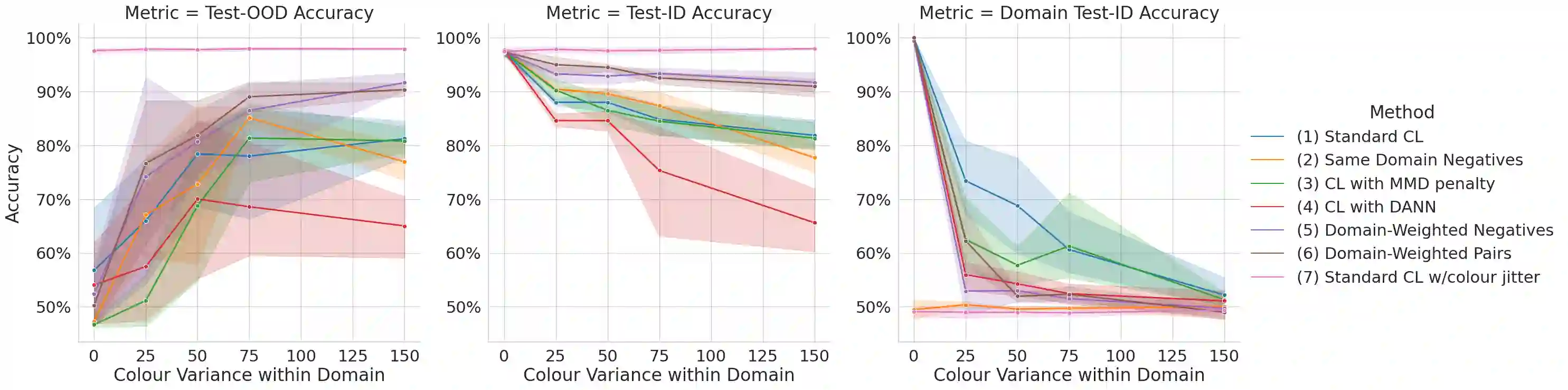
Self-supervised pre-training with contrastive learning is a powerful method for learning from sparsely labeled data. However, performance can drop considerably when there is a shift in the distribution of data from training to test time. We study this phenomenon in a setting in which the training data come from multiple domains, and the test data come from a domain not seen at training that is subject to significant covariate shift. We present a new method for contrastive learning that incorporates domain labels to increase the domain invariance of learned representations, leading to improved out-of-distribution generalization. Our method adjusts the temperature parameter in the InfoNCE loss -- which controls the relative weighting of negative pairs -- using the probability that a negative sample comes from the same domain as the anchor. This upweights pairs from more similar domains, encouraging the model to discriminate samples based on domain-invariant attributes. Through experiments on a variant of the MNIST dataset, we demonstrate that our method yields better out-of-distribution performance than domain generalization baselines. Furthermore, our method maintains strong in-distribution task performance, substantially outperforming baselines on this measure.
翻译:利用对比学习的自监督预训练是一种从稀疏标注数据中学习的有效方法。然而,当数据分布从训练到测试阶段发生偏移时,其性能可能显著下降。我们在训练数据来自多个领域、测试数据来自训练时未见且存在显著协变量偏移的领域这一设定下研究此现象。本文提出一种新的对比学习方法,通过引入领域标签来增强学习表征的领域不变性,从而提升分布外泛化能力。该方法利用负样本与锚点样本来自同一领域的概率,动态调整InfoNCE损失中的温度参数——该参数控制负样本对的相对权重。通过提升来自更相似领域的样本对权重,促使模型基于领域不变属性进行样本区分。通过在MNIST数据集变体上的实验,我们证明该方法相比领域泛化基线具有更优的分布外性能。此外,该方法保持了强大的分布内任务性能,在此指标上显著优于基线方法。