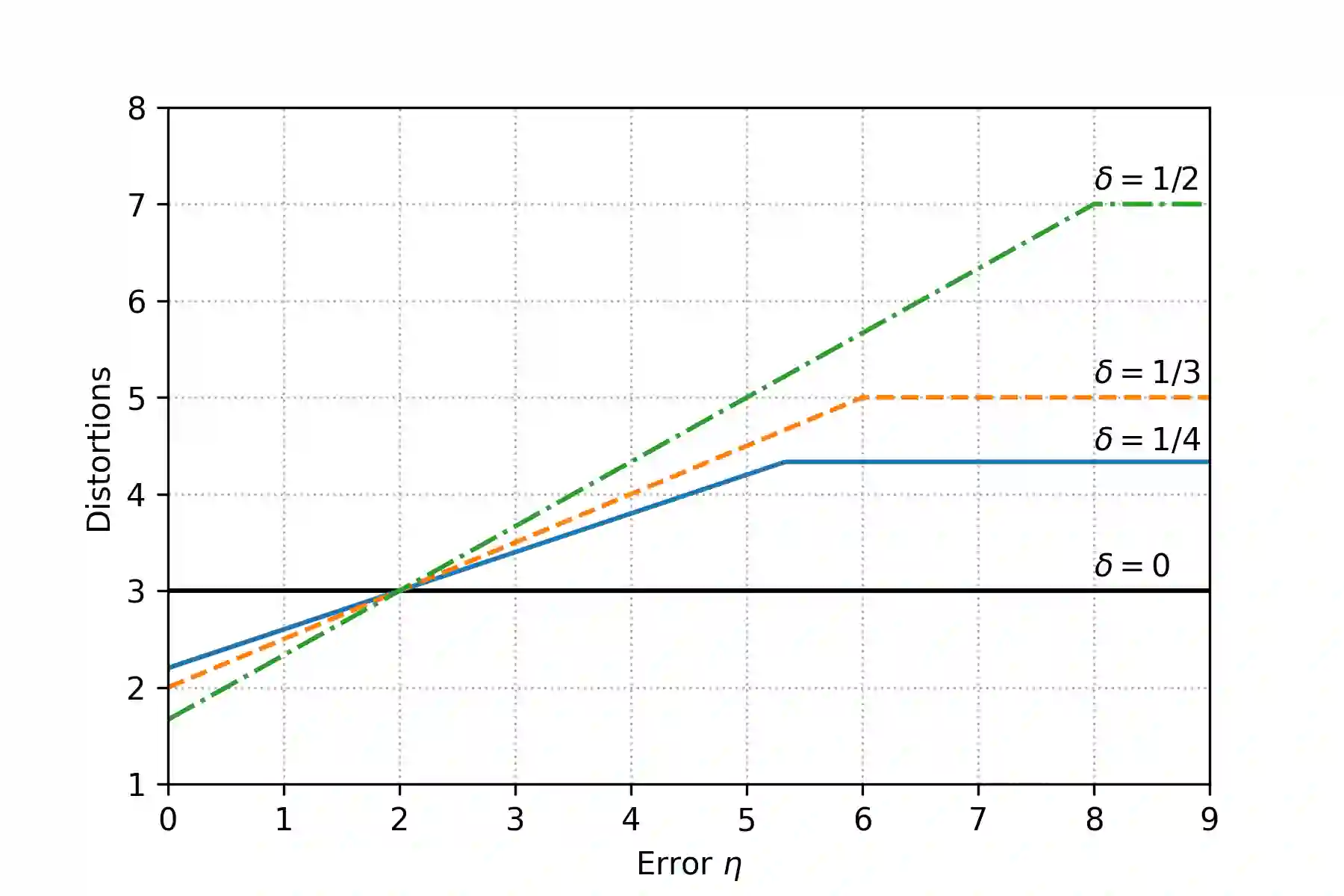
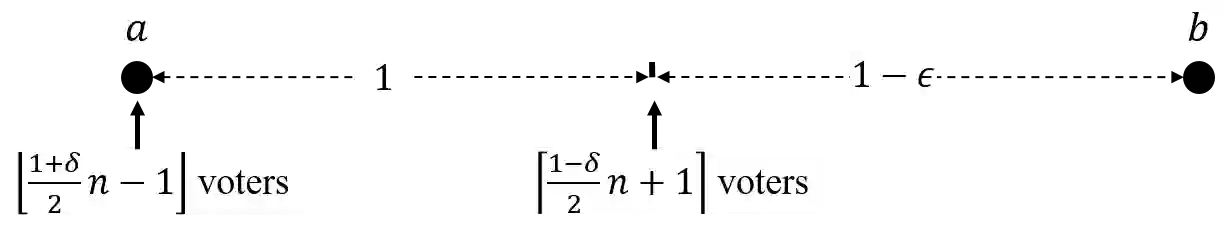In the metric distortion problem there is a set of candidates $C$ and voters $V$ in the same metric space. The goal is to select a candidate minimizing the social cost: the sum of distances of the selected candidate from all the voters, and the challenge arises from the algorithm receiving only ordinaL input: each voter's ranking of candidate, while the objective function is cardinal, determined by the underlying metric. The distortion of an algorithm is its worst-case approximation factor of the optimal social cost. A key concept here is the (p,q)-veto core, with $p\in \Delta(V)$ and $q\in \Delta(C)$ being normalized weight vectors representing voters' veto power and candidates' support, respectively. The (p,q)-veto core corresponds to a set of winners from a specific class of deterministic algorithms. Notably, the optimal distortion of $3$ is obtained from this class, by selecting veto core candidates using uniform $p$ and $q$ proportional to candidates' plurality scores. Bounding the distortion of other algorithms from this class is an open problem. Our contribution is twofold. First, we establish upper bounds on the distortion of candidates from the (p,q)-veto core for arbitrary weight vectors $p$ and $q$. Second, we revisit the metric distortion problem through the \emph{learning-augmented} framework, which equips the algorithm with a (machine-learned) prediction regarding the optimal candidate. The quality of this prediction is unknown, and the goal is to optimize the algorithm's performance under accurate predictions (consistency), while simultaneously providing worst-case guarantees under arbitrarily inaccurate predictions (robustness). We propose an algorithm that chooses candidates from the (p,q)-veto core, using a prediction-guided q vector and, leveraging our distortion bounds, we prove that this algorithm achieves the optimal robustness-consistency trade-off.
翻译:在度量失真问题中,候选者集合$C$与投票者集合$V$位于同一度量空间。目标是选择一个最小化社会成本的候选者:即所选候选者到所有投票者距离的总和,而挑战在于算法仅接收序数输入:每个投票者对候选者的排序,但目标函数却是基于底层度量的基数函数。算法的失真度是其最坏情况下相对于最优社会成本的近似比。此处的核心概念是$(p,q)$-否决核心,其中$p\in \Delta(V)$和$q\in \Delta(C)$是归一化的权重向量,分别代表投票者的否决权与候选者的支持度。$(p,q)$-否决核心对应于一类特定确定性算法产生的获胜者集合。值得注意的是,通过使用均匀的$p$和与候选者得票数成比例的$q$来选择否决核心候选者,可以从该类算法中获得最优失真度$3$。对该类其他算法的失真度进行界定是一个开放问题。我们的贡献是双重的。首先,我们为任意权重向量$p$和$q$下的$(p,q)$-否决核心候选者的失真度建立了上界。其次,我们通过\emph{学习增强}框架重新审视度量失真问题,该框架为算法提供了关于最优候选者的(机器学习)预测。此预测的质量未知,目标是在预测准确时优化算法性能(一致性),同时在预测任意不准确时提供最坏情况保证(鲁棒性)。我们提出一种从$(p,q)$-否决核心中选择候选者的算法,该算法使用预测引导的$q$向量,并利用我们的失真度界证明该算法达到了最优的鲁棒性-一致性权衡。