
ICML 2026|MEMOPILOT:用强化学习训练会进化的智能体记忆
导读
大语言模型智能体进入真实环境后,常常需要连续完成一组相关任务:与同一用户长期协作、反复调用工具、持续探索一个环境,或者多轮面对具有稳定行为模式的对手。此时,真正重要的不只是模型能否完成单次任务,而是它能否从已经发生的交互中吸取经验,在后续任务中做得更好。这种能力通常被称为测试时学习(Test-Time Learning,TTL)。 一种自然方案是为智能体维护显式文本记忆:每次交互结束后总结经验,再把记忆交给下一轮智能体。然而,当前许多记忆系统仍依赖人工设计的反思提示词或更新规则。它们能够生成“看起来合理”的总结,却不保证这些总结真的有助于下游决策,更难在多轮交互中稳定完成证据积累、假设修正和策略更新。 来自北京大学、清华大学、智谱 AI 等机构的研究者在 ICML 2026 论文《From Player to Master: Enhancing Test-Time Learning of LLM Agents via Reinforcement Learning over Memory》中提出 MEMOPILOT。其核心思想非常直接:不更新负责行动的玩家模型,而是训练一个独立的“记忆副驾驶”,让记忆更新本身成为可通过强化学习优化的策略。 MEMOPILOT 将跨局记忆演化建模为多轮马尔可夫决策过程,并采用多轮 GRPO 训练。每次记忆更新不再只追求语言上的完整或自然,而要对下一局的真实收益负责。实验表明,在冻结玩家模型的条件下,MEMOPILOT 在石头剪刀布和限注德州扑克中均取得最高 Elo,并能零样本迁移到更强的 Qwen3-235B 玩家;在 CoSQL 和 DS-1000 两个真实任务上也分别达到 73.5% 和 56.3%,说明这种方法学习到的不只是游戏技巧,而是一种更一般的经验组织与行动指导能力。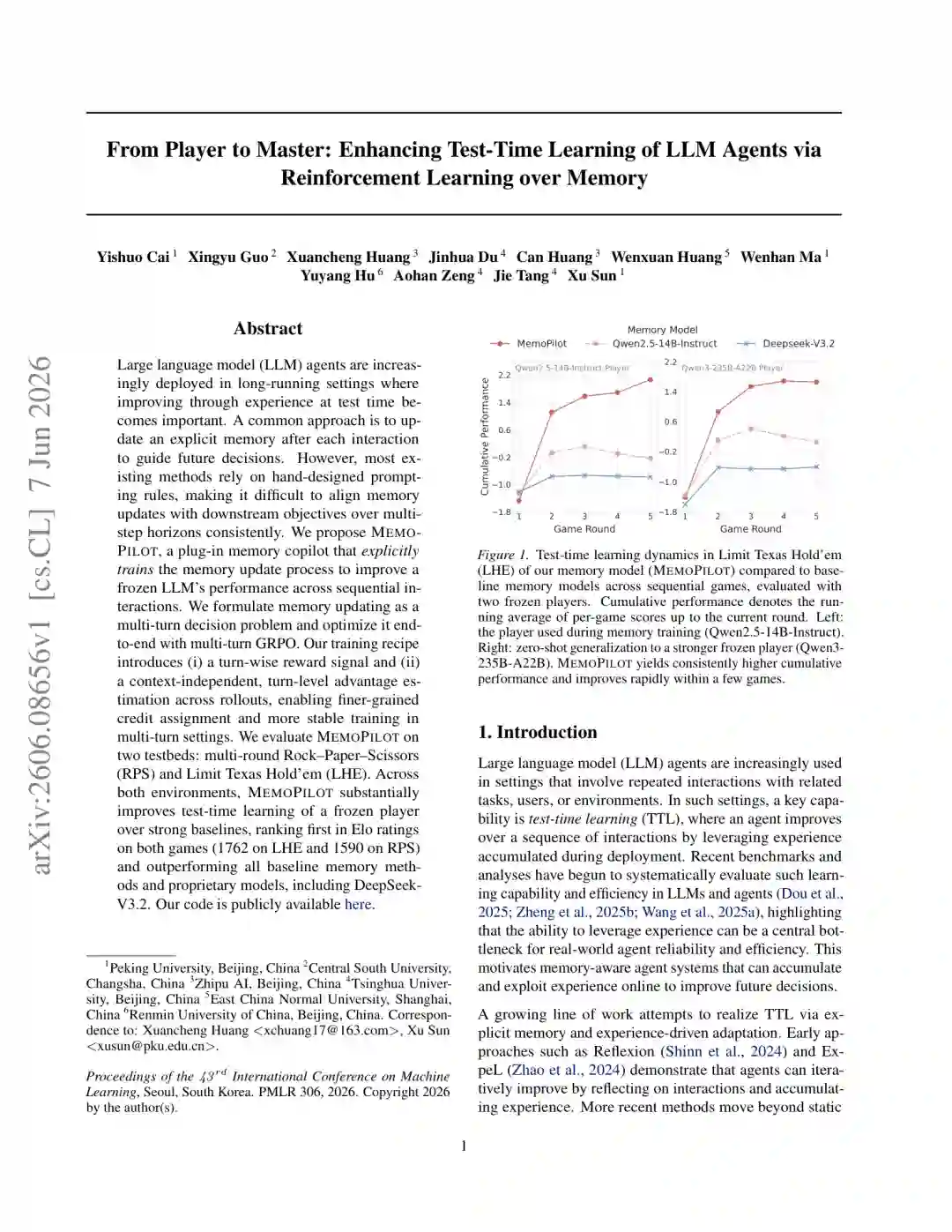
一、问题背景:智能体为何需要“可训练的记忆”
测试时学习关注的是这样一种在线过程:任务或交互按时间顺序逐个到来,智能体无法提前看到未来,只能利用过去的经验改善之后的表现。它不同于传统训练,因为部署阶段通常不方便频繁更新模型参数;也不同于普通上下文学习,因为交互可能很长,原始历史会迅速超过上下文预算,并混入大量偶然、重复或无关信息。 显式文本记忆因此成为一个很有吸引力的接口。它可以压缩历史、保留关键规律,并以自然语言形式向任意冻结模型提供指导。Reflexion、ExpeL、MemoryBank、Dynamic Cheatsheet 和 ReasoningBank 等工作已经证明,反思、经验提炼和动态记忆可以提升智能体表现。 但“生成一段记忆”和“生成能提高未来奖励的记忆”并不是同一件事。论文指出,手工提示驱动的记忆更新面临三个根本问题。 第一,优化目标错位。提示词通常要求模型总结错误、提取规律或给出建议,却没有直接约束这些文本是否能让下一次行动获得更高收益。 第二,信用分配困难。某条记忆可能在下一轮立即奏效,也可能因为环境随机性暂时失败。若只看整段交互的累计回报,很难判断究竟是哪一次记忆更新产生了作用。 第三,多轮演化能力不足。真正有用的记忆不是一次性总结,而应经历“提出假设、收集证据、验证或否定、修正策略”的循环。仅靠单轮反思,很容易把偶然事件误判为稳定规律,或者在新证据出现后仍固守旧结论。 因此,论文把问题重新表述为:能否直接训练一个记忆更新策略,使其产生的文本通过冻结玩家的后续行为,最大化跨多轮交互的累计收益?
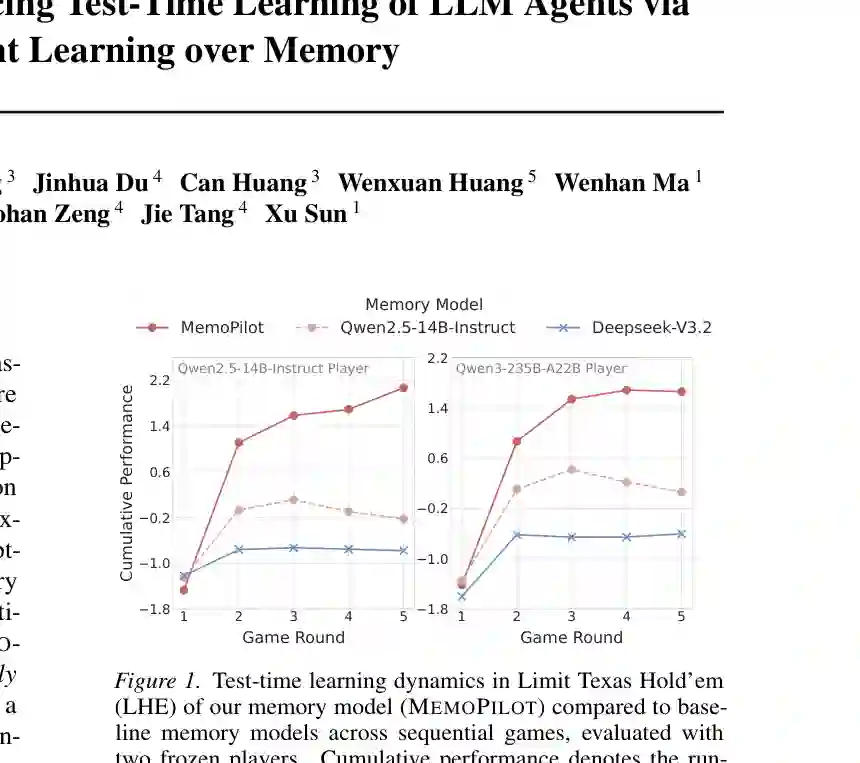
二、核心框架:玩家不变,记忆持续进化
MEMOPILOT 由两个角色构成。
- 玩家模型负责在当前环境中采取动作。它的参数始终冻结,而且跨局无状态,只能看到当前局环境和记忆提供的行动建议。
- 记忆模型读取最新交互轨迹与上一轮记忆,生成新的记忆状态。它是唯一需要训练的模块。
设第 (t) 局交互轨迹为 (e_t),收益为 (r_t),上一轮记忆为 (m_{t-1}),记忆模型为 (G_\theta),则新记忆为: m_t = G_theta(e_t, m_{t-1}) 随后,冻结玩家 (\pi) 在第 (t+1) 局中使用 (m_t) 进行决策。也就是说,第 (t) 次记忆更新的质量,不由语言模型自评,而由它能否改善下一局表现来检验。 这一设计有两个重要意义。其一,记忆模块是即插即用的,可以与不同规模、不同来源的玩家模型组合。其二,训练成本集中在较小的记忆更新模型上,无须对昂贵的主模型进行在线微调,也避免参数更新破坏玩家原有能力。
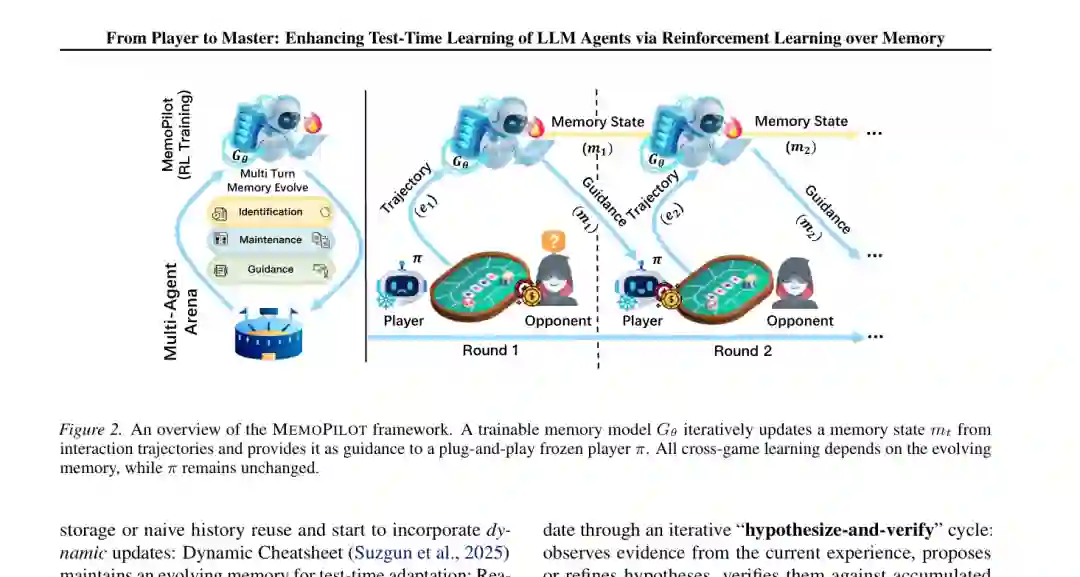
论文选择多轮石头剪刀布(RPS)和限注德州扑克(LHE)作为主要试验场,并不是为了单纯证明模型“会玩游戏”。这两类环境同时满足三个测试时学习条件:对手存在可利用的稳定结构;行为可以用明确规则控制和复现;每局都有清晰奖励,可用于强化学习。德州扑克还包含不完全信息和发牌随机性,可以检验模型能否区分真实策略信号与偶然结果。
三、把记忆更新建模为多轮决策过程
作者将记忆生成形式化为马尔可夫决策过程 (M=(S,A,P,R))。 在第 (t) 轮,状态为 s_t = (e_t, m_{t-1}),即刚结束的交互轨迹与此前记忆;动作是记忆模型生成的新文本 (m_t);状态转移由冻结玩家依据新记忆与环境、对手进行下一局交互而产生;奖励则是游戏结果。 一段训练 episode 包含连续 (T) 局游戏。第一局没有学习后的指导,主要用于探索;从第一局结束后开始,记忆模型不断更新记忆,玩家在后续局中使用它。理论目标是最大化所有记忆指导局的累计收益: R(tau) = sum(r_(t+1)), t = 1 ... T-1 这个表述抓住了一个容易被忽略的事实:记忆不是被动数据库,而是会改变未来行为、未来观察乃至未来可获得证据的决策变量。例如,记忆建议玩家采取更激进的试探动作,可能短期损失筹码,却暴露对手面对加注时的规律。因此,记忆更新天然具有序列决策属性。 不过,直接使用长时程累计回报训练会带来严重噪声。特别是在扑克中,未来收益同时受到记忆质量、发牌结果、位置和对手动作影响。一条优秀记忆可能因为下一局拿到差牌而得到低分;更远期奖励与当前记忆之间的因果关系则更加模糊。
四、多轮 GRPO:让每次记忆为下一局负责
为解决信用分配和高方差问题,MEMOPILOT 采用多轮 Group Relative Policy Optimization(GRPO),并对标准形式做了两项关键改造。
4.1 下一局奖励作为单步代理信号
对同一对手策略,旧策略模型并行采样 (G) 条多轮轨迹。第 (i) 条轨迹在第 (t) 次生成记忆 (m_{i,t}) 后,作者把下一局收益直接作为该次记忆更新的代理回报: R_(i,t) = r_(i,t+1) 这样,第 (t) 次记忆负责解释和改进第 (t+1) 局,而不是承担后面所有随机事件的结果。它虽然缩短了信用分配范围,却显著降低了方差,并使训练信号更贴近“这段建议是否立即可执行、是否确实有效”。
4.2 按轮次进行组内相对优势估计
对于相同对手和相同轮次,作者比较不同并行 rollout 的下一局收益,计算组内中心化优势: A_(i,t) = R_(i,t) - mean({R_(i,t)} from i=1...G) 该优势值被应用到同一次记忆生成的所有 token。最终优化维度从普通 GRPO 的“组、token”扩展为“组、轮次、token”。不同轮次的记忆更新获得相对独立的训练信号,避免后期上下文和环境随机性污染前期更新。 论文没有除以组内标准差。作者遵循相关研究的经验,保留奖励尺度差异,以避免在方差很小的组中放大噪声。训练时仍使用裁剪重要性比率,以限制新旧策略偏移。
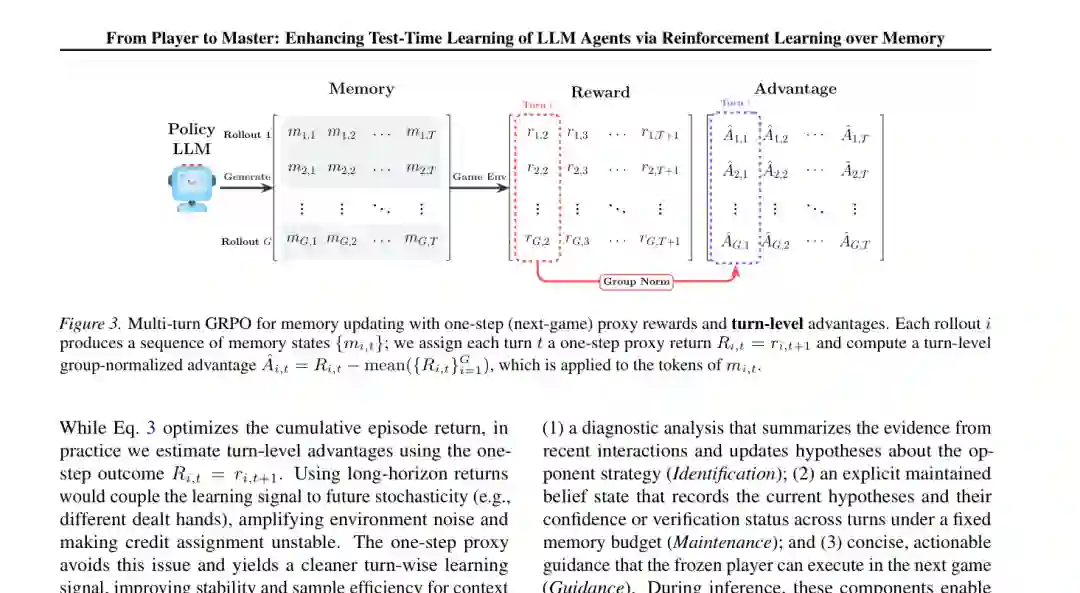
这种方法可以理解为一种“短反馈训练、长过程演化”:每一步用低方差的下一局奖励学习,但记忆状态本身跨轮保留,因此模型仍能学会逐步积累和修正证据。
五、三层记忆:从观察到信念,再到行动
仅有强化学习目标仍不够。文本记忆的动作空间极大,如果完全自由生成,模型可能写出冗长复盘、模糊判断或不便执行的建议。MEMOPILOT 为记忆规定了三层结构。
5.1 识别层
识别层分析最近轨迹中的证据,判断上一轮策略为何成功或失败,并更新关于对手的假设。它关注“看到了什么”和“这些现象说明什么”,承担诊断功能。
5.2 维护层
维护层保存跨轮信念状态。每条模式不仅记录内容,还标注“假设、已验证、已确认”等状态,附带观察次数、成功次数和证据来源。在固定 512 token 的记忆预算内,这一层需要主动保留有价值信息、合并重复信息并淘汰失效判断。
5.3 指导层
指导层把上面的分析压缩成简洁、可执行的规则,并且只有这一部分会交给冻结玩家。换言之,玩家无需阅读完整推理和知识库,只接收下一局应该如何行动的策略提示。 三层设计把“面向记忆模型的内部状态”和“面向玩家模型的控制指令”分离开来。识别层允许展开分析,维护层保证长期一致性,指导层则降低玩家的认知负担。这也是 MEMOPILOT 超越简单历史拼接的重要原因:原始轨迹包含信息,但并未替玩家完成从证据到行动的转换。
六、可控对手池与严格评测设置
作者构建了 32 个训练 RPS 策略、45 个训练 LHE 策略,以及 41 个留出策略,其中包括 32 个 RPS 和 9 个 LHE 测试对手。对手不是黑盒模型,而是由可执行自然语言指令定义,例如固定序列、根据上一步反应的规则、带条件触发的组合模式,以及扑克中的跟注站、特定街激进、延迟偷池和河牌诈唬等。 对手构建遵循“人类种子策略、LLM 扩写与标准化、人工复核和试运行”的流程。训练集与测试集按机制划分,而非仅随机拆分文字描述。留出对手会保留相近战略意图,但改变触发条件、暴露信息的阶段或规则组合,因而能够测试记忆模型是否真的学会维护与修正假设。 主要实验采用 Qwen2.5-14B-Instruct 作为冻结玩家和基础记忆模型,并进一步把训练好的 MEMOPILOT 零样本接到 Qwen3-235B-A22B 玩家上。每种设置运行 64 次并报告均值。每局跨局记忆预算统一限制为 512 token,以保证与各类基线公平比较。 基线包括无记忆、完整历史、人类编写反制策略,以及 Reflexion、ExpeL、MemoryBank、AWM、ReasoningBank 等方法;还包括由 Qwen2.5-14B、DeepSeek-V3.2 和 Gemini-3.0-Flash 直接根据提示更新记忆的强模型基线。
七、主要结果:冻结玩家也能快速变强
7.1 训练玩家上的表现
在 Qwen2.5-14B 玩家上,无记忆基线的 RPS@5 得分为 0.43,LHE@5 为 -1.36。使用同一个 Qwen2.5-14B 通过提示词更新记忆,只达到 0.21 和 -0.23;DeepSeek-V3.2 记忆模型取得 1.64 和 -0.78。这说明更强语言模型生成的反思不等于有效的在线学习策略。 MEMOPILOT 则达到 3.28 和 2.03,相对强基线分别提升 3.10 和 2.30。尤其在德州扑克中,它把原本为负的平均收益转为显著正收益。
7.2 向更强玩家零样本迁移
将训练好的记忆模型直接接入 Qwen3-235B-A22B,不进行任何再训练,MEMOPILOT 在 RPS 和 LHE 上仍取得 3.27 和 1.31。这说明它没有仅仅记住 Qwen2.5-14B 的措辞习惯,而是学会生成更一般的、可被不同玩家执行的策略指导。
7.3 Elo 排名
在所有留出对手的综合排名中,MEMOPILOT 在 LHE 上获得 1762 Elo,在 RPS 上获得 1590 Elo,两项均排名第一。完整历史输入反而经常落后,表明更多上下文并不自动带来更强适应能力;未经筛选的历史会稀释关键规律,并提高玩家模型的推理负担。
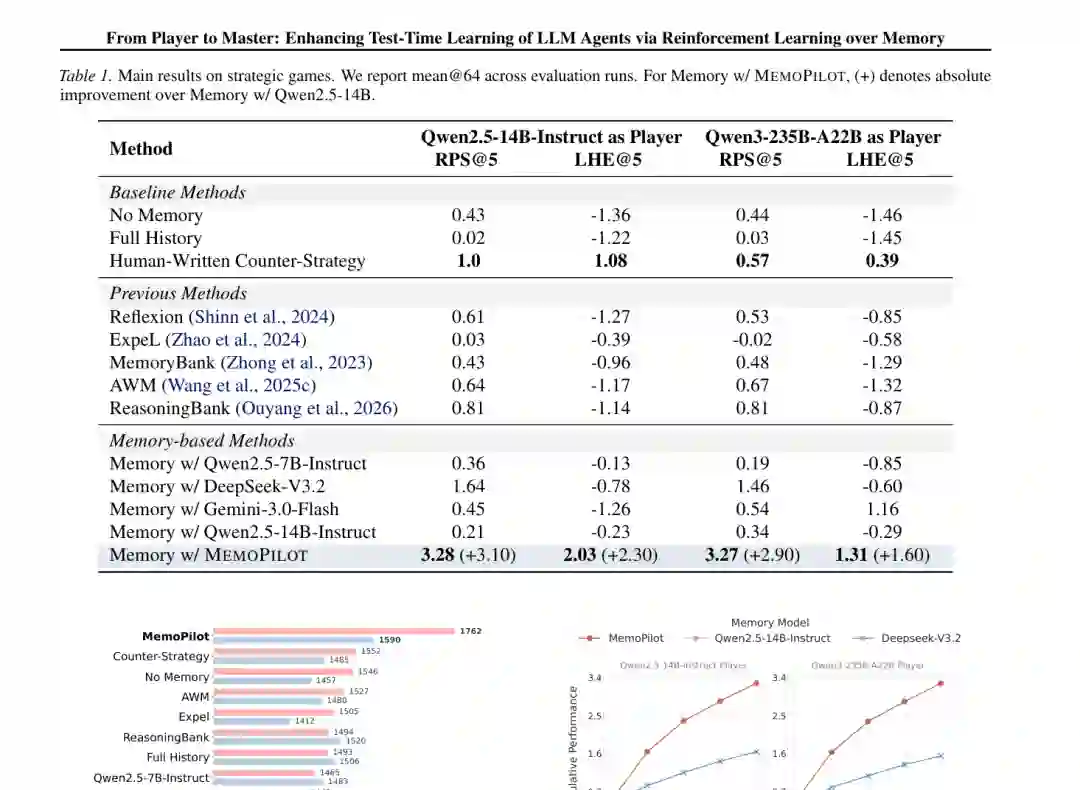
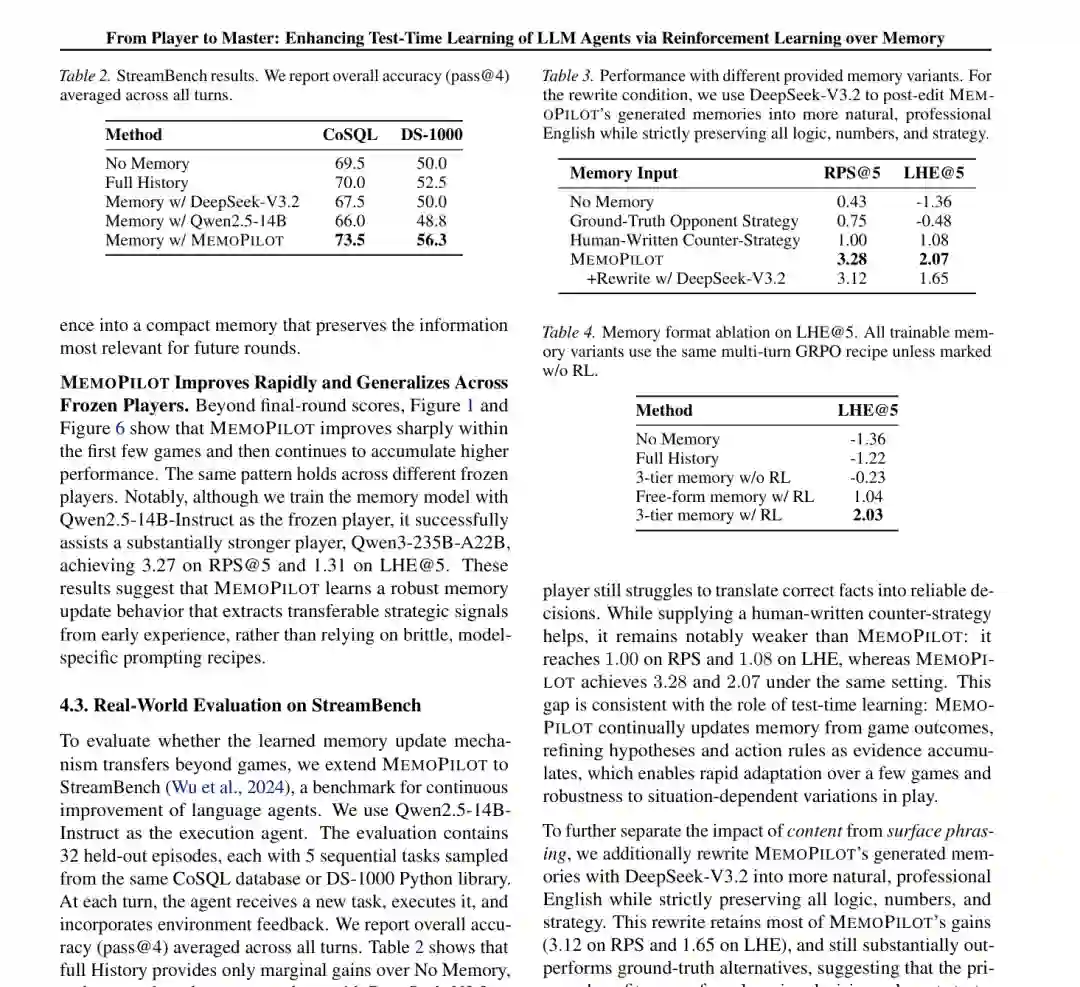
值得注意的是,MEMOPILOT 的优势会随游戏推进迅速出现。这正是测试时学习应具备的特征:系统不是靠训练集平均性能取胜,而是在面对一个此前未见的具体对手时,通过少量交互识别其模式并形成针对性策略。
八、从游戏迁移到真实任务
为了检验方法是否只适用于博弈,作者进一步在 StreamBench 上评估 CoSQL 和 DS-1000。前者要求连续处理上下文相关的文本到 SQL 查询,后者涉及数据科学代码生成;两者都需要从此前任务的反馈中积累可复用经验。 在 CoSQL 上,无记忆、完整历史、DeepSeek-V3.2 记忆和 Qwen2.5-14B 记忆的结果分别为 69.5%、70.0%、67.5% 和 66.0%,MEMOPILOT 达到 73.5%。 在 DS-1000 上,对应结果为 50.0%、52.5%、50.0% 和 48.8%,MEMOPILOT 达到 56.3%。这两组结果尤其有启发性:通用大模型的提示式总结可能删除真正重要的失败条件,甚至让后续表现下降;经过奖励训练的记忆则更倾向于保留能改变下一次行动的信息。
九、关键分析:什么样的记忆真正有效
9.1 “知道对手策略”仍不等于“会反制”
作者直接把真实对手策略描述交给玩家,RPS 和 LHE 得分只有 0.75 和 -0.48;由人类专家编写反制策略后,提升到 1.00 和 1.08;MEMOPILOT 则达到 3.28 和 2.07。 这个结果说明,事实正确性只是有用记忆的必要条件之一。玩家还需要把事实转化为具体动作规则,并针对自身能力、环境约束和决策时机进行表达。MEMOPILOT 的训练目标正是奖励这种“可执行性”。 当作者让 DeepSeek-V3.2 在不改变逻辑和数字的前提下,把 MEMOPILOT 记忆改写成更自然的专业英语,成绩从 3.28/2.07 降至 3.12/1.65。内容大体不变,表现仍发生下降,说明记忆的措辞、结构和指令强度也是智能体控制接口的一部分。
9.2 强化学习和结构化记忆缺一不可
在 LHE 上,无记忆得分为 -1.36,完整历史为 -1.22;仅使用三层提示结构但不训练,可提升到 -0.23。采用强化学习但允许自由格式生成,得分达到 1.04;三层结构与强化学习结合后进一步达到 2.03。 因此,结构化提示提供了有效归纳偏置,帮助模型分离诊断、状态维护和行动指导;强化学习则让这些内容与实际收益对齐。结构不能替代优化,优化也会受益于合适的文本状态空间。
9.3 更长训练时程带来更稳定的后期收益
作者比较两轮和五轮训练。两轮训练能够学习快速反应,但五轮训练在十局评测中表现更稳定,并在后期持续获得更高累计收益。这说明多轮训练不仅让模型学会写一条好建议,还让它学会何时坚持已有判断、何时因新证据调整信念。
9.4 热启动记忆可以迁移,但必须允许修正
面对对手 B 时,冷启动 MEMOPILOT 在 RPS/LHE 上得到 3.28/2.03;先与另一个对手 A 交互再切换到 B,结果为 2.56/3.26;先与 B 交互后继续面对 B,则达到 5.22/3.58。 同一对手的已有记忆显著提高后续表现,证明系统确实积累了针对性知识。跨对手切换后仍保持较强收益,则表明记忆模型能够覆盖旧信念并重新适应,而不是简单追加不可修改的经验条目。
9.5 单步奖励比累计奖励更稳定
在 LHE 中,使用长时程累计奖励训练只得到 0.61,而使用下一局单步奖励达到 2.03。扑克的发牌随机性会让远期回报成为高噪声监督,单步代理奖励虽然更局部,却提供了更可靠的因果信号。

十、局限与失败模式
10.1 非平稳对手会造成记忆滞后
MEMOPILOT 的主要困难来自“维护”和“修正”的矛盾。稳定环境中,保留已确认规律能减少无谓波动;但当对手频繁改变策略时,旧记忆会成为负担。 LHE 实验中,面对固定对手时得分为 2.03;每五局切换一次对手降至 1.76;每两局切换一次进一步降至 1.21;面对同样拥有记忆、能够主动适应的对手时为 1.25。变化速度越快,系统越难在有限证据下判断当前异常是随机波动还是策略已经改变。

未来可以引入显式变化点检测、记忆时间戳、假设衰减和多时间尺度状态:短期层快速响应新迹象,长期层保存经过充分验证的规律,并由门控机制决定何时覆盖。
10.2 依赖可观测奖励和重复经验
该方法需要多次相关交互以及能够评价结果的奖励。如果任务只有一次机会、反馈极度延迟,或者奖励无法反映真实目标,就难以构造稳定训练信号。现实系统还可能存在多目标冲突,例如正确率、成本、延迟和安全性必须同时权衡。
10.3 固定文本预算可能丢失长期信息
实验将记忆限制为 512 token,这有利于公平比较和高效推理,但更长任务会要求分层压缩、检索和遗忘机制。仅靠单块文本不断改写,可能错误删除罕见却关键的边界条件。
10.4 游戏环境与开放世界仍有距离
可控对手池提供了清晰因果分析,但真实用户、网页、软件工具和多智能体环境更加开放。观察噪声、目标漂移、工具故障和反馈偏差会同时出现。StreamBench 结果证明了一定迁移潜力,但还不足以代表长周期生产环境。
十一、研究启示
MEMOPILOT 最重要的贡献,不是提出了又一种记忆提示模板,而是改变了记忆系统的训练对象和评价标准。 过去,记忆通常被当作存储层:系统关注写入什么、如何检索、如何压缩。本文则把记忆更新视为一种策略,记忆文本是影响未来行动的控制信号。评价一段记忆时,不应只问它是否忠实、清晰和完整,还要问它是否让下游智能体在下一次交互中采取了更好的动作。 这一视角对通用智能体系统有几方面价值。
- 模块化升级:冻结主模型,只训练记忆副驾驶,可以低成本适配多个玩家或工具智能体。
- 行为对齐:通过真实任务收益训练记忆,减少“反思文本很漂亮、行动却没有改善”的问题。
- 持续学习:显式信念状态使系统能够累积证据、记录置信度并修正旧结论。
- 可解释控制:文本记忆保留了可审查接口,开发者可以看到系统如何从观察推导策略。
- 新的优化边界:模型参数之外,提示词、记忆、工具调用计划和上下文组织都可以成为强化学习的动作空间。
对实际工程而言,一个值得借鉴的最小方案是:将长期交互压缩为“证据、当前假设、验证状态、下一步行动规则”四类信息;用下一次任务的可测结果评价更新质量;把内部分析和给执行模型的指令分离;在环境变化时显式降低旧假设置信度。即便不立即进行完整 RL 训练,这些原则也能改善现有记忆管线。
十二、总结
MEMOPILOT 提出了一条清晰路线:让冻结 LLM 智能体在测试时持续变强,不一定要在线修改主模型参数,也不应只依赖人工编写的反思规则;可以训练一个独立记忆模型,把每次交互转化为经过验证、可维护、可执行的策略状态。 多轮 MDP 建模解决了记忆演化问题,下一局代理奖励和按轮 GRPO 提供了低方差信用分配,三层记忆结构则把诊断、信念维护与行动指导分开。其在 RPS、LHE、CoSQL 和 DS-1000 上的结果共同说明:真正有效的智能体记忆,不只是过去发生了什么的摘要,而是面向未来决策、能够随着证据持续修正的控制策略。 论文地址:https://arxiv.org/abs/2606.08656
