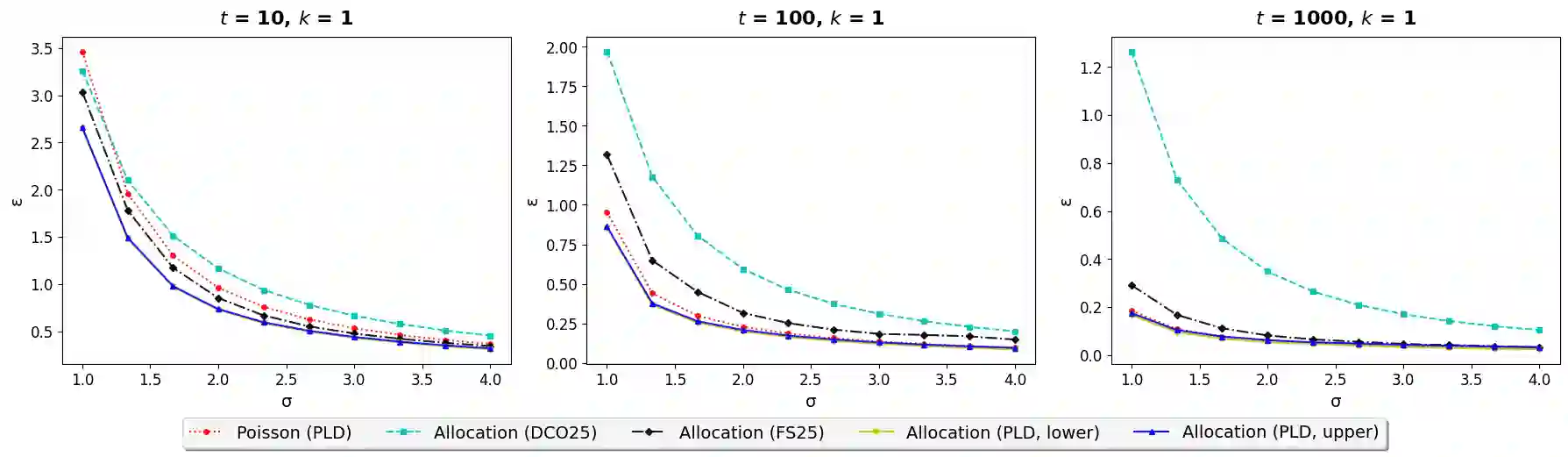
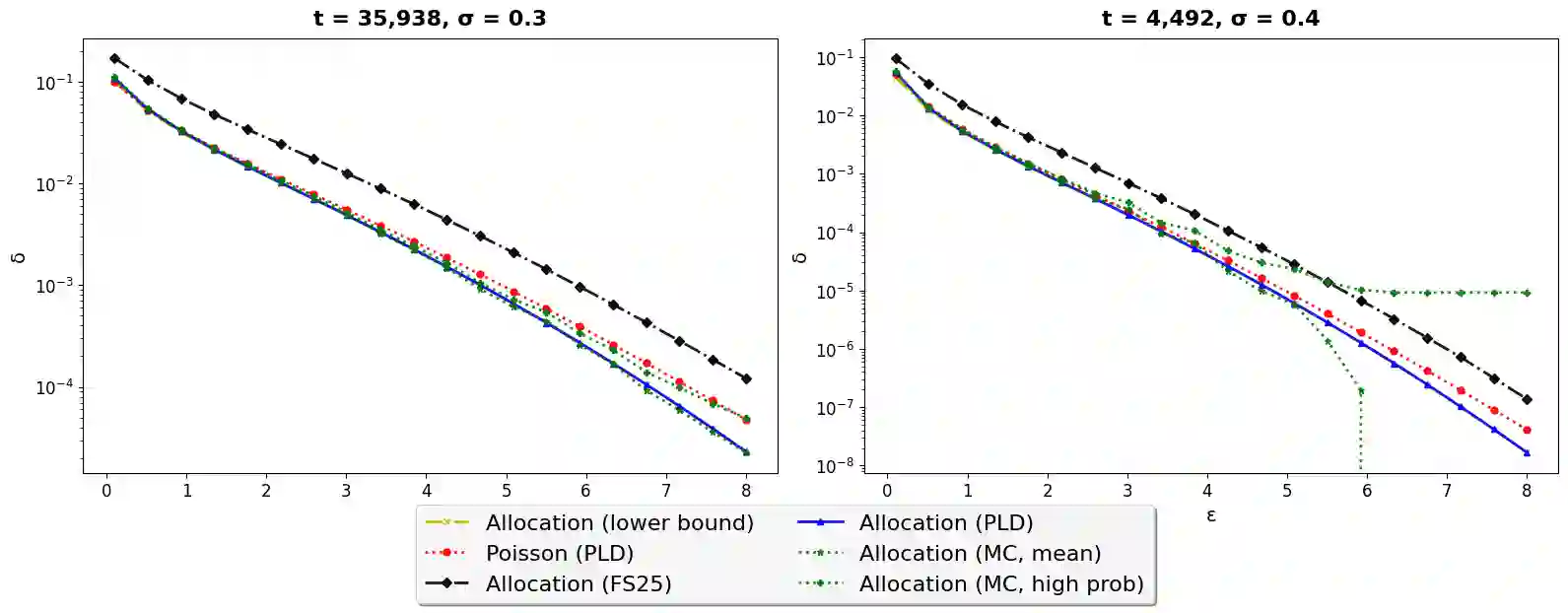
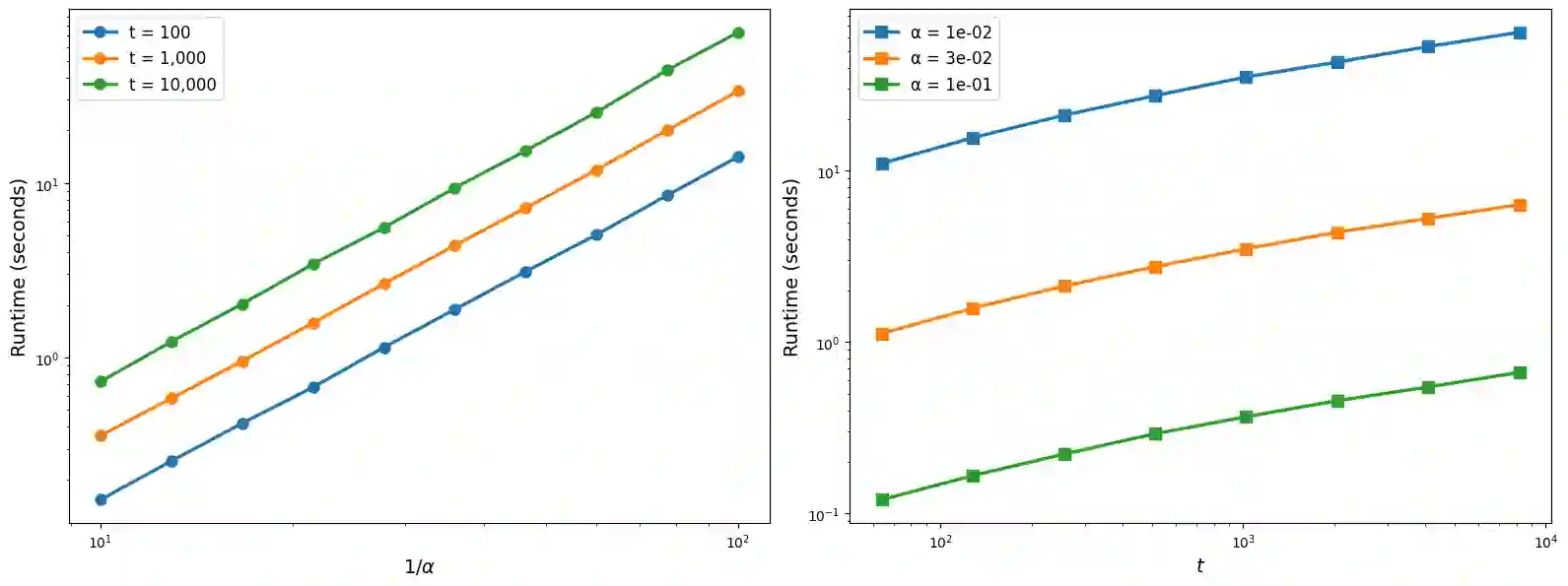
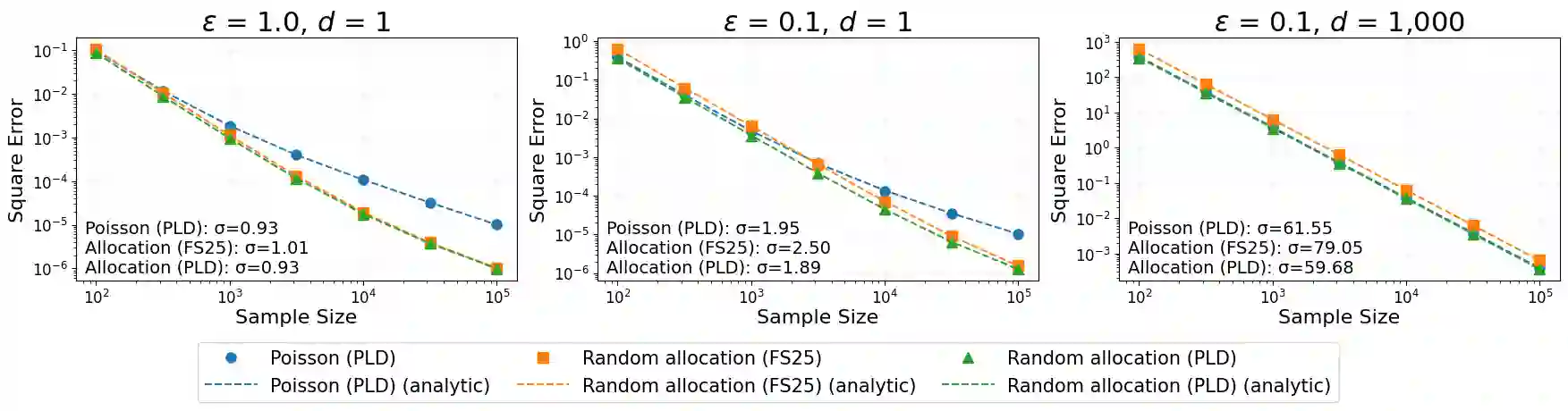
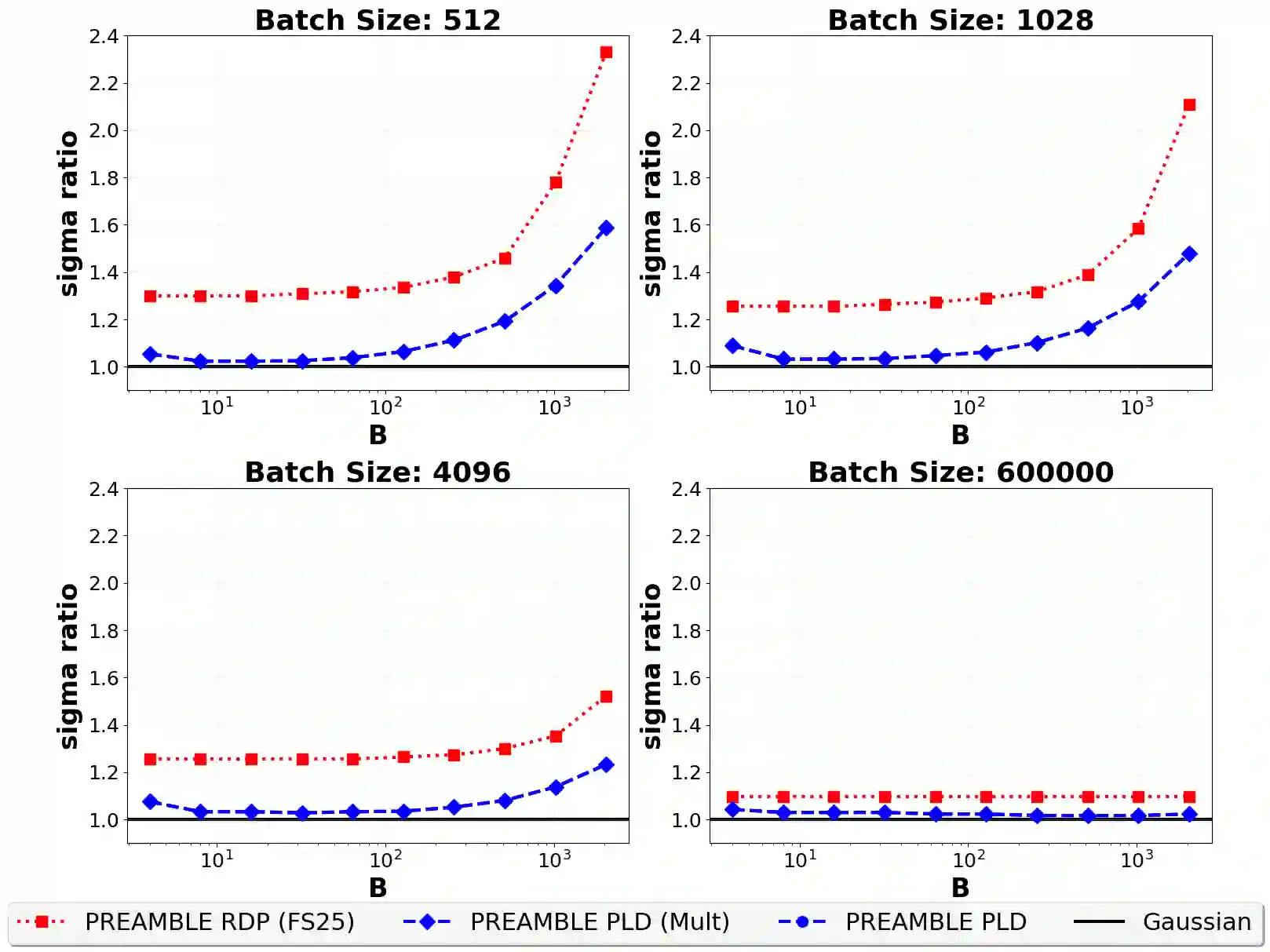
We consider the privacy amplification properties of a sampling scheme in which a user's data is used in $k$ steps chosen randomly and uniformly from a sequence (or set) of $t$ steps. This sampling scheme has been recently applied in the context of differentially private optimization (Chua et al., 2024a; Choquette-Choo et al., 2025) and communication-efficient high-dimensional private aggregation (Asi et al., 2025), where it was shown to have utility advantages over the standard Poisson sampling. Theoretical analyses of this sampling scheme (Feldman & Shenfeld, 2025; Dong et al., 2025) lead to bounds that are close to those of Poisson sampling, yet still have two significant shortcomings. First, in many practical settings, the resulting privacy parameters are not tight due to the approximation steps in the analysis. Second, the computed parameters are either the hockey stick or Renyi divergence, both of which introduce overheads when used in privacy loss accounting. In this work, we demonstrate that the privacy loss distribution (PLD) of random allocation applied to any differentially private algorithm can be computed efficiently. When applied to the Gaussian mechanism, our results demonstrate that the privacy-utility trade-off for random allocation is at least as good as that of Poisson subsampling. In particular, random allocation is better suited for training via DP-SGD. To support these computations, our work develops new tools for general privacy loss accounting based on a notion of PLD realization. This notion allows us to extend accurate privacy loss accounting to subsampling which previously required manual noise-mechanism-specific analysis.
翻译:我们研究一种采样方案的隐私放大特性,该方案中用户数据被用于从$t$步序列(或集合)中随机均匀选取的$k$步。该采样方案近期已被应用于差分隐私优化(Chua等人,2024a;Choquette-Choo等人,2025)和通信高效的高维隐私聚合(Asi等人,2025)领域,其效用优势相较于标准泊松采样已得到验证。针对该采样方案的理论分析(Feldman & Shenfeld,2025;Dong等人,2025)得出的边界虽接近泊松采样,但仍存在两个显著缺陷:首先,在实际应用中,由于分析过程中的近似处理,所得隐私参数往往不够紧致;其次,计算所得参数无论是曲棍球散度还是Renyi散度,在隐私损失核算中都会引入额外开销。本研究证明,应用于任意差分隐私算法的随机分配机制,其隐私损失分布均可被高效计算。当应用于高斯机制时,我们的结果表明随机分配的隐私-效用权衡至少与泊松子采样相当。特别地,随机分配更适用于通过DP-SGD进行训练。为支持这些计算,本研究基于隐私损失分布实现的概念,开发了通用隐私损失核算的新工具。该概念使我们能够将精确的隐私损失核算扩展到子采样领域,而此前这类分析需要针对具体噪声机制进行人工设计。