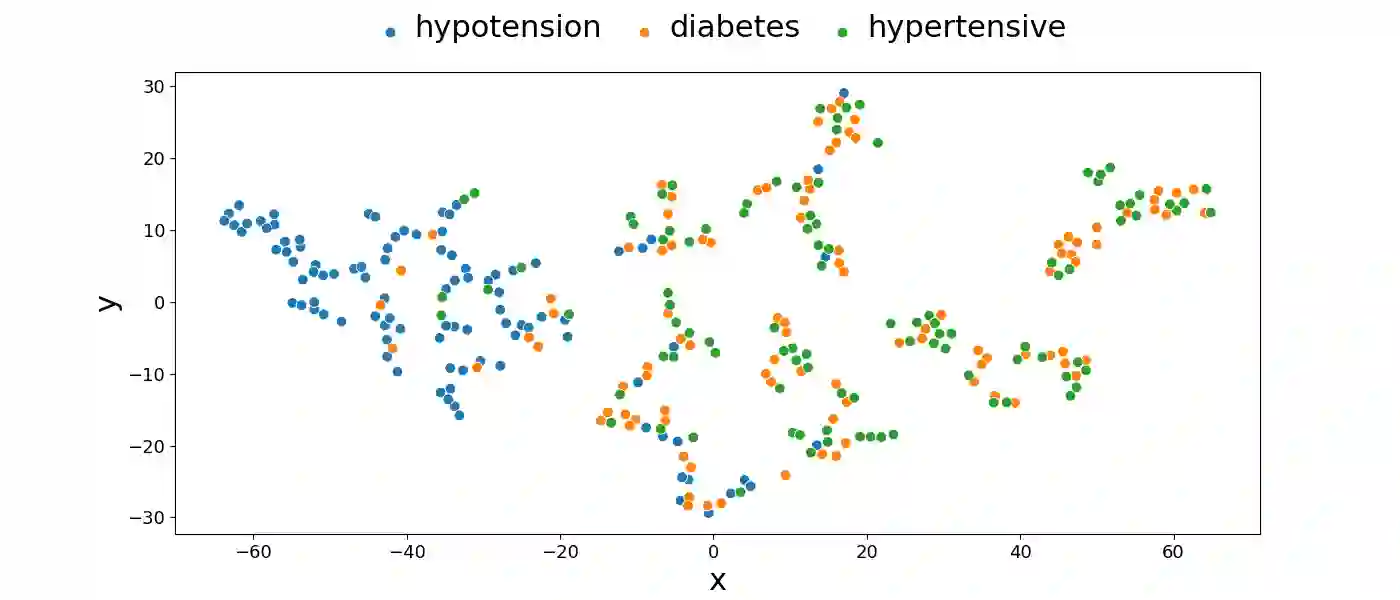
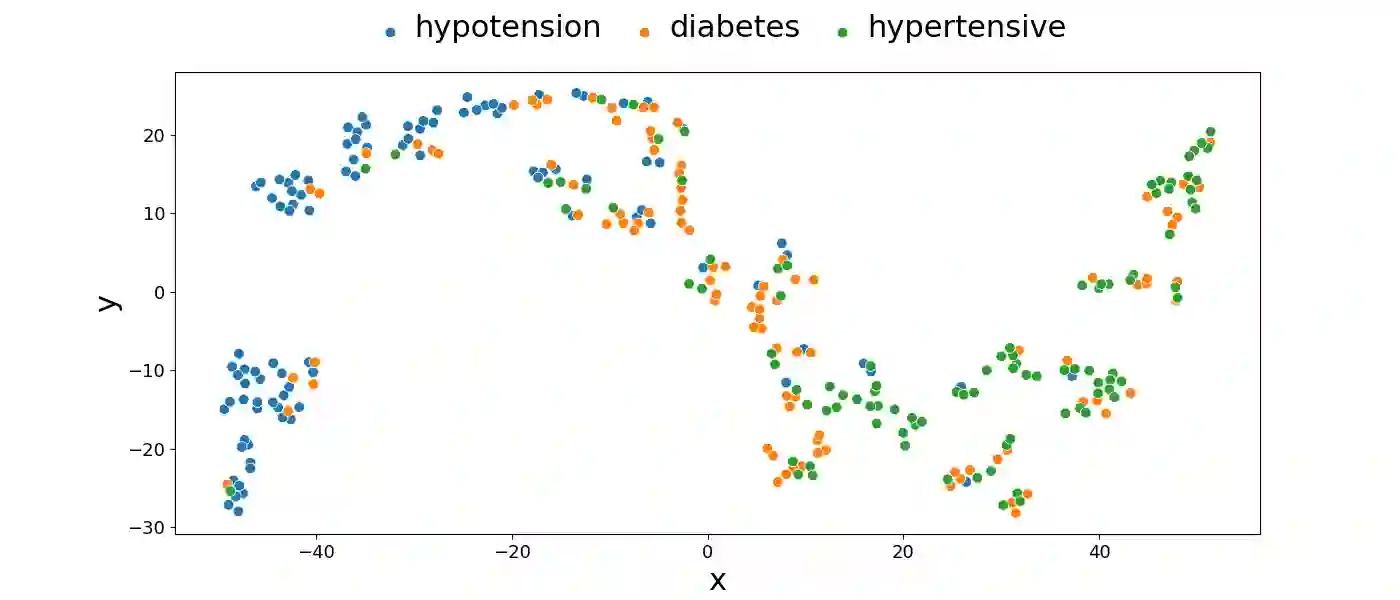
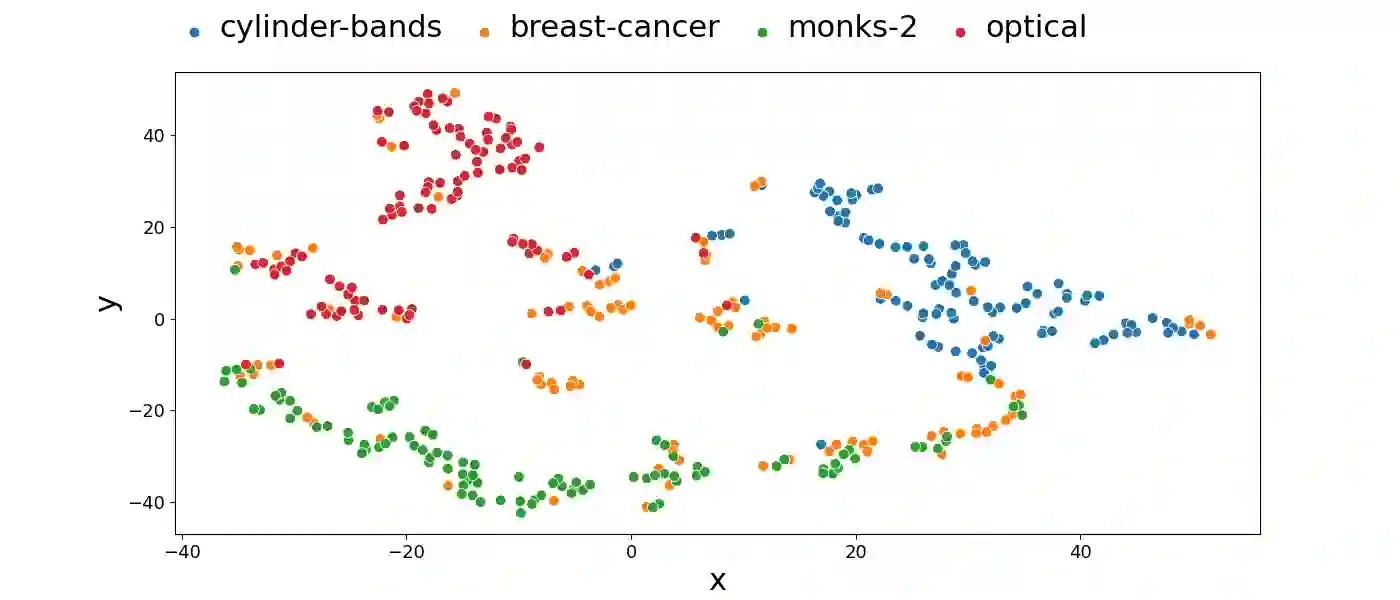
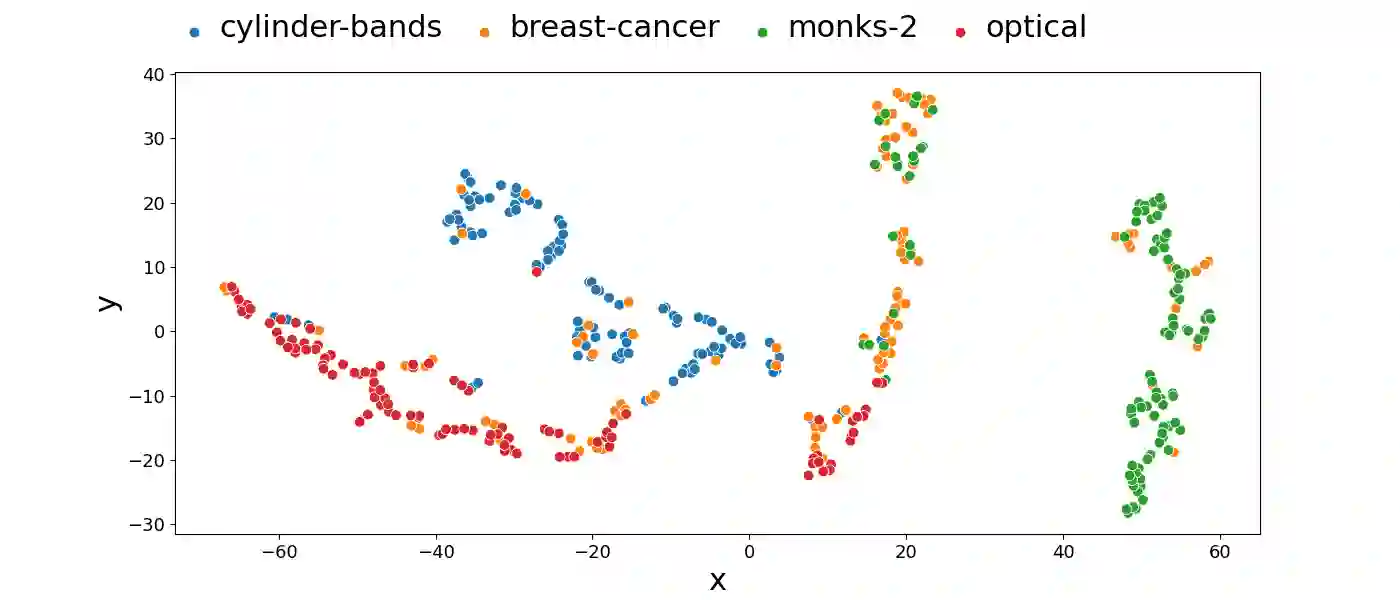
Effectively representing heterogeneous tabular datasets for meta-learning remains an open problem. Previous approaches rely on predefined meta-features, for example, statistical measures or landmarkers. Encoder-based models, such as Dataset2Vec, allow us to extract significant meta-features automatically without human intervention. This research introduces a novel encoder-based representation of tabular datasets implemented within the liltab package available on GitHub https://github.com/azoz01/liltab. Our package is based on an established model for heterogeneous tabular data proposed in [Iwata and Kumagai, 2020]. The proposed approach employs a different model for encoding feature relationships, generating alternative representations compared to existing methods like Dataset2Vec. Both of them leverage the fundamental assumption of dataset similarity learning. In this work, we evaluate Dataset2Vec and liltab on two common meta-tasks - representing entire datasets and hyperparameter optimization warm-start. However, validation on an independent metaMIMIC dataset highlights the nuanced challenges in representation learning. We show that general representations may not suffice for some meta-tasks where requirements are not explicitly considered during extraction. [Iwata and Kumagai, 2020] Tomoharu Iwata and Atsutoshi Kumagai. Meta-learning from Tasks with Heterogeneous Attribute Spaces. In Advances in Neural Information Processing Systems, 2020.
翻译:有效表示异构表格数据集以进行元学习仍是一个开放性问题。现有方法依赖预定义的元特征,例如统计量或标记器。基于编码器的模型(如Dataset2Vec)能够自动提取重要元特征,无需人工干预。本研究提出了一种新颖的基于编码器的表格数据集表示方法,并在GitHub上的liltab软件包(https://github.com/azoz01/liltab)中实现。我们的软件包基于Iwata和Kumagai(2020)提出的异构表格数据模型。该方法采用不同的编码模型对特征关系进行编码,与Dataset2Vec等现有方法相比生成了替代性表示。两种方法均利用了数据集相似性学习的基本假设。在本工作中,我们在两个常见元任务(整体数据集表示和超参数优化冷启动)上评估了Dataset2Vec和liltab。然而,在独立元MIMIC数据集上的验证揭示了表示学习中的细微挑战。我们表明,对于某些在提取过程中未明确考虑要求的元任务,通用表示可能不足。[Iwata and Kumagai, 2020] Tomoharu Iwata and Atsutoshi Kumagai. 基于异构属性空间任务的元学习。收录于《神经信息处理系统进展》,2020年。