
导读
在因果发现中,“选择偏差”通常被画成一个选择变量:某些个体因为满足选择条件而进入样本,研究者只在被选择的子群体上观察数据。这样的建模对问卷响应、病例入组、幸存者偏差等问题非常有用,但它隐含了一个关键前提:选择是一次性的过滤过程。 ICML 2026 论文 Causal Modeling of Selection in Evolution 讨论的是另一类更微妙、也更常见于自然与社会系统的问题:演化选择。在演化系统中,当前样本并不是从一个固定总体中一次性筛出来的,而是经历了多代复制、适应、竞争、遗传和环境筛选之后形成的结果。免疫系统中的抗体亲和力成熟、细菌抗药性演化、生物形态适应、社会规范传播、政治观点扩散,都更接近这种“跨代累积”的选择过程。 这篇论文的核心观点很直接:静态选择与演化选择不应使用同一个因果图解释框架。如果把演化选择粗暴地当作静态选择处理,因果发现算法可能把由历史选择与遗传传播诱导出的相关性误读为直接因果关系,或者误判某个变量是否直接参与选择。作者因此提出演化选择的因果图模型,给出单域数据与多域/多环境数据下的识别理论,并在合成数据和多个真实数据集上验证了这种解释方式的优势。 这项工作值得关注,不是因为它提出了一个新的打分函数或单一算法技巧,而是因为它重新厘清了“选择”在因果建模中的语义:同样是选择,静态过滤与演化传播会诱导不同的条件独立结构,也会改变我们解释 CPDAG/PDAG 边的方式。
论文基本信息
论文标题:Causal Modeling of Selection in Evolution
中文标题:演化过程中选择机制的因果建模
论文作者:Haoyue Dai, Zeyu Tang, Peter Spirtes, Kun Zhang 论文链接:https://arxiv.org/pdf/2606.05689 会议信息:ICML 2026 研究方向:因果发现、选择偏差、演化系统、图模型、异质数据因果识别
摘要
选择偏差是因果建模中的经典问题。现有因果发现方法通常将选择建模为静态过程:样本先由某个总体生成,再根据选择变量被过滤,研究者只观察被保留下来的数据。论文指出,这种静态选择模型并不能覆盖许多演化过程中的数据生成机制,因为演化系统中的选择不是一次性发生,而是跨多个世代反复作用于复制、遗传与繁殖。 为处理这一问题,作者提出了新的演化选择图模型。该模型显式表示多代变量、选择/繁殖指标以及跨代继承噪声,并分析演化选择如何在当前观测变量之间诱导额外依赖关系。在此基础上,论文证明这些依赖关系可以通过一个 clique-augmented DAG 来刻画:凡是选择变量祖先集合中的变量,会因演化传播而形成额外的团结构依赖。 进一步地,作者给出单域数据和多域数据下的模型识别方法。单域情况下,可以运行标准 PC 或 GES 等因果发现算法,但必须改变对输出 CPDAG 的解释;多域情况下,可以借助环境/世代变化变量进一步定向部分因果边。实验显示,相比把所有邻接边都解释为直接因果关系的标准做法,作者的解释方式在合成数据上获得更高、更稳定的因果邻接精度,并在真实生物、形态、农业和社会调查数据中得到有意义的结构解释。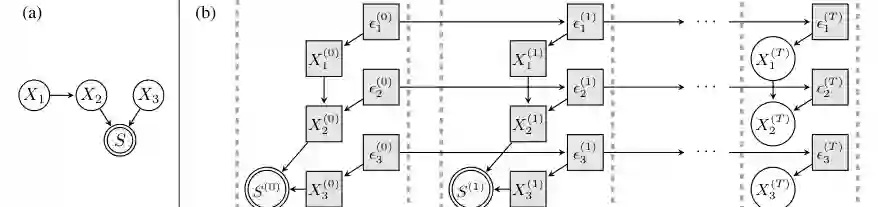
引言:为什么需要重新建模“选择”
静态选择只描述一次过滤
在经典选择偏差模型中,研究者通常假设存在一个潜在总体,数据点先由某个因果机制生成,然后因为是否满足选择条件而进入样本。例如,健康调查中只有愿意响应的人被记录,医院数据中只有就诊患者被记录,线上平台数据中只有活跃用户被记录。图模型中常把这种机制表示为一个选择节点 S,并在分析时条件化在 S=1 上。 这种设定的语义是:选择发生在样本生成之后,是一次性的过滤。它擅长解释“为什么观测样本不是总体的无偏抽样”,也能刻画条件化在选择节点上导致的碰撞路径打开、伪相关产生等现象。 但在演化过程里,数据不是这样来的。当前观测到的个体、性状或观点,往往不是从固定总体中筛选出来,而是前几代个体在环境中竞争、繁殖、遗传、突变之后留下的结果。选择不仅决定“谁被观察到”,还决定“谁能把自身特征传到下一代”。因此,选择机制会通过跨代传播改变当前总体本身。
演化选择会把历史路径压缩到当前数据中
论文用“演化选择”描述这种反复发生的机制。设想第 t 代的变量 X^(t) 会影响该代个体的繁殖或存续,选择指标 S^(t) 决定哪些个体进入下一代;下一代变量 X^(t+1) 又通过继承噪声、遗传扰动和同一代因果机制生成。经过 T 代之后,研究者只观察最终的 X^(T)。 这时,当前变量之间的相关性不只来自同代因果关系,还来自历史选择造成的群体结构改变。例如两个性状可能并无直接因果关系,但如果它们共同影响繁殖成功,经过多代选择后,最终存活群体中这两个性状会呈现特殊依赖。把这种依赖解释为普通静态选择或直接因果边,就会产生系统性误判。 论文强调,这一误判并非小问题,而是会影响因果发现结果的语义。常规 PC/GES 输出的邻接边,在演化选择数据中不一定都代表直接因果关系;某些无向边可能只是提示这些变量共同处在选择相关的祖先团中。
论文的三个贡献
第一,论文形式化地区分了静态选择与演化选择,给出能够表示跨代复制、选择与继承的因果图模型。 第二,论文证明了演化选择诱导的条件独立结构可以通过 clique-augmented DAG 表示,并据此建立单域数据下的识别理论。重要的是,标准因果发现算法可以继续使用,但输出图的解释必须改变。 第三,论文将模型推广到多域或多环境数据,引入表示环境/世代差异的辅助变量,说明异质性如何帮助定向更多因果边,并在合成与真实数据上验证了方法。
方法:演化选择图模型
从跨代 DAG 开始
论文首先构造一个包含多个世代的演化图 G^(T)。每一代都有一组观测变量 X^(t),也有影响下一代生成的继承噪声或外生因素 ε^(t)。选择变量 S^(t) 表示该代个体是否参与繁殖、存续或传播。最终研究者观察的是第 T 代的 X^(T),而早期世代、选择过程和继承噪声通常不可观测。 这种建模把演化过程拆成三类机制:
- 同代因果机制:同一世代内,变量之间可能存在因果影响,例如性状 A 影响性状 B。
- 选择/适应机制:某些变量影响个体能否留下后代、被复制或继续传播。
- 跨代继承机制:上一代的性状和噪声通过遗传、学习、模仿或制度传递影响下一代。
静态选择模型只捕捉第二类机制中的“过滤”含义,而演化选择模型把第二类机制和第三类机制耦合起来:被选择的不只是样本,还是下一代数据生成过程的输入。
运行示例:一个小 DAG 如何被重新解释
论文使用一个包含 X1 到 X5 以及选择变量 S 的小图作为后续理论说明的运行示例。这个图在静态选择视角下可以被看成普通因果图加一个选择节点;但在演化选择视角下,S 的祖先变量会通过跨代复制和选择形成额外依赖。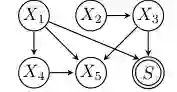
clique-augmented DAG:用团结构表示演化选择诱导依赖
论文的关键技术工具是 clique-augmented DAG,可译为“团增强有向无环图”。构造方式如下:从原始 DAG G 出发,找出选择变量 S 的祖先集合 an_G(S)。在这些选择祖先之间,根据拓扑顺序添加额外有向边,使它们形成一个团状结构。得到的新图记为 G^+。 这个构造看似简单,但理论意义很强。论文证明:对于最终观测数据中能够检验的条件独立关系,演化选择图 G^(T) 中的 d-分离关系,可以由团增强图 G^+ 中的 d-分离关系等价表示。换言之,复杂跨代演化过程对当前观测分布造成的依赖,可以被压缩成一个只包含当前变量的图结构。 这个结果有三层含义。 第一,研究者不必知道真实演化经历了多少代 T,也不必假设系统已经达到某种平衡态。只要演化选择模型成立,当前观测数据中的条件独立结构就可以通过 G^+ 表示。 第二,当繁殖或复制完全随机、选择机制不起作用时,G^+ 会退化回原始图 G。也就是说,该框架包含了“没有选择”的普通因果发现情形。 第三,也是最重要的一点:仅凭观测数据通常无法确认选择确实存在,只能在某些情况下排除变量参与选择的可能。原因是某些由选择产生的依赖结构,也可以由没有选择但带有额外因果边的图解释。因此,演化选择的识别结论必须谨慎表达。
单域数据:算法可以照跑,解释必须改变
在单一环境、单一世代观测数据中,作者提出的识别思路非常克制:不需要发明一个完全新的搜索算法,而是可以直接运行 PC、GES 等标准因果发现算法,得到观测变量 X 上的 CPDAG。真正变化发生在解释阶段。 标准解释通常把 CPDAG 中的邻接关系视为潜在直接因果关系,把有向边视为可识别方向。但在演化选择下,邻接边还有另一种解释:两个变量可能共同处在选择变量的祖先团中,因此它们之间的相邻并不保证存在直接因果边。 论文的 Algorithm 1 可以概括为:
- 输入观测数据矩阵 X。
- 在因果充分性与 faithfulness 等假设下,对 X 运行 PC 或 GES。
- 输出 X 上的 CPDAG。
- 对输出图使用演化选择语义解释:有向边可以在特定条件下被解释为真实因果方向;无向邻接则可能是直接因果、共同选择祖先关系,或两者同时存在。
图3:单域数据中的模型识别示意。左侧是由运行示例构造的 clique-augmented DAG,粗边表示为选择祖先添加的团增强边;右侧是算法在单域数据上输出的 CPDAG。 这带来一个很实用的警示:在演化选择数据中,标准因果发现算法的输出并不是“错”的,错的是把它当作静态或无选择场景下的因果图来读。论文将这种区别总结为三种容易出错的场景。 第一,完全忽略选择。研究者只运行 PC/GES,并把所有邻接边解释为直接因果关系。这会高估直接因果边数量。 第二,把选择当作静态选择处理。研究者知道有选择,但采用 MAG/FCI 等静态选择或潜变量框架直接分析。论文指出,这种做法可能既不充分也不可靠,因为演化图有特殊的跨代结构约束,不能简单套用静态选择语义。 第三,承认演化存在却沿用通用 MAG-FCI 流程。即使建模方向更接近真实过程,如果没有利用演化选择图的特殊结构,也可能错过本来可识别的关系。
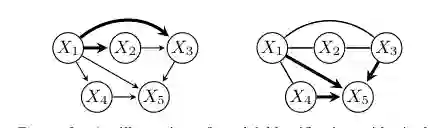 图3:单域数据中的模型识别示意。左侧是由运行示例构造的 clique-augmented DAG,粗边表示为选择祖先添加的团增强边;右侧是算法在单域数据上输出的 CPDAG。 这带来一个很实用的警示:在演化选择数据中,标准因果发现算法的输出并不是“错”的,错的是把它当作静态或无选择场景下的因果图来读。论文将这种区别总结为三种容易出错的场景。 第一,完全忽略选择。研究者只运行 PC/GES,并把所有邻接边解释为直接因果关系。这会高估直接因果边数量。 第二,把选择当作静态选择处理。研究者知道有选择,但采用 MAG/FCI 等静态选择或潜变量框架直接分析。论文指出,这种做法可能既不充分也不可靠,因为演化图有特殊的跨代结构约束,不能简单套用静态选择语义。 第三,承认演化存在却沿用通用 MAG-FCI 流程。即使建模方向更接近真实过程,如果没有利用演化选择图的特殊结构,也可能错过本来可识别的关系。
图3:单域数据中的模型识别示意。左侧是由运行示例构造的 clique-augmented DAG,粗边表示为选择祖先添加的团增强边;右侧是算法在单域数据上输出的 CPDAG。 这带来一个很实用的警示:在演化选择数据中,标准因果发现算法的输出并不是“错”的,错的是把它当作静态或无选择场景下的因果图来读。论文将这种区别总结为三种容易出错的场景。 第一,完全忽略选择。研究者只运行 PC/GES,并把所有邻接边解释为直接因果关系。这会高估直接因果边数量。 第二,把选择当作静态选择处理。研究者知道有选择,但采用 MAG/FCI 等静态选择或潜变量框架直接分析。论文指出,这种做法可能既不充分也不可靠,因为演化图有特殊的跨代结构约束,不能简单套用静态选择语义。 第三,承认演化存在却沿用通用 MAG-FCI 流程。即使建模方向更接近真实过程,如果没有利用演化选择图的特殊结构,也可能错过本来可识别的关系。识别结论:有向边更可靠,无向边要谨慎
论文的 Theorem 2 给出单域算法的可靠性与完备性解释。简化地说:
- 如果输出 CPDAG 中存在有向边 X_i -> X_j,那么在相应条件下,该方向可以被视为真实因果方向,并且 X_j 不参与选择祖先团中的相关混淆解释。
- 如果输出中只有无向边 X_i - X_j,那么不能进一步区分它究竟是直接因果、共同选择祖先关系,还是二者兼有。
- 因此,演化选择下的 CPDAG 更适合被读成“保守因果图”:它告诉我们哪些方向可确认、哪些相邻关系仍需保留多种解释。
这一点对应用非常重要。很多科学领域真正关心的不是得到一张边很多的图,而是避免把选择造成的群体结构误读成机制性因果。论文的方法牺牲了一些看似确定的边,换来更稳健的解释边界。
方法推广:多域数据如何提升可识别性
多个环境带来额外信息
实际演化数据常常不止来自一个环境。研究者可能观察不同地区、不同时间、不同物种群体、不同政策环境或不同实验条件下的数据。论文将这些差异称为 domain,并用辅助变量 ζ 表示域信息。 多域数据的价值在于:如果某些因果机制或选择机制在不同域之间发生变化,那么这些变化会在条件分布中留下可检验的不变性与差异性信号。已有异质数据因果发现方法,如 CDNOD,正是利用域变量与观测变量之间的关系来识别机制变化。论文把这种思想嵌入演化选择框架。
multi-domain clique-augmented DAG
在多域场景中,作者构造 multi-domain clique-augmented DAG,记为 G^{+I}。它在单域 G^+ 的基础上加入域变量 ζ,并让 ζ 指向机制发生变化的变量。如果选择机制本身发生变化,还需要从 ζ 指向选择祖先集合中的相关变量,以表示选择变化通过演化过程影响观测分布。 这一构造的作用是把“环境改变了什么机制”编码到图中。与单域数据相比,多域数据不仅利用条件独立,还利用跨域不变性,从而可能定向更多边。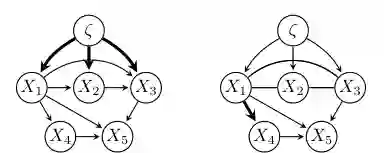
- 输入多个域中的观测数据,以及共同变量集合 X。
- 引入域变量 ζ 表示样本来自哪个环境或世代。
- 运行 CDNOD 或可比较的多域因果发现方法。
- 输出 X ∪ {ζ} 上的 PDAG。
- 将输出图按演化选择语义解释,特别关注哪些边因异质性而获得额外方向信息。
在运行示例中,多域信息帮助识别了单域数据中无法定向的边,例如 X1 -> X4。直观原因是,如果某个机制随环境变化,而这种变化只会通过特定方向传播,那么域变量与观测变量之间的不变性/依赖模式就能提供方向线索。
仍然不能“证明选择存在”
值得注意的是,多域数据虽然增强了识别能力,但并不能彻底解决“选择是否存在”的确认问题。论文强调,即使观察到与演化选择一致的依赖结构,也可能存在没有选择但结构不同的因果图产生相同观测约束。因此,数据本身往往只能排除某些选择参与解释,而不能单独证明某个变量一定参与选择。 这并不削弱方法价值,反而让结论更科学:该框架不是宣称从观测数据中神奇恢复完整演化史,而是明确告诉研究者哪些因果方向可以确认、哪些相邻关系必须保留选择解释、哪些结论需要额外领域知识或实验干预支持。
实验:合成数据与真实数据验证
合成数据设置
论文首先在合成数据上验证理论解释是否能提高因果邻接恢复的精度。作者随机生成 Erdős-Rényi 图,变量维度 d 取 10、15、20,平均度约为 2。为模拟偏好适应或繁殖适合度,作者加入选择变量 S,并令它随机选择 d/5 个父节点。随后使用线性结构方程模型生成同代变量,并让每一代个体根据选择得分产生 0 到 5 个后代。 与静态选择中“样本被 S 过滤”不同,这里每个第 t 代样本会根据其选择表现影响第 t+1 代个体数量。下一代个体继承上一代噪声并叠加新的高斯扰动,再由同一 SEM 生成变量。重复 T 代后,最终观测数据自然包含演化选择留下的依赖结构。 比较方法包括 PC 和 GES。关键不是只比较算法本身,而是比较两种解释方式:
- 标准解释:把算法输出中的邻接关系都视为直接因果关系。
- 作者解释:按演化选择理论,只把满足条件的有向关系视为可确认因果,把可能由选择祖先团造成的邻接关系保守处理。
合成结果:保守解释带来更高精度
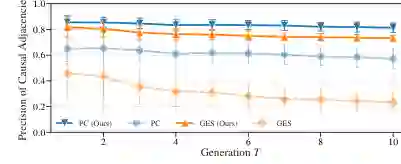
真实数据:七个数据集上的结构解释
论文还在七个真实数据集上进行评估,包括 Drosophila 基因表达数据 DGRP、头骨形态数据 Cranial、玉米农艺形态数据 Panzea、哺乳动物表型数据 PanTHERIA、鸟类形态数据 AVONET、比较选举系统调查 CSES,以及美国人口普查微观数据 PUMS。 由于真实世界缺少“演化选择相关因果图”的可靠 ground truth,作者没有做强行量化评估,而是展示学到的 CPDAG/PDAG 子图,并结合领域知识给出解释。这一点处理得比较规范:论文没有把真实数据实验包装成完全验证,而是把它定位为可解释结构发现。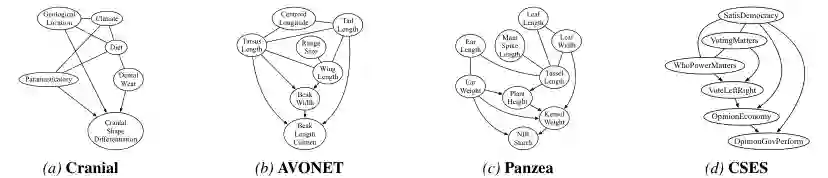
关键启发:这篇论文改变了什么
选择偏差不是一个单一概念
论文最重要的概念贡献,是把“选择”拆成了两种不同语义。静态选择关注样本进入观察集的概率,演化选择关注哪些个体、性状、观点或机制能够被复制到未来。前者是横截面过滤,后者是跨代传播。 这一区分会影响图模型结构,也会影响因果发现输出的解释。过去很多工作可能在数据明显来自演化系统时,仍默认使用静态选择语义。论文指出,这会让研究者把历史选择诱导的依赖误读为直接机制。
标准算法仍有用,但不应机械解释
一个很有实践价值的结论是:面对演化选择数据,研究者不一定要丢掉 PC、GES、CDNOD 等已有工具。论文显示,在适当理论解释下,这些工具仍可作为图恢复步骤使用。真正需要改变的是下游语义解释:哪些边代表直接因果,哪些边只是选择祖先团中的统计依赖。 这对于应用研究者尤其友好。很多领域已经有成熟的因果发现流程和软件,论文提供的是一套新的解释协议,而不是要求所有人从零实现复杂算法。
有向边与无向边的含义更加分化
在普通 CPDAG 解释中,无向边往往意味着 Markov 等价类中的方向不可定;在演化选择框架下,无向边还多了一层含义:它可能不是单纯的方向不确定,而是直接因果与共同选择祖先关系之间不可区分。因此,无向边不能被轻易翻译成“存在某个方向的因果边”。 这种分化使输出图更保守,也更贴近科学推断的实际需要。在没有干预或额外背景知识时,承认不可区分性比给出过度确定的因果图更可靠。
多域数据是演化因果发现的重要方向
多域推广说明,环境差异、时间差异和群体差异并非只是噪声,也可以成为识别因果机制的资源。如果某些机制在不同域中改变,而其他机制保持不变,这些变化模式能够提供方向信息。 这与现代因果发现中的不变性思想高度一致:因果机制通常在环境变化下具有某些稳定性,而非因果相关更容易随环境改变。论文把这一思想放进演化选择语义中,为研究跨物种、跨地区、跨世代、跨政策环境的数据提供了统一图模型。
局限性与适用边界
论文对局限性保持了比较清醒的态度。 首先,模型依赖图模型常见假设,包括因果充分性、faithfulness、机制稳定性以及特定形式的继承结构。若真实系统存在强隐藏混杂、复杂反馈、非 DAG 动态或依赖继承,理论保证会削弱。 其次,选择存在性不能仅由观测数据确认。演化选择模型可以解释某些依赖模式,但同样的观测条件独立结构可能由其他无选择因果图产生。因此,实际应用中仍需要领域知识、实验设计或额外数据支持。 再次,真实数据实验主要是定性解释。由于缺乏演化选择相关的 ground-truth 因果图,论文无法在真实数据上严格量化因果恢复准确率。这并不是作者方法的独有问题,而是整个演化因果发现领域面临的评估难题。 最后,论文主要处理的是图结构识别与解释问题,而不是估计具体因果效应大小。若研究目标是干预效应估计,还需要在识别图结构之后结合更具体的结构方程、参数模型或干预数据。
结论
Causal Modeling of Selection in Evolution 的价值在于,它把一个经常被混用的概念重新拆开:静态选择不是演化选择,样本过滤不是跨代复制,条件化选择节点也不能完全解释演化过程诱导出的依赖结构。 论文提出的演化选择图模型和 clique-augmented DAG,为复杂跨代选择过程提供了可操作的因果发现语义。它告诉我们:标准算法可以继续使用,但输出图不能照旧解释;有向边可以更积极地用于因果判断,无向邻接则必须保留选择诱导依赖的可能。 对于研究生物演化、适应性系统、社会传播、文化演化、政策反馈和长期动态数据的研究者来说,这篇论文提供了一套非常重要的提醒:当数据本身是历史选择的产物时,因果发现不能只看当前变量之间的相关结构,还必须问这些结构是如何被一代又一代选择塑造出来的。
原文信息
论文标题:Causal Modeling of Selection in Evolution 作者:Haoyue Dai, Zeyu Tang, Peter Spirtes, Kun Zhang 论文链接:https://arxiv.org/pdf/2606.05689 会议:ICML 2026