

基于LLM的自主智能体在推理、规划和工具使用方面展现了强大能力,但在需要跨角色、工具和环境进行持续协调的任务中仍然受限。多智能体系统通过结构化协作解决了这一限制,但更紧密的协调也放大了尚未充分探索的风险:错误可以在智能体之间和交互轮次之间传播,产生难以诊断的故障,而且即使被识别也难以转化为结构性自我改进。现有综述分别覆盖了个体智能体能力、多智能体协作或智能体自演化,但将这些主题孤立处理,忽略了它们之间的因果依赖关系。本综述围绕四个因果相连的阶段提供统一综述,我们称之为LIFE progression:Lay the capability foundation(奠定能力基础)、Integrate agents through collaboration(通过协作集成智能体)、Find faults through attribution(通过归因发现故障)、Evolve through autonomous self-improvement(通过自主自我进化)。我们系统回顾了个体智能体的能力基础、多智能体协作的组织机制、故障归因的方法论全景以及自演化的层次化设计空间。我们形式化描述了相邻阶段之间的依赖关系,揭示每个阶段如何既依赖又约束下一个阶段。除综合现有工作外,我们识别了阶段边界处的开放挑战,并提出了跨阶段研究议程,旨在实现能够持续诊断故障、重组协作结构和优化智能体行为的闭环多智能体系统,将当前人为设计的协作框架向更具自组织和韧性的集体智能形式延伸。
1 Introduction / 引言
大型语言模型(LLM)已从流畅的文本生成器演变为能够进行复杂推理、长期规划以及与外部环境交互的系统。然而,个体LLM在面对需要跨角色、工具和环境持续协调的任务时仍然存在局限。多智能体系统通过结构化协作解决了这一问题,但更紧密的协调也放大了错误传播的风险:局部错误(如幻觉事实、消息误路由、工具调用错误)可以通过连续交互轮次传播,触发级联故障,使根本原因难以识别。此外,即使诊断成功,现有多智能体系统也普遍缺乏将诊断洞察转化为结构性调整的能力——无论是重组协作拓扑、修订角色分配还是优化协作策略。这两个缺陷(归因缺失和自我修正缺失)紧密交织:没有可靠诊断,改进方向不明;没有行动能力,归因价值有限。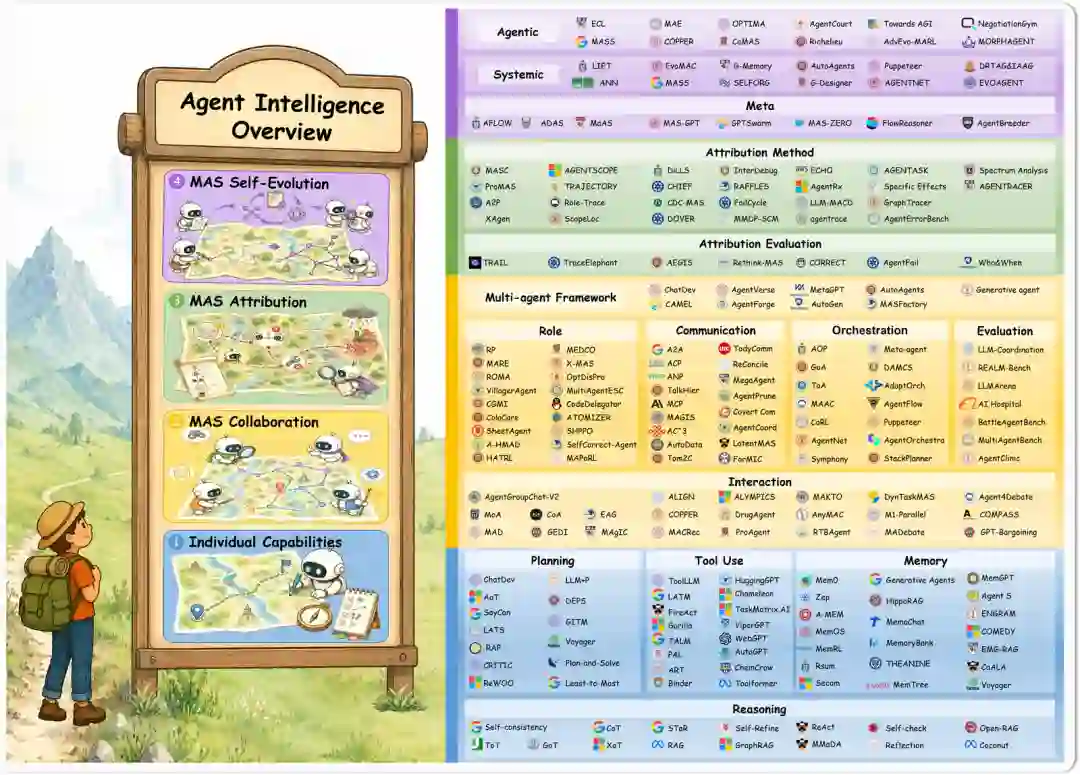
如图 1 所示,本综述围绕操作生命周期组织基于LLM的多智能体系统。图 1 展示了从个体智能到协作、故障归因和自演化的跨阶段进程,右侧总结了每个阶段的代表性主题和系统。图 2 进一步通过协作旅行规划示例说明四个因果相连阶段的具体流程:个体智能体独立获取信息,通过协作整合计划,在归因阶段诊断故障,最终通过自演化改进系统结构。这两个图示共同构成了LIFE progression的视觉框架。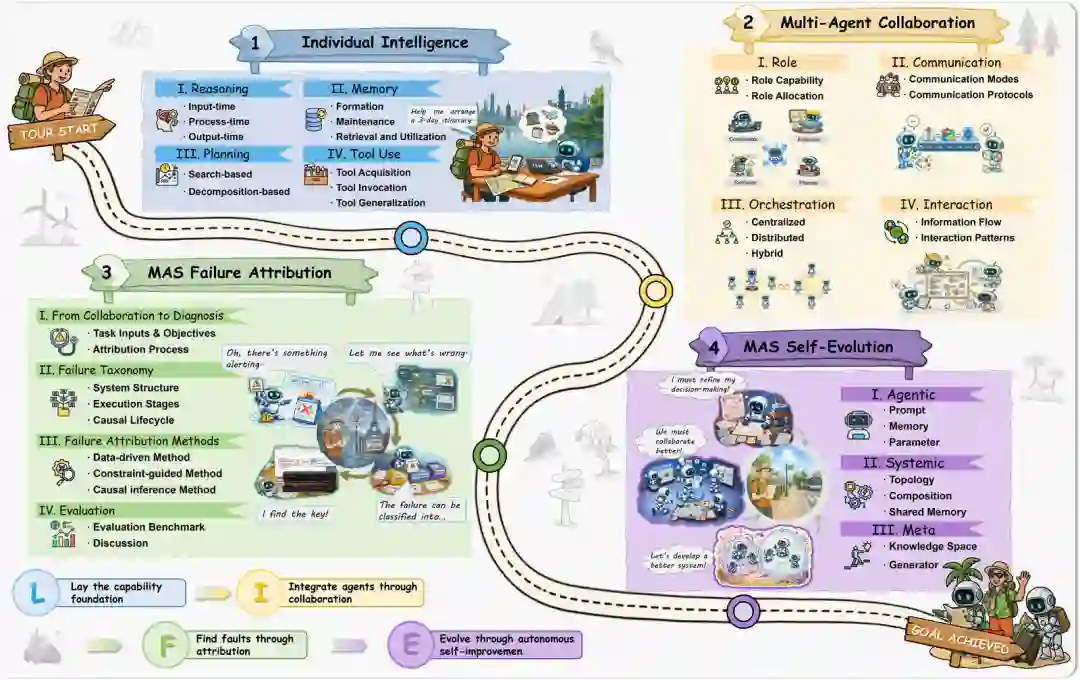
现有综述分为三条主线:个体智能体能力(推理、记忆、规划、工具使用)、多智能体协作(角色、通信、编排、交互)以及智能体自演化。这些工作分别覆盖不同方面,但缺乏对多智能体故障归因的系统综述,且未将完整操作生命周期作为整体考察。本综述是首个覆盖LLM多智能体系统完整操作生命周期(从个体能力到协作、故障归因和自主结构改进)的工作,通过LIFE progression框架将跨阶段依赖关系显式化,并提出了归因-演化闭环的研究议程。
2 Individual Intelligence / 个体智能
2.1 From LLM to LLM-based Agent: An Architectural Overview / 从LLM到基于LLM的智能体:架构概述
LLM作为无状态响应生成器缺乏持久存储器,无法主动感知或作用于外部环境,这推动了从反应式文本生成器向基于LLM的自主智能体的转变。我们形式化定义智能体 (a = (X, U, O, M, R, P, T)),其中 (X) 是观测空间,(U) 是动作空间,(O) 是工具返回观测空间,(M) 是记忆状态空间,(R, P, T) 分别对应推理、规划和工具执行。决策过程包括:从记忆中检索上下文、通过推理生成中间表示、通过规划生成动作序列、选择并执行动作、更新记忆状态。如图 3 所示,个体智能体架构将四个能力模块组织成闭环系统:推理指导工具选择,规划协调多步工具调用,记忆保留中间结果和策略,工具执行将动作锚定在外部环境。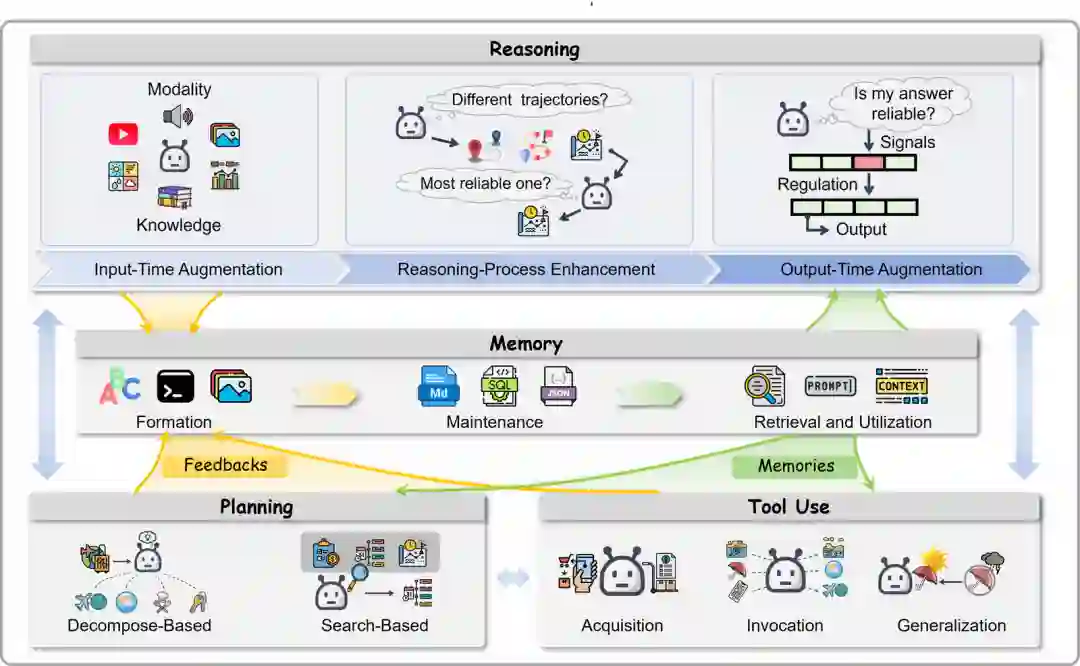
2.2 Reasoning / 推理
推理构成智能体的认知基础。我们沿推理管线信息流将方法分为三个阶段:输入阶段增强、推理过程增强、输出阶段调控。
# 2.2.1 Input-Stage Enhancement / 输入阶段增强
包括知识增强(RAG、Self-RAG、SubgraphRAG等)和模态增强(Multimodal-CoT、Visual Sketchpad等),通过外部知识检索或多模态感知扩展模型可访问信息。
# 2.2.2 Reasoning-Process Enhancement / 推理过程增强
分为搜索空间扩展(Tree of Thoughts、DeepSeek-R1、CPO等)和推理路径验证(Self-Consistency、Reflexion、PRMs等),通过扩大候选解覆盖率和路径筛选提升推理质量。
# 2.2.3 Output-Stage Regulation / 输出阶段调控
包括输出可靠性评估(FActScore、SelfCheckGPT、HaloScope等)和响应行为调控(DoLa、CAD、FactTune、CRITIC等),通过事后评估和自适应校正减少事实错误。
2.3 Memory / 记忆
记忆使智能体能够记录、巩固和回述任务执行经验。我们围绕记忆生命周期组织:记忆形成(直接记录、抽象蒸馏、分类路由)、记忆维护(存储结构:平展列表、图结构、层级结构;动态维护:基于衰减、LLM驱动策略、学习策略)、记忆检索与利用(检索机制:稠密向量、多因子评分、类型感知检索;集成模式:上下文注入、经验条件推理、技能执行)。
2.4 Planning / 规划
规划将高层目标转换为可执行动作序列。分为分解式规划(主动分解:Least-to-Most、HuggingGPT、LLMCompiler等;渐进分解:ReAct、Reflexion、Voyager等)和搜索式规划(步骤级搜索:MCTS变体、A*搜索;计划级搜索:多计划选择、Agent S等)。
2.5 Tool Use / 工具使用
工具使用扩展智能体动作空间。组织为三个维度:工具能力获取(轨迹学习:Toolformer、ToolLLM;协议对齐:Gorilla、MCP)、工具调用模式(单次调用、闭环调用、工作流编排)、工具泛化(未见工具的迁移能力)。
3 Multi-Agent Collaboration / 多智能体协作
多智能体协作通过分解复杂任务为专业化角色,借助结构化通信和协调编排实现集体问题求解。如图 4 所示,组织多维度的分类学,覆盖角色分配、通信协议、编排拓扑和交互模式,每个维度包含若干技术变体。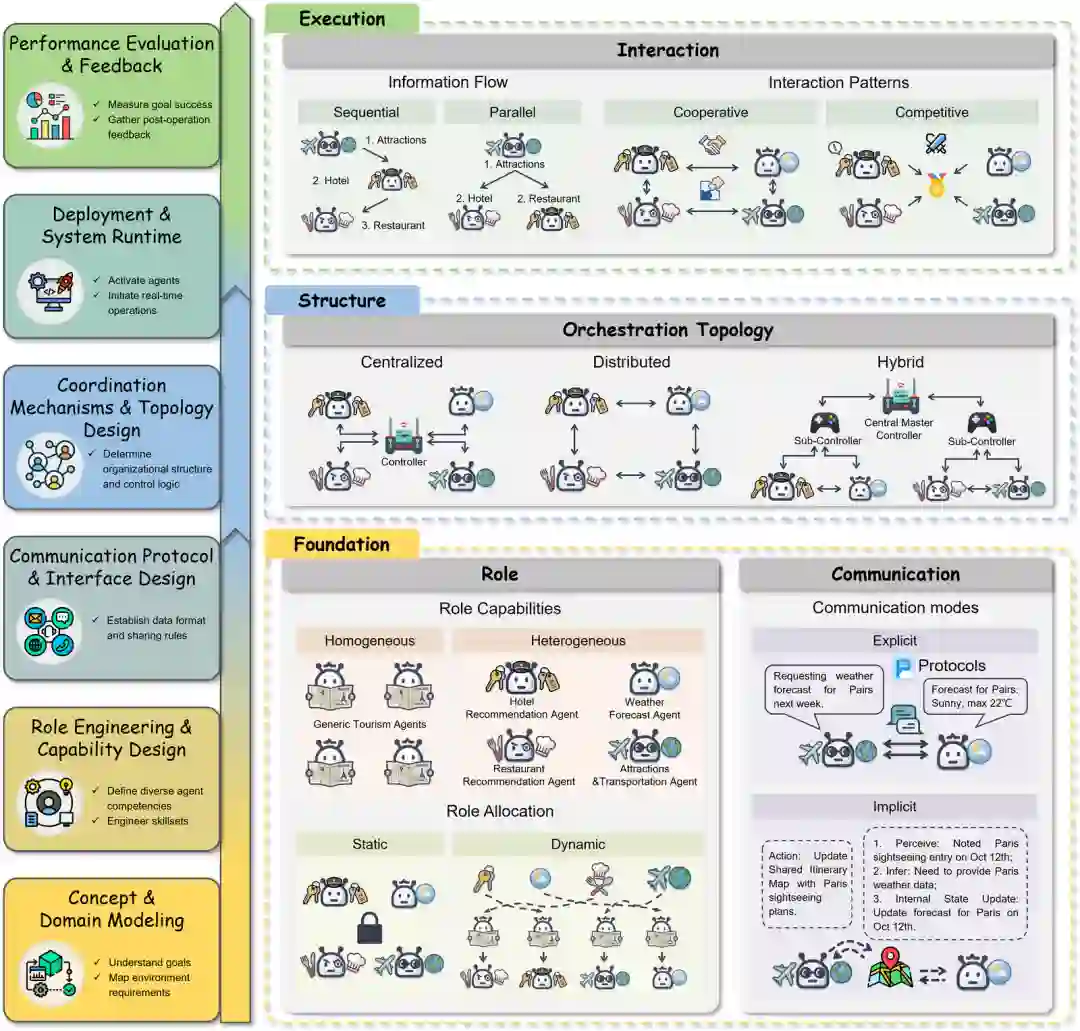
3.1 Role / 角色
角色能力定义智能体的领域专长(通过系统提示或记忆附加设定),角色分配方式包括固定分配、动态分配、进化分配。代表性工作如ChatDev分配分析师、程序员、测试员角色;MetaGPT将产品经理、架构师角色融入软件开发流程。
3.2 Communication / 通信
通信模式包括广播(所有智能体可见)、定向(一对一发送)、共享工作区(如共享记忆或白板)。通信协议包括自由形式自然语言、结构化消息(如JSON Schema)、标准化协议(如MCP协议规范消息格式)。
3.3 Orchestration / 编排
编排拓扑决定命令流中心化(manager-managed,典型如AutoGen)、分布式(peer-to-peer,每个智能体自主决策)、混合拓扑(动态切换,Hierarchical Agent Teams)。不同拓扑在可扩展性、弹性、收敛速度上存在权衡。
3.4 Interaction / 交互
信息流类型包括任务状态流、知识共享流、反馈流。交互模式包括辩论模式(多智能体辩论改进推理)、交易模式(任务分解后分配执行)、迭代优化模式(生成-批评循环,如ChatDev的代码审查循环)。
3.5 Evaluation / 评估
多智能体协作评估指标包括任务完成率、协调效率(通信轮次)、错误传播距离等。代表性基准包括MASE(多智能体软件工程)、DynaCon(动态协调任务)。
3.6 Discussion / 讨论
当前协作系统面临的关键挑战包括:手工设计的角色的灵活性不足、通信开销随智能体数量超线性增长、缺乏故障感知的编排机制。未来方向包括基于学习的角色涌现和自适应的通信压缩。
4 Multi-Agent System Failure Attribution / 多智能体系统故障归因
4.1 From Collaboration to Diagnosis / 从协作到诊断
紧密耦合协作导致错误传播和诊断困难。我们形式化归因过程:给定多智能体系统执行轨迹,归因旨在识别导致系统级失败的最可能的智能体、动作或通信消息。
4.2 Failure Taxonomy / 故障分类
从三个维度分类故障:系统结构视角(个体级、协作级、系统级);执行阶段视角(规划阶段、执行阶段、验证阶段);因果生命周期视角(直接因果、传播因果、级联因果)。
4.3 Failure Attribution Methods / 故障归因方法
# 4.3.1 Data-driven Method / 数据驱动方法
从标注执行日志学习误配置模式,典型方法包括基于对比学习的异常检测(如CAAD)和基于轨迹嵌入的分类。
# 4.3.2 Constraint-Guided Method / 约束引导方法
定义正确系统的行为约束(如消息类型约束、状态转移约束),检测违反约束的智能体。代表性工作为基于规范验证的归因。
# 4.3.3 Causal-inference Method / 因果推断方法
使用结构因果模型或反事实推理定位根因。如通过干预模型(agent action intervention)测量对最终成功率的因果效应。
4.4 Failure Attribution Evaluation / 归因评估
评估指标包括根因定位准确率(top-k)、归因效率(搜索空间缩减比例)、跨场景泛化能力。目前缺乏统一的标准化基准。
4.5 Discussion / 讨论
核心挑战包括:部分可观测性(无法完全记录所有智能体内部状态)、组合爆炸(智能体数量增加导致可能故障路径指数增长)、缺乏真实故障案例的标准化数据集。未来方向包括利用环境反馈自动构建故障场景和探索交互式归因对话。
5 Multi-Agent System Self-Evolution / 多智能体系统自演化
5.1 From Attribution to Evolution / 从归因到演化
归因识别故障根因后,演化阶段将诊断结果转化为系统结构的主动改进,实现闭环。反馈循环机制包括基于归因信号重新分配角色、调整通信模式或重编排拓扑。
5.2 Formal Definition of MAS Self-Evolution / 多智能体自演化的形式化定义
定义自演化为一个马尔可夫决策过程(S, A, R),其中状态s包括系统结构(角色、拓扑、策略)以及从归因获得的全局失败模式,动作a为可操作的演化步骤(如增加新智能体、修改角色提示、引入新通信频道),奖励r为演化后系统性能改善度量。
5.3 MAS Self-Evolution Taxonomy / 多智能体自演化分类学
# 5.3.1 Agentic Self-Evolution / 智能体级演化
个体智能体更新其提示、记忆或工具使用策略。如Mem0根据反馈更新记忆条目;Voyager通过执行结果自更新技能库。
# 5.3.2 Systemic Self-Evolution / 系统级演化
调整整体协作结构:增加/删除智能体、重新分配角色、改变通信拓扑。如MacNet使用进化算法优化角色分配;AutoGen Studio允许人类监督调整,但未来可转向自动化。
# 5.3.3 Meta Self-Evolution / 元级演化
设计演化策略本身的改进——学习学习。如使用神经架构搜索选择最佳协作协议;通过元学习优化角色分配策略。
5.4 Analyzing Evolutionary Dynamics / 演化动力学分析
使用概念性框架分析系统演化过程,包括稳定性(演化后系统性能噪声分布)、适应性(应对新任务的速度)、开销(演化计算成本)。当前缺乏形式化建模。
5.5 Evaluation / 评估
自演化评估指标包括演化效率(收敛所需轮次)、稳定性(性能方差)、泛化性(演化后系统在新任务上的表现)。代表性基准如EvolvE(多智能体持续学习基准)。
5.6 Discussion / 讨论
核心挑战包括:搜索空间巨大(可能的系统结构组合指数级)、归因噪声对演化的负面影响(错误归因导致错误改进)、缺乏安全保证(自演化可能导致系统性能退化)。未来方向包括层次化演化(先个体后系统)和与人类反馈的协同演化。
6 Conclusion / 结论
本综述围绕LIFE progression框架统一覆盖了基于LLM的多智能体系统的完整操作生命周期。我们在每个阶段提供了系统分类学,形式化描述了相邻阶段间的依赖关系,识别了阶段边界处的开放挑战,并提出了跨阶段研究议程。关键贡献包括:首次覆盖从个体能力到协作、故障归因和自主结构改进的完整生命周期;突出归因-演化闭环;识别阶段边界挑战并提供公开文献资源库(GitHub: https://github.com/mira-ai-lab/awesome-mas-life)。通过桥接之前碎片化的研究主题,本综述旨在为当前研究提供系统参考,并为自主、自我改进的多智能体智能提供概念性路线图。
原文信息
- 英文题目 Beyond Individual Intelligence: Surveying Collaboration, Failure Attribution, and Self-Evolution in LLM-based Multi-Agent Systems
- 作者 Shihao Qi, Jie Ma, Rui Xing, Wei Guo, Xiao Huang, Zhitao Gao, Jianhao Deng, Jun Liu, Lingling Zhang, Bifan Wei, Boqian Yang, Pinghui Wang, Jianwen Sun, Jing Tao, Yaqiang Wu, Hui Liu, Yu Yao, Tongliang Liu
- arXiv ID 2605.14892 (cs.AI)
- Comments/项目信息 GitHub: https://github.com/mira-ai-lab/awesome-mas-life
- 原文链接 http://arxiv.org/abs/2605.14892v1
