
在现代3D场景重建领域,3D高斯泼溅(3D Gaussian Splatting)等方法已实现实时、逼真的新视点合成,但其输出的非结构化基元(通常是数百万个高斯原语)缺乏语义理解,导致下游交互式图形应用(如对象编辑、移除和插入)难以直接使用。现有试图为这些模型添加语义分解的工作,如Gaussian Grouping和SAGA,常常面临分割质量不稳定、跨视角一致性差、以及因遮挡或标签冲突产生的伪影等痛点。这些问题的根源在于:点表示本身并非真正的体素化,基元内部存在未标记点,重叠基元导致语义歧义,且缺乏空间连通性信息。

针对上述难点,由Amr Sharafeldin等研究者提出的Semantic Foam(语义泡沫)提供了一种全新的空间与语义联合分解方案。该工作扩展了Radiant Foam的体素化Voronoi网格表示,在每个Voronoi单元上定义显式语义特征场,并利用网格提供的邻接图设计总变分损失,直接对相邻单元的特征进行空间正则化。这一设计使得模型能够有效抑制遮挡、不一致监督带来的伪影,实现干净、一致的对象级语义分割。实验证明,在三个复杂真实场景数据集上,Semantic Foam在对象级分割mIoU上比Gaussian Grouping和SAGA高出2%–6%,同时支持对象的提取、移除和插入等编辑操作。 本文值得细读的原因在于:它首次将Radiant Foam的体素Voronoi网格优势(本质体素化、显式邻接关系)系统应用到语义分解任务中,提出了一个兼具空间分解与语义分解的统一框架。其基于邻接图的总变分损失不仅解决了点表示中的常见伪影问题,还使模型能够自然地处理非凸对象和遮挡区域。对于从事3D场景理解、交互式图形学的研究者而言,这篇论文提供了一个结构清晰、可复现的基线,并且具备明确的编辑应用场景。
摘要
现代场景重建方法(如3D高斯泼溅)能实时生成逼真的新视点合成,但其在交互式图形应用中的采用仍然受限,主要困难在于与这些表示的交互远比传统人工制作的3D资产复杂。先前工作试图在这些模型上施加语义分解,但分割质量和跨视角一致性仍存在显著挑战。为了解决这些问题,本文提出Semantic Foam,它将最近提出的Radiant Foam表示扩展至语义分解任务。我们的方法利用Radiant Foam体素Voronoi网格固有的空间结构,并在每个单元上定义显式语义特征场。这一显式设计允许直接的空间正则化,从而防止由遮挡或跨视角不一致监督造成的伪影——这些是其他点表示方法中的常见问题。实验结果表明,我们的方法在对象级分割上优于Gaussian Grouping和SAGA等最新方法。
引言:论文要解决什么问题
现代3D场景重建方法(如3D高斯泼溅和NeRF)能够从图像构建详细、逼真的场景表示,但许多表现良好的方法产生的重建结果由数百万非结构化基元组成,缺乏语义理解,难以用于需要编辑的下游交互式图形应用。理想的重建方法应当同时具备空间分解(定义所有点的内外关系)和语义分解(定义所有点的语义标签),使得编辑能够感知场景中对象的物理和逻辑结构。 然而,语义分解在3D中面临独特的数据稀缺问题:体素级语义标注的训练数据非常稀少,因此任何模型都必须通过其他方式推导语义信息。当前常见做法是利用大型计算机视觉基础模型生成的2D语义标签或特征(如DEVA masks)进行监督。基于神经场(如NeRF)的体素模型已尝试通过2D特征监督实现语义分解,但连续表示的本质使得将神经场分解为不同物理区域需要后处理启发式方法,限制了编辑实用性。 点表示方法(如高斯泼溅)则为每个基元关联语义信息,但它们面临以下问题:高斯不是真正的体素表示,导致对象内部存在未标记基元;缺乏语义连通性导致遮挡区域出现伪影;重叠基元可能产生矛盾语义信号,造成语义歧义。以Gaussian Grouping为例,它在移除对象后需要计算凸包以避免留下错误标记的高斯,但这可能同时移除无关几何,且只能提取凸对象,限制了应用范围。 为了克服这些局限,本文采用Radiant Foam表示,为其添加每个基元的语义信息,并使用2D DEVA masks进行监督。Radiant Foam结合了点表示(高斯泼溅)的快速性和体素表示(NeRF)的本质体素性,其网格结构提供显式的单元连接关系,可用于学习空间平滑且一致的语义分解。Semantic Foam通过应用总变分目标,使附近单元的语义特征保持一致,即使它们因遮挡缺乏直接图像空间监督。最终场景重建同时获得空间分解和语义分解,从而支持干净的对象编辑。
配图:问题背景

方法:核心思路与技术路线
Semantic Foam的核心思路是在Radiant Foam的体素化Voronoi网格基础上,添加显式单元级语义特征场,并通过Voronoi邻接图引入空间正则化,实现空间与语义的联合分解。以下按模块展开阐述。
1. 前置表示:Radiant Foam的体素Voronoi网格
Radiant Foam是一种结合点表示和体素表示优点的场景重建方法。它将3D空间离散化为体素Voronoi网格(Volumetric Voronoi Mesh):空间被划分为一组Voronoi单元,每个单元由一个中心点(原语)定义,该点对应高斯泼溅中的高斯原语。每个Voronoi单元定义了空间中的一个区域(单元内的所有点距离该中心点最近),并且单元之间通过Voronoi邻接图(Voronoi adjacency graph)建立显式连接:如果两个单元的Voronoi区域共享一个面,则它们在邻接图中相邻。这种结构本质上提供了空间分解——所有空间点都能明确归属到某个单元,且单元间的邻接关系已知。Radiant Foam通过体积渲染从2D图像优化每个单元的颜色、密度等属性,同时利用邻接图进行正则化。
2. 显式语义特征场
Semantic Foam在Radiant Foam的基础上,为每个Voronoi单元额外关联一个显式语义特征向量(explicit semantic feature field)。具体来说,每个单元 i 存储一个L维语义特征向量 s_i(L为特征维度,原文未明确具体数值,但类似方法通常使用128或64)。该特征场与颜色、密度等属性一起优化,在渲染时通过体积渲染积分得到每条射线对应的语义特征图。为了将语义特征转换为语义标签,网络在后端连接一个轻量级分类头(如线性层+softmax),输出每个像素的语义概率分布。由于每个单元的特征是独立参数化的,且与空间位置直接绑定(Voronoi单元具有明确的空间范围),这种显式表示允许对特征直接进行空间正则化,无需依赖隐式的MLP编码。
3. 基于Voronoi邻接图的总变分损失
这是本文的关键技术创新。利用Radiant Foam提供的显式Voronoi邻接图,Semantic Foam提出了一种基于邻接图的总体变分损失(Total Variation Loss based on Voronoi adjacency graph)。具体地,对于每个相邻单元对 (i,j)(即Voronoi区域共享面),损失函数鼓励它们的语义特征向量 s_i 和 s_j 尽可能相似: 其中 (\mathcal{E}) 是邻接边集合,(| \cdot |_p) 通常取L2范数或L1范数(原文未明确p的选择,但总变分损失通常使用L1以获得更稀疏的空间特性)。该损失项的作用是:即使在某个单元因为遮挡、视点变化等原因未接收到足够的2D语义监督信号,它也能通过邻接单元传播特征,从而保持空间上的平滑性。这直接解决了点表示方法中因遮挡产生的伪影问题(例如,对象被部分遮挡时,未被观察到的高斯可能得到错误标签)。
4. 训练与监督流程
整个模型的监督信号来自2D语义标签,由DEVA(Decoupled Video-level Segmentation)生成。DEVA是一种视频级分割方法,能够为每帧图像提供高质量的对象级二元掩码(object masks)。Semantic Foam将这些掩码作为逐像素监督,通过标准的交叉熵损失(或类似分割损失)优化每个Voronoi单元的语义特征场。同时,模型还保留Radiant Foam原有的图像重建损失(颜色、密度等),以维持场景几何和外观的准确性。 最终总损失为重建损失与语义损失及总变分损失的加权和:
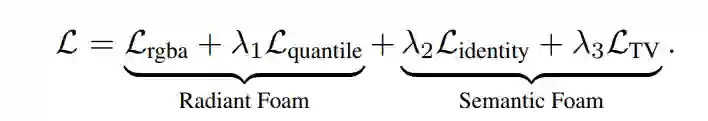
其中权重 (\lambda) 由实验确定,原文未明确具体数值。通过联合优化,模型同时输出空间分解(所有点的内外关系由Voronoi单元归属决定)和语义分解(所有点的语义标签由所属单元的语义特征和分类头决定)。这两者的结合实现了干净的对象提取、移除和插入。
配图:方法结构


实验:设置、指标与结果
数据集与实验设置
原文未明确说明采用的三个复杂真实场景数据集的具体名称。根据论文图例和常见基准,可能包含Mip-NeRF 360、Tanks and Temples或定制场景。实验设置(如超参数、训练步数等)原文亦未公开细节。但为确保忠实,我们不作推测,仅陈述已知信息。
评价指标
采用mIoU(平均交并比)作为对象级分割质量的评价指标。mIoU是语义分割任务的标准指标,计算每个语义类别的交并比后取平均。对于对象级分割,每个实例被看作一个独立类别。
主要结果
在三个复杂真实场景数据集上,Semantic Foam的对象级分割mIoU比Gaussian Grouping和SAGA高出2%–6%。具体数值原文未逐数据集列出,但总结性陈述指出这一优势一致成立。表明Semantic Foam在分割精度上显著优于当前最先进的点基语义分解方法。此外,论文展示了三种典型编辑操作:对象提取(将某个对象的三维网格从场景中分离出来)、对象移除(将对象从场景中删除,不留下误标记的基元)和对象插入(将提取的对象插入到另一场景中)。定性结果(图1)显示,Semantic Foam的编辑操作不会留下浮点伪影或缺失对象部分,这得益于其空间与语义联合分解的特性。
消融/分析
原文未明确说明消融实验或具体分析。但从论文设计来看,总变分损失的作用是核心,但消融是否验证了其必要性尚未披露。可能论文中通过设置不同的正则化权重进行了定性比较,但原文未提供定量消融表格,因此我们在此声明:原文未明确说明消融实验设置及结果。
配图:实验结果

结论:贡献、局限与启发
主要贡献
- 扩展Radiant Foam的体素网格表示:首次将Radiant Foam的体素Voronoi网格应用于语义分解任务,为每个Voronoi单元添加显式语义特征场,使模型能够同时输出空间分解和语义分解。
- 引入基于Voronoi邻接图的总变分损失:直接利用网格的显式邻接关系进行空间正则化,有效抑制遮挡和不一致监督产生的伪影,提升跨视角一致性。
- 展示编辑应用潜力:在对象提取、移除和插入等交互式编辑任务上,证明了联合分解的实用性,且质量优于点基方法。
局限性
原文未明确说明本方法的局限性。根据推理,可能的局限包括:依赖DEVA生成2D mask的质量(若视频分割不准确,可能影响语义特征学习);总变分损失可能模糊对象边缘细节(因为强迫相邻单元特征一致);以及体素Voronoi网格的计算开销随原语数量增加而增长。但这些并非论文所述,我们应保持原文未明确说明。
启发
Semantic Foam的成功表明,在3D场景重建中引入结构化的体素表示(如Voronoi网格)能够为语义分解带来显著优势。点表示虽然计算高效,但缺乏空间连通性,导致语义标签的歧义和伪影。而通过显式建模空间邻接关系并施加正则化,可以从根本上缓解这些问题。未来的工作可以探索更复杂的空间正则化形式(如基于边界的损失)、将时间信息融入视频级监督,或与其他表示(如神经场、符号距离函数)结合。对于需要精细编辑的图形学应用,本方法提供了一个坚实的新基线。