
导读
在自然界中,智慧往往源于集体:蚁群通过个体简单的局部规则完成复杂的筑巢任务,鸟类以局部视野协调飞行而不相撞,神经网络尚难企及这种灵活性。然而,当前主流的深度学习架构大多是“单体”的——一个庞大的网络将输入作为整体来处理,其内部信息是孤立的,缺乏类似于群体智能的分布式协调机制。当每个智能体(agent)仅观察到输入的一小块局部区域,且该区域信息本身不足以独立解决任务时,如何让这些智能体仅通过局部通信实现全局一致的协调,成为连接群体智能与深度学习的关键难题。 来自Sakana AI、华沙大学等机构的研究者Jeffrey Seely、Bartłomiej Cupiał、Llion Jones,在发表于ICML 2026的论文《Learning Multi-Agent Coordination via Sheaf-ADMM》中,提出了一种全新的可微优化框架Sheaf-ADMM。该框架将输入分解为重叠的局部视图,每个视图由一个智能体处理;智能体之间通过交替方向乘子法(ADMM)进行协调,而协调的一致性约束则通过细胞层(cellular sheaf)理论来定义,从而实现异构且灵活的全局共识。整个管道(pipeline)完全可微,支持端到端学习。 本文的核心创新在于,它超越了传统的消息传递神经网络(MPNN),后者往往将智能体之间的通信混为一谈,且缺乏可解释性。Sheaf-ADMM不仅为每个智能体维护了三个明确的状态变量(原始变量、一致变量、对偶变量),而且每个更新步骤都受到优化形式的严格约束(近端映射与Sheaf Laplacian运算),而不是任意的非线性学习映射。这种结构上的归纳偏置,使得模型在少数任务上表现出优于标准CNN和MPNN基线的鲁棒性与解题率。更重要的是,该框架暴露了协调动态的内部状态,允许研究者进行直接分析与干预,这是常规架构难以具备的宝贵特性。这篇文章对于关注多智能体系统、可微优化、图神经网络以及细胞层理论的研究者而言,是一份值得深入研读的精彩工作。
论文基本信息
英文题目 Learning Multi-Agent Coordination via Sheaf-ADMM 中文题目 通过 Sheaf-ADMM 学习多智能体协调 作者 Jeffrey Seely, Bartłomiej Cupiał, Llion Jones arXiv ID 2605.31005 类别 cs.LG Comments/接收信息 Proceedings of the 43rd International Conference on Machine Learning, PMLR 306, 2026. 原文链接 https://arxiv.org/pdf/2605.31005
摘要
本文提出一个可微优化框架,用于多智能体协调。输入被分解为重叠的局部视图,每个视图由一个智能体处理,该智能体解决一个由神经编码器参数化的凸子问题。智能体通过ADMM进行协调,智能体间的约束由细胞层指定。细胞层规定了相邻解决方案的哪些方面必须达成一致,从而允许异构的全局共识。通过展开的优化反向传播,可以联合训练多智能体系统的所有组件。我们在迷宫寻路、MNIST图像分类和数独上进行了评估,其中智能体仅观察不足以独立解决任务的小局部补丁,但它们通过学习协调产生了正确的全局输出。在MNIST上,局部视图分解相比标准CNN提高了对分布移位的鲁棒性。在数独上,优化推导的结构相比参数匹配的MPNN基线显著提高了解题率。最后,ADMM结构暴露了原始(primal)、一致(consensus)和对偶(dual)状态变量,使协调动态可直接分析和干预,这是标准消息传递架构不具备的特性。
引言:论文要解决什么问题
标准神经网络是“单体”的:单个大型网络将输入作为统一实体进行处理。相比之下,自然界中观察到的许多智能是“集体性”的,源于具有有限局部视图的智能体群体,通过协调来解决全局任务。受这一差距启发,论文提出了一个框架,用于在学习任务中实现多智能体协调,其中每个智能体仅观察输入的一小块局部区域。该框架名为Sheaf-ADMM。 研究的目标问题非常明确:当每个智能体的局部信息不足以独立解决任务时(例如,在迷宫寻路中,一个只看到迷宫一小块的智能体无法判断整体路径;在数独中,一个只看到一个小方格的智能体无法确定数字是否合法),如何通过智能体之间的局部通信与协调,使整个系统产生全局正确的输出? 该框架的核心思路是:将协调过程形式化为一个带约束的优化问题,并使用交替方向乘子法(ADMM)求解。每个智能体解决一个由其局部视图参数化的凸子问题(x-update),一个共识步骤将其局部方案投影到全局一致性(z-update),而对偶变量则累积历史的不一致信息(u-update)。一个关键的设计选择是如何定义全局一致性。论文借鉴了细胞层理论(cellular sheaf theory),指定智能体只需在其共享边缘空间(shared edge spaces)上达成一致投影,而不需要对整个状态向量达成一致——这允许异构的全局共识。例如,解决迷宫相邻区域的两个智能体只需要在路径是否穿过边界这一点上协调,而不需要协调其整个内部结构。 这项工作的基础源于Hanks等人(2025b)在细胞层约束多智能体系统中使用固定层结构的先前工作,但其发展并超越了后者:Sheaf-ADMM将其扩展成一个完全可微的系统,并在标准深度学习上下文中进行评估。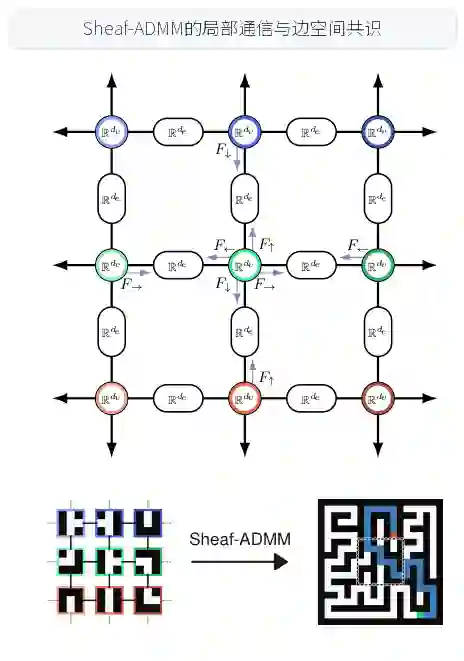
方法:核心思路与技术路线
总体架构:Sheaf-ADMM
Sheaf-ADMM的框架包括三个核心组成部分:输入分解、神经参数化的ADMM迭代、以及输出聚合。
# 输入分解与局部视图
对于给定的任务(如图像、迷宫或数独网格),输入被分解为一系列重叠的局部补丁(local patches)。每个补丁分配给一个智能体。每个智能体独立处理其局部补丁,但通过ADMM与处理相邻补丁的智能体进行通信。这种重叠设计确保了智能体之间共享边界信息,使得协调有意义。
# 神经参数化的凸子问题
每个智能体不是直接对输入进行卷积或全连接映射,而是由一个共享的编码器(neural encoder)处理其局部补丁,产生优化参数。具体来说,编码器输出用于参数化一个凸子问题的矩阵Q_i和向量q_i。该子问题在每步ADMM迭代的x-update阶段由智能体求解。由于子问题是凸的,其解可由近端映射(proximal map)计算,保证收敛性。
# 展开的ADMM迭代
ADMM的迭代被展开为固定步数K的层(ADMM layer)。在每一步k中,智能体依次执行三个更新:
- x-update(局部优化):每个智能体独立求解其局部凸子问题,即最小化关于自身原始变量
x_i的目标函数,并考虑来自前一共识变量z_i和对偶变量u_i的惩罚。这一步骤本质上是智能体的“提议”生成,基于其局部视图和当前的协调压力。 - z-update(全局协调通过Sheaf扩散):这是一个全局步骤,通过Sheaf Laplacian操作(sheaf Laplacian operator)将所有智能体的提议
x_i投影成共识变量z_i。Sheaf Laplacian是一个线性算子,它通过智能体间的线性映射(由细胞层定义)平滑地扩散信息,使相邻智能体在共享边缘空间上的值达成一致。这一步骤不是单纯的求平均,而是由细胞层的结构决定的加权扩散。 - u-update(对偶变量累积):对偶变量
u_i跟踪智能体自身提议x_i与共识变量z_i之间的差异。它累积历史不一致信息,并在后续迭代中施加压力来减少分歧。
这三个更新在每步迭代中顺序执行。整个ADMM层的计算过程是完全可微的,因为所有操作(凸优化、线性Laplacian、加法)都是可微的。
# 输出聚合与解码
在K次ADMM迭代结束后,每个智能体拥有其最终的原始变量x_i和对偶变量u_i。这些变量与局部补丁一起输入到一个共享的解码器(decoder)中。解码器为每个智能体生成一个局部预测(例如,根据局部路径预测是否包含像素;或根据局部数独格子预测数字)。最终,所有智能体的局部预测被聚合(例如,通过求和或平均数)成一个全局输出。
# 端到端学习
整个管道是端到端可微的。这意味着我们可以通过反向传播(通过展开的ADMM轨迹)来联合训练共享编码器、ADMM的参数(如惩罚系数)和共享解码器。优化目标是将全局预测与真实标签(例如,正确的路径、类别或数独答案)之间的损失最小化。这种训练方式使得智能体群体不仅学会如何使用局部信息,还学会如何通过交互来协调。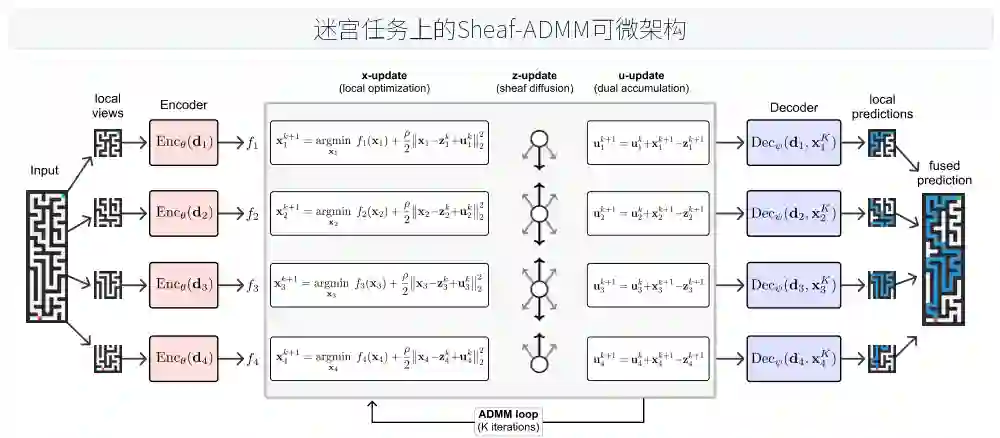
细胞层约束的关键作用
细胞层为异质智能体间的协调提供了数学框架。在传统的图网络中,所有智能体可能必须对它们的隐藏状态向量达成一致。但在细胞层中,每个智能体都有一个顶点空间(vertex space,R^{dv}),而智能体间的边(edges)对应共享的边缘空间(edge space,R^{de})。细胞层通过线性映射(F)将智能体的状态投影到边缘空间。智能体只在边缘空间的投影上达成一致,而不需要在完整的顶点空间上一致。
- 示例 在迷宫任务中,两个相邻智能体A和B。A的状态可能包含“路径在A的区域内如何拐弯”和“路径在A区域的边界出口位置”。B的状态包含其内部的路径。细胞层只要求它们在“路径是否在边界上正确连接”这个共享的边缘空间上达成一致。A可能在其内部的路径是弯曲的,而B内部的路径是直的,只要边界是连续的,它们就达成了协调。这种灵活性是本框架的核心优势。
为什么Sheaf-ADMM不是普通MPNN
从外观看,Sheaf-ADMM 和递归 MPNN 都在图上做多轮局部通信。但二者的差别在于“通信被什么约束”。MPNN 通常学习一个消息函数和更新函数,隐藏状态如何变化主要由参数自由决定;Sheaf-ADMM 则把更新拆成局部优化、sheaf 扩散和对偶累积三个有明确意义的步骤,每一步都来自优化问题的结构。 这种差异带来两个后果。第一,模型更容易把局部视图中的证据转化为全局一致性,因为信息传播不是任意消息混合,而是被限制映射投影到共享边空间。第二,内部变量具备解释性:原始变量像是每个智能体的局部提案,一致变量像是全局协调后的版本,对偶变量则记录尚未解决的分歧压力。
与其他架构的关系
- 与MPNN(消息传递神经网络)的关系 Sheaf-ADMM的迭代结构与递归MPNN类似。但其关键区别在于两点:(i) 每个智能体维护三个不同的状态变量(原始、一致、对偶),而不是单个隐藏向量;(ii) 每个智能体内部的更新和消息传递操作(近端映射、Sheaf Laplacian运算)由优化形式约束,而不是任意的学习非线性映射。
- 与递归MPNN的关系 两者都进行迭代通信,但Sheaf-ADMM的通信路径由细胞层定义,且通信内容(投影到边缘空间)也是由层结构决定的,而不是任意的消息向量。
- 与Sheaf神经网络和神经细胞自动机的关系 这些方法也使用细胞层或细胞自动机结构,但Sheaf-ADMM将其嵌入到优化框架中,具有明确的优化目标和可解释的变量。
实验:设置、指标与结果
实验设置
论文在三个任务上评估 Sheaf-ADMM:MNIST 分类、迷宫寻路和多智能体数独。共同设置是:输入被拆成多个局部视图,每个智能体只能看到很小的局部补丁,单个智能体无法凭自身视野解决全局任务。MNIST 和迷宫中,智能体对应空间网格上的 3×3 patch;数独中,智能体不是空间 patch,而是 9 个行智能体、9 个列智能体和 9 个 3×3 宫智能体,边连接共享格子的约束组。 在典型配置中,局部目标使用带 ℓ1 正则的对角二次形式;z-update 使用展开的共轭梯度求解。默认维度为:MNIST 上顶点 stalk 维度 32、边 stalk 维度 24;迷宫上为 10 和 5;数独上为 288 和 32。模型端到端以交叉熵损失训练,编码器、解码器、基础限制映射和 ADMM 惩罚系数一起学习。
数据集与任务
- MNIST 图像分类:28×28 图像被划分成多个 3×3 局部 patch,每个智能体只看 9 个像素。单个局部 patch 常常无法区分 1、4、7 或 3、8 等局部形态相似的数字,系统必须通过多轮协调形成全局类别判断。
- 迷宫寻路:论文生成 10,000 个 19×19 像素迷宫,对应 9×9 迷宫结构。每个智能体看 3×3 局部区域,任务是预测从起点到终点的全局路径。训练迷宫较小,目的是限制模型仅靠训练分布记忆长程路径。
- 多智能体数独:使用 Ritvik19 数独数据集。智能体对应行、列和宫等约束组,而不是普通像素 patch;该任务考验框架在非空间图上的适配能力,以及处理离散全局约束的能力。
主要结果
- 迷宫寻路:Sheaf-ADMM 在测试集上达到 99.9±0.1% 的精确解题率,与最强参数匹配 MPNN 相当;但在 2× 尺寸分布外迷宫上,Sheaf-ADMM 保持 98.1±1.2%,而参数匹配 MPNN(max 聚合)仅为 68.3±2.4%。这说明优化结构和 sheaf 约束不仅能拟合训练尺度,还能在更大输入上维持长程协调能力。
- 数独求解:Sheaf-ADMM(固定限制映射)以 1.12M 参数达到 92.6±0.2% 的 solve rate 和 99.5% cell accuracy。相比之下,参数匹配 MPNN 只有 10.7±0.6% solve rate;即使扩大到 4.62M 参数,MPNN 最好也只有 34.7±5.8%。这表明 ADMM 推导出的结构约束对全局一致性任务非常关键。
- MNIST 鲁棒性:在普通测试上,CNN 为 99.3%,Sheaf-ADMM 为 98.5%,基本相当;但在分布移位下差距明显。16 像素 padding 时 CNN 降到 11.4%,Sheaf-ADMM 仍有 86.3%;30% patch dropout 时 CNN 为 45.5%,Sheaf-ADMM 为 69.1%;高斯噪声 σ=0.10 时二者分别为 54.0% 和 74.0%。
- 可解释协调动态:ADMM 结构暴露原始变量、一致变量和对偶变量,使研究者能直接观察每个智能体在什么时候、在哪里仍然存在分歧。论文在分布外迷宫中发现,后期对偶残差集中在右下角分支点附近,说明系统可以定位具体协调瓶颈。
图3:Sheaf-ADMM 在 MNIST、迷宫和数独任务上的中间预测。随着迭代推进,局部不一致逐步被协调,迷宫路径和数独约束逐渐收敛。来源:原论文。
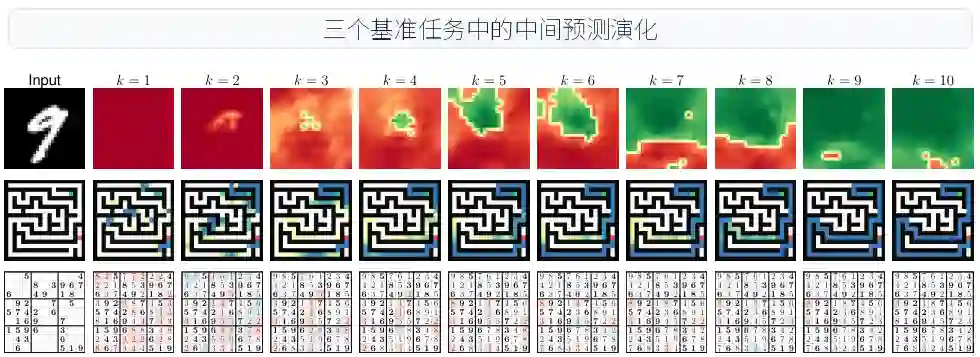 图3:Sheaf-ADMM 在 MNIST、迷宫和数独任务上的中间预测。随着迭代推进,局部不一致逐步被协调,迷宫路径和数独约束逐渐收敛。来源:原论文。
图3:Sheaf-ADMM 在 MNIST、迷宫和数独任务上的中间预测。随着迭代推进,局部不一致逐步被协调,迷宫路径和数独约束逐渐收敛。来源:原论文。协调动态分析
论文中(图4)展示了协调动态:通过对迷宫任务(2× out-of-distribution迷宫)的迭代过程进行可视化,分析了残差(primal residual, dual residual)随时间的变化。在迭代早期,各智能体的原始变量与共识变量之间存在较大差异(对应大的原始残差),对偶变量也较小。随着ADMM迭代,残差逐渐减小,表明协调达成。论文特别指出,在晚期迭代中,对偶残差集中在迷宫的一个特定区域(右下角的分支点附近),这揭示了协调瓶颈的位置——即在分支点,智能体需要额外努力的协商才能达成一致。这种对协调局部瓶颈的诊断能力是其他方法难以企及的。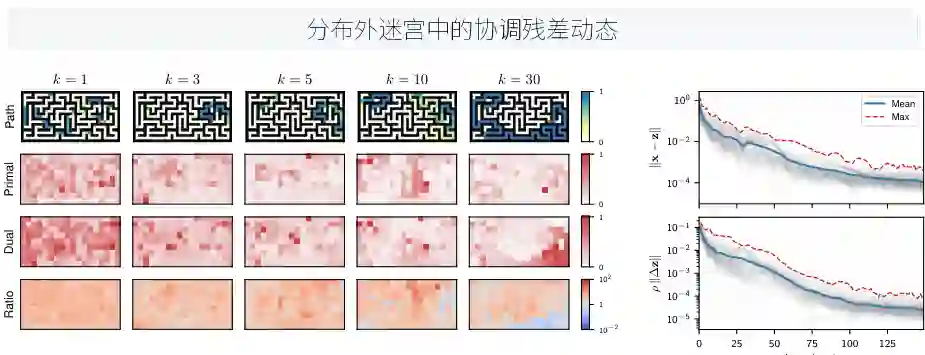
消融与分析
论文提供了组合消融,结论非常清晰。第一,没有协调(K=0)时,MNIST 只有 11.0%,迷宫和数独几乎为 0,说明局部视野本身确实不足以解决任务。第二,固定身份映射在 MNIST 上可恢复到 64.2%,但在迷宫和数独上失败,说明复杂任务需要更灵活的限制映射。第三,学习共享限制映射在数独上足够强(92.5%),但在迷宫上只有 8.9%;加入 LoRA 调制后迷宫达到 99.8%。 x-update 方面,带 ℓ1 正则的对角二次目标最稳定:MNIST 98.5%、迷宫 99.8%、数独 92.5%。z-update 方面,共轭梯度明显优于 Nesterov 梯度下降,尤其在 MNIST 和数独上差距很大。迭代次数 K 也有任务依赖:MNIST 在 K=10 左右饱和,迷宫和数独需要 20-30 轮;过深展开可能因梯度退化而损害性能。
结论:贡献、局限与启发
贡献
- 提出可微多智能体协调框架:首次将ADMM与细胞层理论结合到深度学习的可微框架中,实现端到端训练。
- 引入异构全局共识:通过细胞层约束,允许智能体只在共享边缘空间达成一致,而非全面一致,更具灵活性和生物合理性。
- 提供可解释性:框架暴露原始、一致和对偶变量,使得可以分析和干预协调动态,这是常规MPNN无法做到的。
- 展示优越性能:在MNIST上展现对分布移位的鲁棒性,在数独上取得显著高于MPNN基线的解题率。
局限性
论文也明确指出,Sheaf-ADMM 并不是所有多智能体问题的通用解法。它隐含了一个关键前提:全局任务可以被拆成一组重叠的局部子问题,而且这些子问题之间的相容性能够通过局部约束或局部消息来表达。若任务的正确答案依赖于高度非局部的统计量,例如需要跨越整个输入的全局计数、排序或长程组合特征,而这些信息无法压缩进低维共享边空间,Sheaf-ADMM 的结构偏置反而可能限制表达能力。 第二个限制来自图结构本身。Sheaf-ADMM 假设智能体图大体反映真实依赖关系:谁和谁共享信息、共享什么维度,应当与任务的因果或约束结构相匹配。如果图连接方式错误,或者局部视图划分破坏了任务中的自然依赖,后续 ADMM 迭代再精巧也只能在错误的通信拓扑上做协调。第三个限制是计算成本:展开 K 轮 ADMM、在 z-update 中求解线性系统、学习限制映射,都会带来额外开销。对于长程协调任务,可能需要更大的 K 或更强的扩散步数,这会增加训练和推理成本。 最后,虽然 ADMM 本身来自凸优化,但整套系统仍包含神经编码器、解码器和学习到的结构参数,因此整体训练问题不是凸的。论文的设计更准确地说,是把每轮潜在状态更新约束在可解释的凸子问题和线性 sheaf 扩散中,而不是保证整个深度模型具有全局凸性。这一点对理解其理论边界很重要。
启发
这项工作为多智能体系统和可微优化连接群体智能与深度学习提供了新的思路。其带来的启发包括:
- 设计新的归纳偏置 通过将智能体的通信约束为优化形式(近端映射与Sheaf Laplacian),而不是任意的MPNN,可以引入更强的结构先验。
- 可解释的协调动态 利用维护的三种变量,可以进行诊断和干预,例如在强化学习中识别协调瓶颈并主动施加惩罚或奖励。
- 端到端学习的协调 通过反向传播,可以学习如何将局部信息转化为全局协调行为,这为机器人群体协作、分布式感知系统等提供了潜在框架。
工程视角:什么时候值得使用 Sheaf-ADMM
从应用角度看,Sheaf-ADMM 最适合三类问题。第一类是天然具有局部重叠结构的问题,例如网格路径规划、图像局部感知、分布式传感网络和约束满足问题。此时,每个局部模块都有自己的观测和决策,但相邻模块必须在边界处保持一致。第二类是需要强可解释性的协调系统,例如多机器人协作、交通调度或资源分配;相比普通 MPNN,Sheaf-ADMM 可以把失败定位到原始残差、对偶残差或特定边空间上。第三类是训练分布和测试分布在尺寸或扰动上会变化的问题,因为优化诱导结构比纯黑盒消息传递更可能保留可迁移的协调规则。 不太适合的场景也同样清楚:如果任务主要依赖全局注意力式的信息汇聚,或者智能体之间没有稳定的局部依赖图,那么强行使用 sheaf 约束可能得不偿失。换句话说,Sheaf-ADMM 的优势不是“更大模型”,而是“更正确的结构归纳偏置”。当问题本身确实可以被理解为局部提案加全局一致性约束时,它才最能发挥作用。
与常见多智能体学习路线的差异
与强化学习中的多智能体协作不同,本文并不从奖励分配、信用归因或策略博弈入手,而是把协调问题放在监督学习和可微优化的语境中讨论。每个智能体的目标不是通过交互试错学习策略,而是在一个给定输入上提出局部解释,并通过 ADMM 与邻居逐步消除不一致。因此,它更像是一种面向结构化预测的“可学习求解器”,适合路径、图像、数独等有明确输入输出监督信号的任务。 与 Transformer 或全局注意力模型相比,Sheaf-ADMM 的信息流更受约束。全局注意力允许任意位置直接交互,表达能力强,但也容易学习到依赖数据分布的捷径;Sheaf-ADMM 只允许相邻或相关智能体通过共享边空间通信,表达能力受到拓扑限制,却换来更清晰的归纳偏置和更可诊断的中间状态。论文在迷宫尺寸泛化和 MNIST 扰动实验中的结果,正体现了这种结构约束的价值:模型不是简单记住训练尺寸下的全局模式,而是在局部一致性规则上形成了更可迁移的协调过程。 与传统优化方法相比,Sheaf-ADMM 又不是手工建模的固定求解器。局部目标、限制映射和解码器均由数据驱动学习,因而能够处理像图像分类这类难以完全写成显式约束的任务。它的定位介于“纯神经网络”和“纯优化算法”之间:用神经网络学习局部建模和参数化,用 ADMM 和 sheaf 结构保证协调过程具有明确形态。
总结
Sheaf-ADMM提供了一个可微的多智能体协调框架,具有可解释性和分析能力。它通过将输入分解、神经参数化、ADMM迭代和细胞层约束有机结合,使得具有有限局部视野的智能体可以学习协调解决全局任务。其核心贡献在于将两种互补的领域(分布式优化与细胞层理论)融合到一个可微的、可端到端学习的统一框架中,并展示了其在鲁棒性和推理能力方面的优势,以及独特的内部变量可分析性。
对多智能体学习的启发
这篇论文最有启发的地方,是把“协调”从一个黑盒通信过程转化为可微优化过程。对于多智能体系统、群体机器人、分布式感知、图推理和约束满足任务,很多困难并不在于单个智能体不够强,而在于局部信息如何汇聚成全局一致决策。Sheaf-ADMM 给出了一种结构化答案:让每个智能体解决局部问题,再通过可学习的 sheaf 约束规定它们必须在哪些共享维度上达成一致。 这也提示未来模型设计可以更多引入“可解释的迭代状态”。与其让一个深层网络在隐藏空间中隐式完成所有通信,不如把局部提案、共识、冲突压力等变量显式分离出来。这样不仅可能提升泛化和鲁棒性,也让研究者可以诊断系统失败发生在哪里,并在必要时对协调瓶颈进行干预。
原文信息
- 英文题目 Learning Multi-Agent Coordination via Sheaf-ADMM
- 作者 Jeffrey Seely, Bartłomiej Cupiał, Llion Jones
- 原文链接 arXiv:2605.31005 [cs.LG]
- 发表 Proceedings of the 43rd International Conference on Machine Learning, PMLR 306, 2026.