

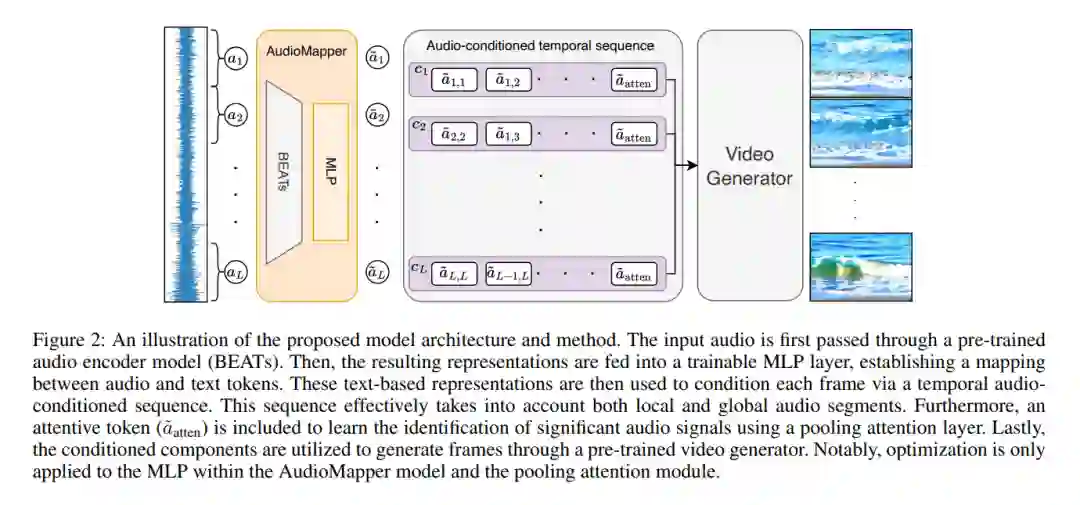
我们考虑的任务是在广泛的语义类别中,由自然音频样本引导生成多样化且真实的视频。对于这个任务,视频需要在全局和时间上与输入音频对齐:在全局上,输入音频与整个输出视频在语义上相关联;在时间上,输入音频的每个片段与该视频的相应片段相关联。我们利用了现有的基于文本条件的视频生成模型和一个预训练的音频编码器模型。所提出的方法基于一个轻量级适配器网络,它学习将基于音频的表示映射到文本到视频生成模型所期望的输入表示。因此,它也能实现基于文本、音频,以及我们所能确定的首次,基于文本和音频的视频生成。我们在三个数据集上广泛验证了我们的方法,这些数据集展示了音频视频样本的显著语义多样性,并进一步提出了一个新的评估指标(AV-Align),以评估生成视频与输入音频样本的对齐程度。AV-Align基于在两种模态中检测和比较能量峰值。与最近的最先进方法相比,我们的方法生成的视频与输入声音在内容和时间轴上更好地对齐。我们还展示了我们的方法生成的视频具有更高的视觉质量和更多样化。代码和样本可在以下网址获取:https://pages.cs.huji.ac.il/adiyoss-lab/TempoTokens。
成为VIP会员查看完整内容
相关内容
Arxiv
43+阅读 · 2023年4月19日
Arxiv
232+阅读 · 2023年4月7日
Arxiv
88+阅读 · 2023年4月4日
Arxiv
156+阅读 · 2023年3月29日
最新内容
相关VIP内容
相关资讯
相关论文
Arxiv
43+阅读 · 2023年4月19日
Arxiv
232+阅读 · 2023年4月7日
Arxiv
88+阅读 · 2023年4月4日
Arxiv
156+阅读 · 2023年3月29日