
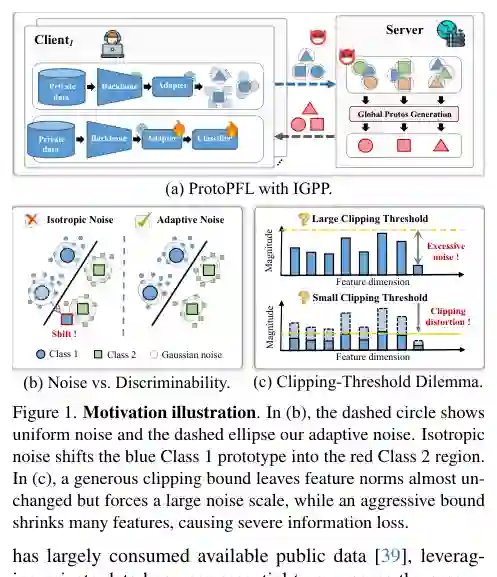
在联邦学习场景中,如何让不同客户端在保护本地数据隐私的同时,高效地完成个性化模型微调,一直是核心难题。基于原型的个性化联邦学习(ProtoPFL)通过交换紧凑的类原型实现多域适应,但直接共享原型会带来严重的隐私泄露风险。常见的防御方案——各向同性高斯原型扰动(IGPP)虽然能提供局部差分隐私(LDP)保证,却会盲目地过度扰动最具判别性的特征维度,导致分类性能严重下降。
来自北京航空航天大学等研究者,在本篇被CVPR 2026接收为Highlight的论文中,提出了VPDR(Variance-adaptive Prototype Perturbation and Distillation-guided Clipping Regularization)。这是一款轻量级客户端隐私插件,能够无缝集成到现有的ProtoPFL框架中。VPDR的核心创新在于:不再是“一刀切”地给所有特征维度加等同噪声,而是根据维度方差区分判别性高低,将隐私预算“明智地”分配到关键子空间。同时,它通过知识蒸馏引导特征范数自适应集中于裁剪阈值附近,从而同时解决噪声与判别性不匹配以及裁剪阈值困境这两大痛点。
这篇论文理论分析和实验并重,不仅在多个多域基准上取得了更优的隐私-效用权衡,而且对成员推理和重构攻击表现出接近随机的鲁棒性。对于关注联邦学习、差分隐私以及计算机视觉隐私保护的研究者和从业者而言,这是一篇不可多得的佳作,值得深入精读。
论文基本信息
英文题目 Taming Noise-Induced Prototype Degradation for Privacy-Preserving Personalized Federated Fine-Tuning 作者 Yuhua Wang, Qinnan Zhang, Xiaodong Li, Huan Zhang, Yifan Sun, Wangjie Qiu, Hainan Zhang, Yongxin Tong, Zhiming Zheng arXiv ID 2604.27833 类别 cs.CV, cs.LG Comments/接收信息 Accepted by CVPR 2026 (Highlight) 原文链接 http://arxiv.org/abs/2604.27833v1
摘要
原型个性化联邦学习通过交换紧凑类原型实现了高效的多域适应,但直接共享原型存在隐私风险。常见的防御方法——各向同性高斯原型扰动(IGPP)——过度扰动判别维度,且难以平衡裁剪阈值与表示保真度。 本文提出VPDR(Variance-adaptive Prototype Perturbation and Distillation-guided Clipping Regularization),包含两个核心模块:
- 方差自适应原型扰动(VPP):根据维度方差分配噪声,保护判别子空间,有效防止判别信息被过多噪声掩盖。
- 蒸馏引导裁剪正则化(DCR):通过特征软裁剪和知识蒸馏,保持预裁剪和后裁剪特征之间的预测一致性,从而缓解裁剪带来的信息损失。
理论分析表明,在相同隐私约束下,VPDR的组间机制能提供不弱于各向同性基线的隐私保证。在多个多域基准上的实验表明,VPDR在个性化联邦微调中取得了更优的隐私-效用权衡,且对实际攻击具有鲁棒性。
引言:论文要解决什么问题
这篇论文瞄准的是主流原型个性化联邦学习(ProtoPFL)中的两个核心痛点。 首先,IGPP的噪声与判别性不匹配:在原型个性化联邦学习中,客户端需要将本地数据的特征编码为类原型(通常为类均值)并上传至服务器。为了提供局部差分隐私(LDP)保证,一种标准做法是IGPP,即先对每个样本特征进行ℓ2裁剪以限制敏感度,然后向原型注入各向同性高斯噪声。然而,不同特征维度对分类任务的贡献差异很大:有些维度包含关键的判别性信息,另一些则相对冗余。各向同性高斯噪声“一视同仁”地污染所有维度,导致最具信息量的维度被过度扰动,类可分离性急剧下降。正如图1(b)所示,过大的均匀噪声甚至会将蓝色类别的原型推向红色类别区域,造成严重误分类。 其次,ℓ2裁剪阈值困境:原型的尺度因类别和域而异。一个较大的裁剪阈值可以减少裁剪带来的特征失真,但代价是需要注入大量的高斯噪声来满足隐私预算。反之,一个较小的阈值会迫使大量特征被过度收缩,不可挽回地擦除语义内容。图1(c)清晰地展示了这种两难:宽松的裁剪虽然保留了特征范数,但伴随巨大的噪声;严格的裁剪虽然噪声小,却导致了严重的特征变形。这种困境使得在隐私和效用之间找到平衡非常困难。 针对上述问题,本文提出VPDR。针对第一个痛点,VPP通过计算维度间类方差的判别性分数,私密地选择一个判别性子空间,然后对每个嵌入进行组裁剪,并为不同的“组”(即判别性高与低的维度组)注入不同程度的噪声,从而将隐私预算更合理地分配给任务相关坐标。针对第二个痛点,DCR在本地编码器后附加一个可微软裁剪层,并通过知识蒸馏强制预裁剪与后裁剪特征之间保持预测一致性,从而引导特征范数集中于裁剪阈值附近,有效降低信息损失。
配图:问题背景
方法:核心思路与技术路线
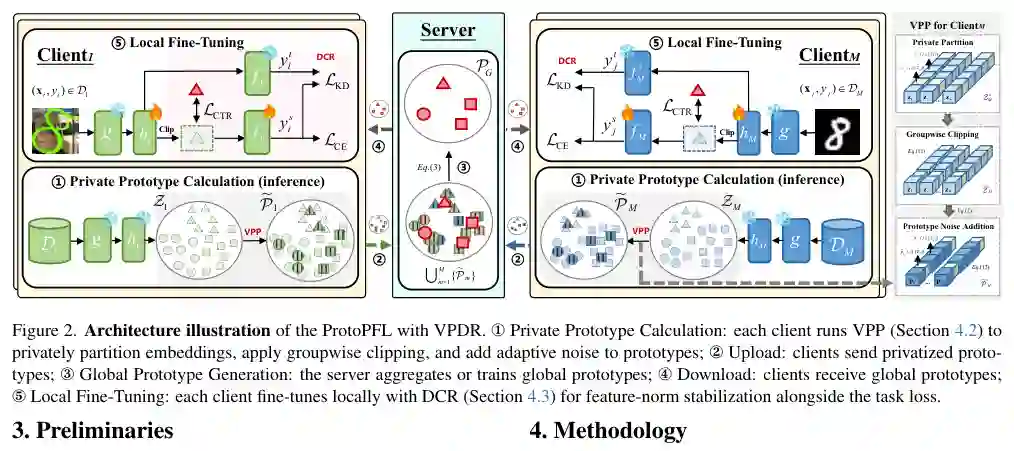
VPDR是一个客户端侧隐私插件,可以无缝集成到任何ProtoPFL框架中,如FedProto、FedAP等。它由两个模块组成:方差自适应原型扰动(VPP)和蒸馏引导裁剪正则化(DCR)。
1. 方差自适应原型扰动(VPP)
VPP的核心理念是“好钢用在刀刃上”。它不盲目地对所有特征维度施加相同强度的噪声,而是根据每个维度的判别性强弱来自适应地分配噪声。
- 判别性分数计算 首先,客户端利用本地样本的嵌入,计算每个维度的“类内方差”和“类间方差”。直观上,如果一个维度在同类样本间差异小(类内方差小),而在不同类样本间差异大(类间方差大),那么这个维度就具有很强的判别性。通过某种比例(例如类间方差与类内方差的比值),可以得出每个维度的判别性分数。
- 子空间选择 基于这些判别性分数,客户端可以私密地“选择”一个由高判别性维度构成的子空间。由于选择过程本身可能泄露信息,该步骤需要设计为差分隐私敏感的。通常采用一种基于Laplace机制的Top-(k)选择方法,只暴露判别性最强的(k)个维度的索引。
- 组裁剪和组噪声注入 选定子空间后,客户端对每个样本的嵌入执行“组级别”的ℓ2裁剪:即对判别性子空间的嵌入部分和非判别性子空间的嵌入部分分别进行裁剪,并计算出对应的“组原型”。最后,对这两个组原型注入不同方差的各向异性高斯噪声:判别性子空间的原型注入较少噪声(因为要保护判别信息),而非判别性子空间的原型注入较多噪声。这样就将隐私预算更多地分配给了判别性区域,在同等隐私约束下提升了表示质量。
2. 蒸馏引导裁剪正则化(DCR)
DCR旨在解决ℓ2裁剪阈值带来的两难困境。它改变了传统离线裁剪(即先裁剪再学习)的方式,而是让裁剪过程本身变成可学习的,并引导模型自适应地将特征范数调整到裁剪阈值附近。
- 可微软裁剪层 在本地编码器(Encoder)之后,附加一个可学习参数的“软裁剪层”。这个裁剪层的输出值不再是生硬的截断,而是根据输入特征范数,通过可微分的函数(如sigmoid函数的变体)将范数压缩到预设的阈值附近。由于是可微的,可以直接用梯度下降进行训练。
- 知识蒸馏损失 DCR的核心是引入一个知识蒸馏损失。具体地,作者设计了一个结构:将原始编码器产生的“预裁剪”特征输入一个分类头(称为“教师头”),将经过软裁剪后的“后裁剪”特征输入另一个分类头(称为“学生头”)。然后,计算这两个分类头输出的预测概率之间的KL散度,并作为额外的正则化项添加到总损失函数中。这个损失强制模型在学习过程中,确保“裁剪”操作不会改变模型的预测结果。
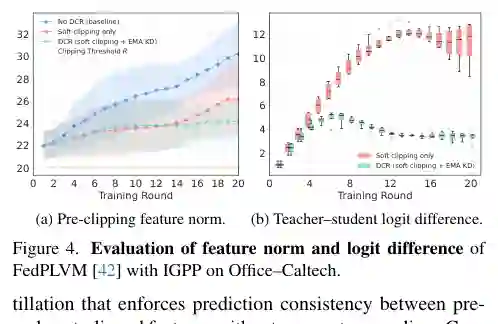
- 作用机理 传统的ℓ2裁剪会通过降低特征范数来“隐藏”过大范数,但模型会通过放大后续权重来补偿,形成“范数-权重补偿”捷径。DCR通过保持预测一致性,打破了这种捷径,迫使模型真正学会如何在不损失语义信息的情况下,将特征范数集中到裁剪阈值附近。这样,即使在严格的隐私预算下,裁剪带来的信息损失也会显著减少。
VPDR的整体流程可以总结为:在每个通信轮次中,客户端首先使用本地数据更新编码器和头部,期间DCR损失会引导编码器输出范数紧凑的特征。然后,在原型计算阶段(ProtoGen),客户端使用VPP模块,根据特征维度的判别性,在子空间上分配不同的噪声,生成并上传带噪的原型。服务器聚合这些带噪原型后下发,用于下一轮训练。
配图:方法结构
实验:设置、指标与结果
原文未明确说明实验设置细节,但提供了详实的主要实验结果与分析。
主要结果
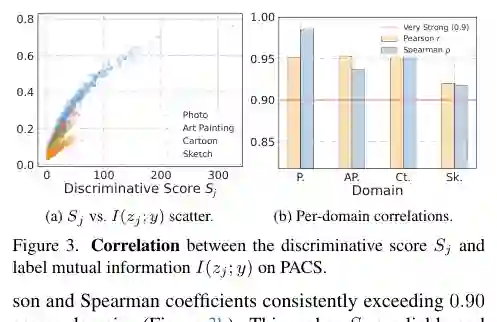
- 更优的隐私-效用权衡:在固定的隐私预算(例如小ε值)下,VPDR在所有测试的ProtoPFL框架(FedProto、FedAP等)和多域基准(如Office-Caltech, PACS, DomainNet)上,均显著优于使用IGPP的基线。具体的性能指标包括分类精度,VPDR能够以更低的隐私代价实现更高的平均精度。
- 对标签偏移的鲁棒性:实验直接测试了在存在严重标签偏移(即不同客户端拥有不同类别的样本)的情况下,VPDR仍然能够保持鲁棒性,性能下降远小于IGPP。
- 计算开销极低:VPDR没有增加任何通信成本(因为传输的仍然是原型)。在计算开销方面,以FedProto在Office-Caltech数据集上的运行为例:
- 原型生成阶段(ProtoGen) VPDR引入的额外开销为2.2%。具体来说,Base阶段(原型计算)花费1057ms,附加的VPP步骤(包括方差统计13.22ms和Top-k选择9.78ms)总共花费23.00ms。
- 微调阶段(FT) VPDR引入的额外开销仅为0.2%。Base阶段花费2055ms,附加的DCR步骤(包括软裁剪1.58ms、教师头前向1.59ms、KL散度计算1.38ms)总共花费4.55ms。整体而言,VPDR带来的精度提升是显著的,而计算开销是完全可以接受的。
- 抵御实际隐私攻击的能力:为了验证隐私保护的有效性,论文评估了两种实际攻击:成员推理攻击(判断某样本是否在训练集中)和重构攻击(尝试从原型中重建出原始样本)。实验结果表明,无论隐私预算如何,使用VPDR的模型在两种攻击下的攻击者正确率都接近随机猜测(即50%或更低概率)。这表明VPDR提供的隐私保障是实质性的,攻击者几乎无法从带噪原型中推断出任何有用的信息。
配图:实验结果
结论:贡献、局限与启发
贡献总结
本文提出VPDR,一个用于隐私保护原型个性化联邦学习的客户端侧插件。其核心贡献如下:
- 创新方法:提出方差自适应原型扰动(VPP),根据特征维度的判别性分配噪声,保护判别子空间,缓解噪声与判别性不匹配问题。同时,提出蒸馏引导裁剪正则化(DCR),通过软裁剪和知识蒸馏来解决ℓ2裁剪阈值困境,减少信息损失。
- 理论保证:理论分析表明,VPDR的组间机制(对判别性和非判别性子空间注入不同噪声)在相同的隐私约束(相同的ε)下,能够提供不弱于各向同性扰动(IGPP)的LDP保证。
- 实验验证:在多种ProtoPFL框架和多域基准上,VPDR在固定隐私预算下实现了更高效用,对标签偏移鲁棒,且仅增加了极低的计算开销。对抗成员推理和重构攻击时,表现出接近随机的性能,表明其强大的保护能力。
局限性
原文未明确说明。
启发
- 方法普适性 VPDR的设计思想——即利用数据结构特性(维度方差)来引导隐私预算分配,具有通用性。它不仅可以用于原型扰动,也可能启发其他差分隐私应用中的噪声生成策略,如梯度扰动或模型扰动。
- 裁剪机制改进 DCR通过知识蒸馏将裁剪学习过程融入模型训练,是一种优雅地解决非可微裁剪问题的方法。这种“将不可微操作变为可微”的思路,对许多类似的预处理步骤(如量化、剪枝)具有借鉴意义。
- 未来方向 虽然当前论文未提,但VPDR的潜力可能不仅限于图像域。它可以拓展到自然语言处理、图联邦学习等任务中,只要存在特征维度的判别性差异。
原文信息
Taming Noise-Induced Prototype Degradation for Privacy-Preserving Personalized Federated Fine-Tuning
Yuhua Wang, Qinnan Zhang, Xiaodong Li, Huan Zhang, Yifan Sun, Wangjie Qiu, Hainan Zhang, Yongxin Tong, Zhiming Zheng arXiv:2604.27833, Accepted by CVPR 2026 (Highlight) 原文链接:http://arxiv.org/abs/2604.27833v1
