复旦大学研究人员开发了Task-to-Quiz (T2Q),这是一个自动化的范式,用于评估大型语言模型(LLM)代理的环境理解能力,并将其与任务完成指标分开。该框架揭示了任务成功并不能可靠地反映代理的扎实世界模型,指出了现有记忆系统的不足,并强调了主动探索不足是形成全面环境知识的一个主要局限。

引言 大型语言模型(LLM)代理在从网页导航到软件工程等多个领域都展现出了令人印象深刻的能力。然而,一个基本问题仍然存在:这些代理是否真正理解它们的环境,还是它们仅仅擅长特定任务行为而没有发展出强大的世界模型?本文介绍了任务到测验(Task-to-Quiz,T2Q),这是一种将“做”与“知”分离的范式,旨在评估LLM代理是否真正理解其操作环境,而不仅仅是完成任务。 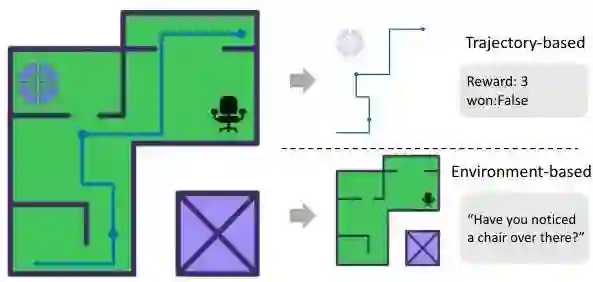
任务到测验(T2Q)范式
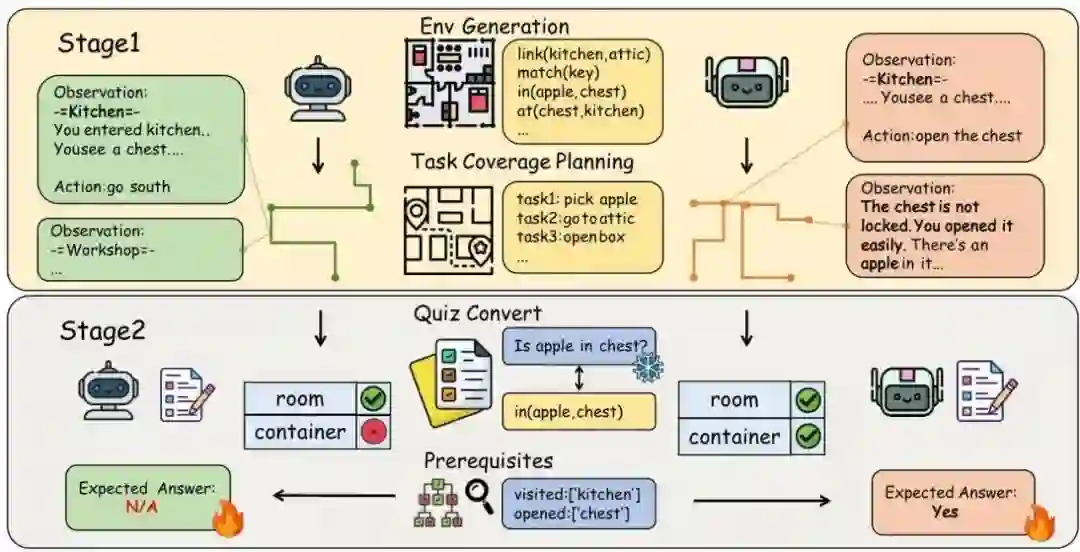
T2Q范式通过一个两阶段过程解决了这个评估差距,该过程将任务执行与环境理解解耦。这种方法利用基于文本的冒险游戏,其中环境元数据是明确已知的,从而能够进行精确和自动化的评估。 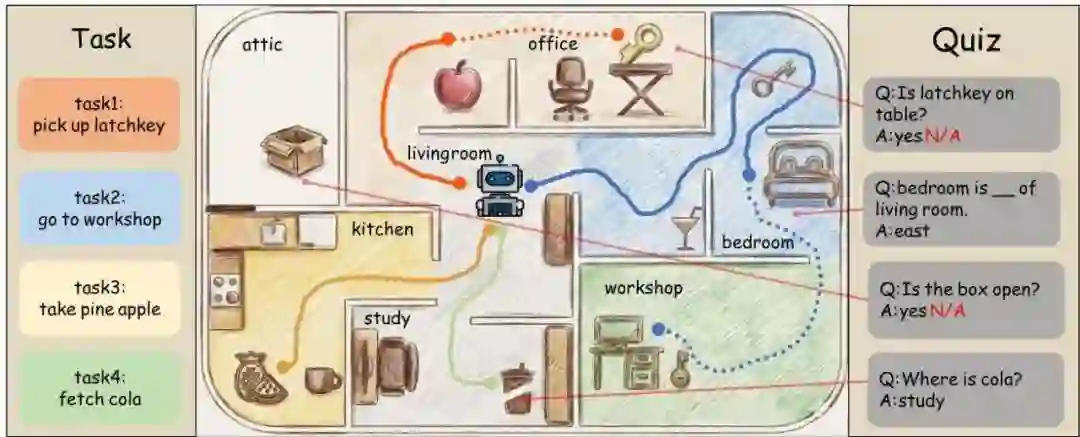
环境构建
该方法始于使用TextWorld风格游戏进行可控环境生成。每个环境都包括:
- 布局和连接性:明确定义的房间和连接,形成已知的图结构
- 可达性设计:生成后通过注入锁-钥匙依赖关系进行细化,以强制多步骤规划
- 干扰物放置:添加不相关的对象以增加推理难度,而不影响核心可解性
任务覆盖规划
为确保全面探索,作者将任务生成表述为加权集合覆盖问题。该过程包括:
- 覆盖签名生成:每个潜在任务都关联一个签名,表明它涉及哪些房间和实体
- 贪婪选择:选择任务以最大化可达房间和交互实体的覆盖范围
- 演练验证:参考解决方案轨迹确保任务的可行性
这种方法生成“面向覆盖的任务”,鼓励代理探索环境的不同方面,而不是专注于单一目标。
测验生成和动态真实性
系统自动将环境事实转换为五类问答对:
- 位置:“苹果在哪里?”
- 连接性:“厨房连接到哪些房间?”
- 方向:“卧室在客厅的___。”
- 匹配:“这把钥匙能打开这把锁吗?”
- 属性:“盒子是开着的吗?”
至关重要的是,每个问题都包含先决条件检查点——代理合理地知道答案所需的最小交互证据。系统生成动态真实性:如果代理没有满足先决条件(例如,从未访问过某个房间),那么对于该轨迹,该问题就变为“无法回答”,从而确保公平评估。
实验框架和T2QBench
-
30个按难度分层的程序生成环境
-
224个旨在最大化环境交互的覆盖导向任务
-
1,967个基于环境的问答对,带有动态真实值分配
评估通过两个不同的阶段进行: 第一阶段:任务成功率 (TSR) - 智能体执行覆盖导向任务,成功率以完成任务的比例衡量。此阶段生成交互轨迹并更新智能体记忆。 第二阶段:环境理解得分 (EUS) - 根据累积的记忆或交互历史,智能体回答测验问题。EUS 计算为正确答案与可回答问题数的比例。
关键实验发现
使用专有模型 (GPT-5.1) 和开源模型 (DeepSeekV3.2, GLM-4.6, Qwen3-32B) 以及各种记忆系统进行的广泛实验揭示了三个关键见解:
任务成功率与环境理解得分关联性差
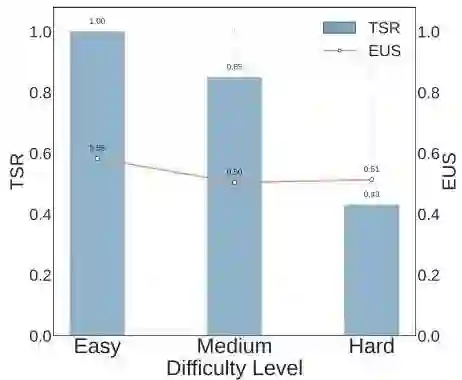
记忆系统效果有限
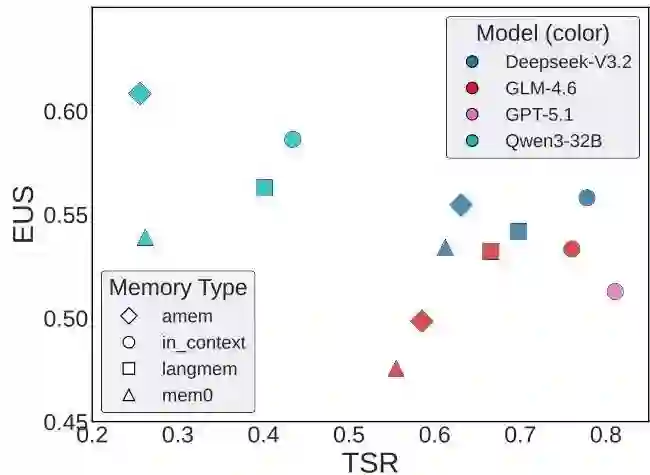
主动探索是主要瓶颈
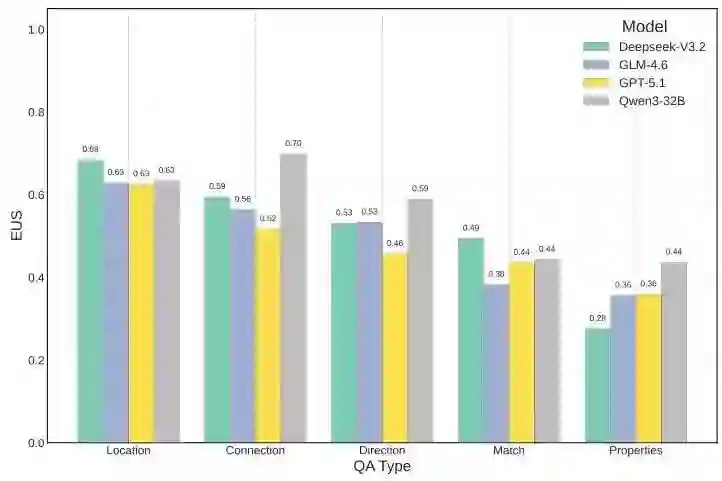
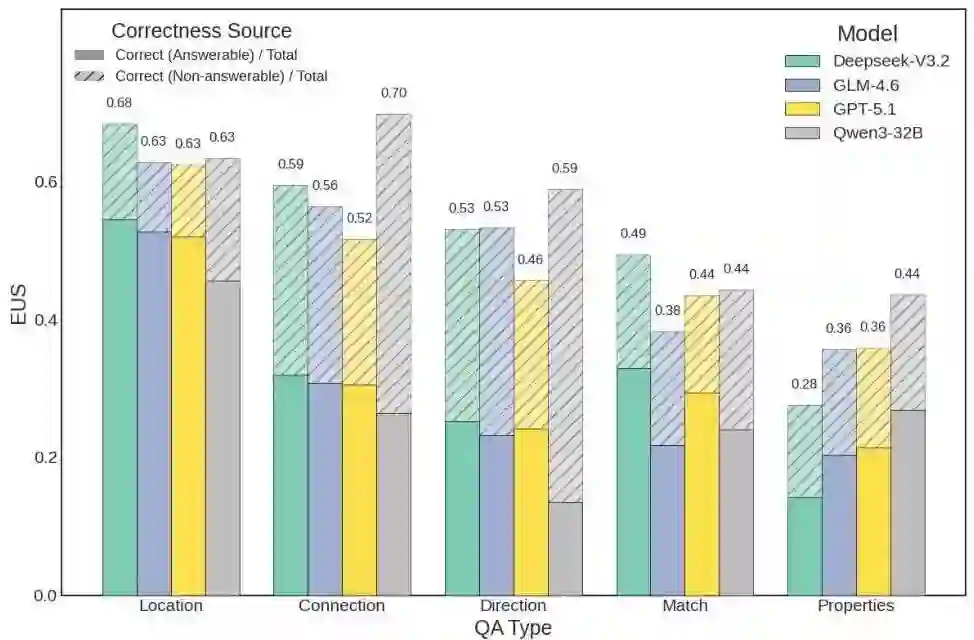
- 位置问题:表现相对较高(60-68%准确率),因为答案通常源于近期观察
- 连接性和方向:表现中等(46-59%),需要多轮推理
- 属性问题:表现持续不佳(28-44%),需要主动交互才能揭示潜在物体状态
所有模型在“属性”问题上持续的低性能表明,代理优化的是高效的、目标导向的行为,而非全面的探索。它们无法主动发现隐藏的环境细节,这代表着世界模型形成中的一个根本性局限。
启示与未来方向