
在计算机视觉中,像素级推理(如分割、深度估计)是基础但关键的任务。然而,现有视觉基础模型(例如 DINO 系列)虽然能编码丰富的语义和几何属性,但输出的往往是 patch 级别的低分辨率特征图,无法直接得到每个像素的精细特征。虽然可以通过上采样来获得高分辨率的特征,但这种方法在训练和推理时存在分辨率不一致的问题,且计算效率不高。同时,基于图像的预训练忽略视频中的动态元素,而基于视频的预训练又往往聚焦于动作级推理,难以扩展到密集像素预测。这意味着,一种能够同时捕获语义、几何和时序特性,且在推理时仅需单帧图像的像素级表示,仍是一个开放问题。
来自多家机构的研究者(Nikita Araslanov、Martin Sundermeyer、Hidenobu Matsuki、David Joseph Tan、Federico Tombari)在 CVPR 2026(口头报告)上提出了 LILA 框架,其核心创新是线性上下文学习(Linear In-Context Learning)。该方法利用无标签视频中离线估计的深度和光流线索图作为监督信号——尽管这些线索图存在噪声——却能高效地训练一个编码器-解码器模型,生成兼具几何、语义和时间一致性的高分辨率像素级特征。值得注意的是,LILA 在推理阶段仅需要单张图像作为输入,这使其与许多依赖时空输入的视频预训练方法形成了鲜明对比。 这篇论文的价值在于,它不仅为像素级表示学习提供了一种新颖的、可扩展的训练范式,还在视频目标分割、表面法线估计和语义分割三个截然不同的密集预测任务上展示了显著的优势。对于从事自/弱监督学习、视频理解、像素级预测(如分割、深度估计)的研究者和学生来说,LILA 提供了一条富有启发性的路径。
论文基本信息

原文链接 http://arxiv.org/abs/2604.26488v1
摘要
视觉模型最令人兴奋的应用之一涉及像素级推理。尽管目前已有大量的视觉基础模型,但我们仍然缺少能够有效嵌入视觉场景时空属性的像素级表示。现有的框架要么在基于图像的前置任务上训练,忽略动态元素;要么在视频序列上进行动作级推理,无法扩展到密集的像素级预测。本文提出了 LILA,一个从视频中学习逐像素精确特征描述子的框架。其训练框架的核心是线性上下文学习(Linear In-Context Learning)。LILA 利用由现成网络估计的时空线索图(深度和光流)作为监督信号。尽管这些线索带有噪声,LILA 仍能在未经筛选的视频数据集上有效训练,以时间一致的方式嵌入语义和几何属性。我们在多个视觉任务上展示了所学表示的显著实证优势:视频目标分割、表面法线估计和语义分割。
引言:论文要解决什么问题
大多数计算机视觉任务需要像素级的特征表示,同时嵌入视觉场景的语义和几何属性。尽管最先进的基础模型(如 DINO [1–3])已经编码了相当程度的这些属性,但这些编码器模型输出的特征图是低分辨率的 patch 级别。为了直接获得像素精细的特征网格,一种直接做法是将输入按 patch 大小进行上采样。然而,这种做法在实际中既不具备计算效率,也难以达到任务所需的效果,因为它引入了训练和推理时输入分辨率的不匹配。 此外,现有的表示学习范式存在明显的缺口。基于图像的预训练(如 MoCo、BYOL、DINO)以静态图像为目标,无法捕捉视频中丰富的运动线索;而基于视频的预训练方法(如一些使用时空输入的方法)在推理时往往需要多帧输入,且无法扩展到需要单帧单输出图像的密集像素预测任务。 针对上述痛点,本文提出一种针对编码器-解码器架构的全新训练策略,该架构能够原生地为每个输入像素计算特征向量。核心创新在于线性上下文学习:通过一个线性投影将不同帧的特征映射到一致的线索图(如深度图),从而迫使模型学习时间上稳定的表示。与之前依赖 mask 监督的上采样方法不同,LILA 利用现成的深度估计和光流网络(虽然这些网络预测存在噪声)生成训练信号,大幅降低了标注成本。通过这种方式,LILA 在保留图像级预训练优势的同时,额外赋予了像素级表示以几何和时序属性。
配图:问题背景
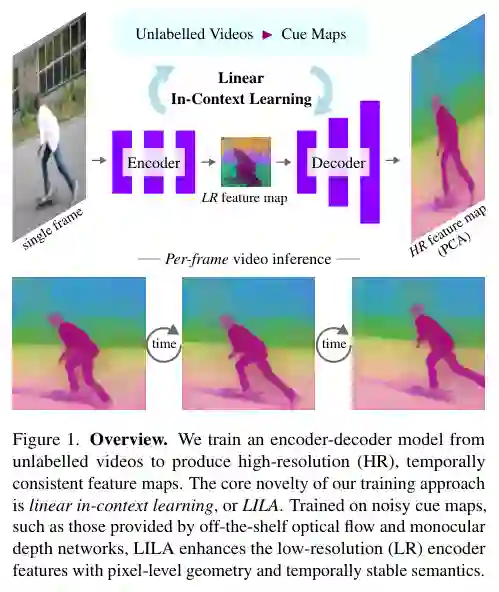
方法:核心思路与技术路线
LILA 的整体框架采用编码器-解码器架构,其训练过程围绕线性上下文学习展开。本节按模块和步骤详细拆解。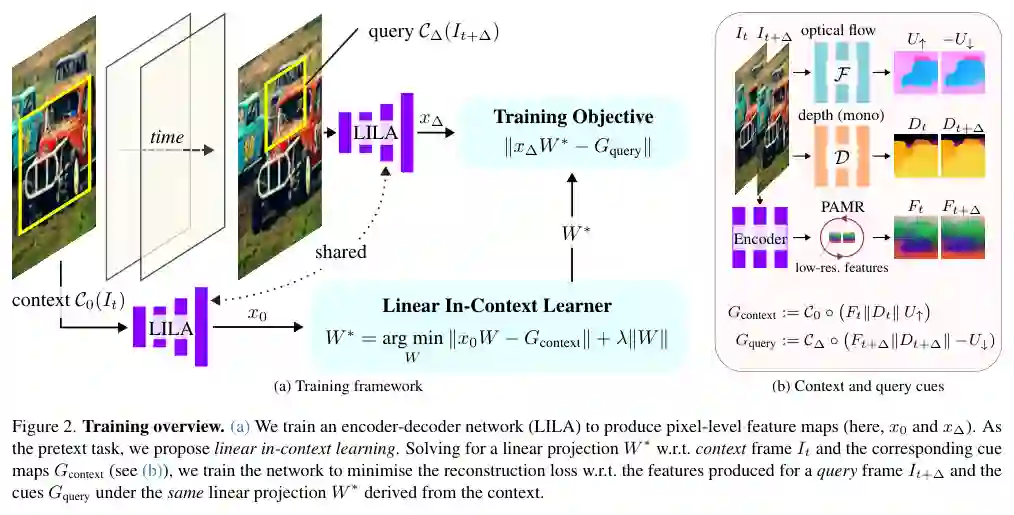
1. 编码器-解码器架构
- 编码器 采用类似于 DINO 系列的视觉 Transformer 作为主干,输出低分辨率(LR)的 patch 级特征图。
- 解码器 通常由轻量级的卷积反卷积或 Transformer 模块组成,将 LR 特征图上采样为高分辨率(HR)特征图,为每个像素输出一个 d 维特征向量。
2. 线性上下文学习的核心思想
设给定一段无标签视频片段,包含两帧 ( I_a ) 和 ( I_b )。对于每一帧,我们使用现成的离线网络(如预训练的单目深度估计网络和光流网络)生成对应的线索图(深度图 ( D_a, D_b ) 和光流图 ( F_a, F_b ))。这些线索图是有噪声的,但携带了丰富的几何和运动信息。 LILA 的训练目标如下:首先将编码器-解码器模型应用于帧 ( I_a ),得到高分辨率特征图 ( H_a )。然后,我们学习一个线性投影矩阵 W(对所有帧共享),使得 ( W \cdot H_a \approx C_a ),其中 ( C_a ) 是 ( I_a ) 的某个线索图(例如深度图)。关键在于,使用同一个 W 对另一个帧 ( I_b ) 的特征图 ( H_b ) 进行投影时,也能得到与其对应的线索图 ( C_b )。 由于 W 是线性且共享的,模型必须学习到使不同帧的特征 ( H_a ) 和 ( H_b ) 在线性投影下保持一致的表示。这意味着特征编码了与线索(深度、运动)相关的齐次属性,从而在时间上具有一致性。
3. 多模态线索与自蒸馏
为了同时嵌入几何和语义属性,LILA 同时使用深度和光流两种模态的线索图。此外,模型还引入了自蒸馏机制:将编码器输出的低分辨率特征通过一个额外的投影头进行上采样,使其与解码器输出的高分辨率特征对齐。这种设计可以进一步增强编码器本身的高分辨率表达能力。
4. 训练细节
- 数据 未标注的视频数据集,直接从互联网获取或使用现有的视频数据集。
- 监督信号 离线生成的深度图和光流图(使用现成的预训练网络,如 MiDaS 和 RAFT)。这些预测结果包含噪声和伪影,但 LILA 的线性投影机制本身能够容忍一定程度的噪声,因为共享的线性投影迫使模型忽略不一致的噪声。
- 损失函数 对比或回归损失,使投影后的特征与线索图之间的误差最小化。具体损失设计(如 L1、余弦相似度等)在原文中展开,但核心思想是线性投影的一致性。
5. 推理差异
LILA 的一个重要特性是:训练时依赖视频和线索图,但推理时仅需单帧图像。编码器-解码器直接对该帧生成高分辨率特征图,无需任何额外的时序输入或后处理。这使得 LILA 可以轻松应用于静态图像的下游任务。
配图:方法结构

实验:设置、指标与结果
原文未明确说明具体的实验设置细节(如使用的数据集名称、评估指标的具体定义、训练超参数等)。但论文在多个视觉任务上报告了主要结果,并指出相比已建立的基线取得了一致且显著的改进。
主要结果
LILA 在以下三个基准上进行评估,每个任务都不同于训练时所使用的线索模态:
- 视频目标分割(Video Object Segmentation)
评估模型在视频序列中分割目标物体的能力,需要特征具有时间一致性。LILA 在该任务上相对于基于图像预训练的基线(如 DINO)取得了显著提升。
- 表面法线估计(Surface Normal Estimation)
需要从单帧图像中估计每个像素的表面法线,强调几何理解能力。LILA 的特征几何属性在此任务上得到验证。
- 语义分割(Semantic Segmentation)
密集像素级的分类任务,需要语义属性。LILA 在常见语义分割基准上也优于对比方法。 原文并未给出具体的数值(如 mIoU、F 值等),但明确表示“一致和显著的改进(consistent and significant improvement)”。
消融分析与附加研究
原文未明确说明消融实验或详细分析。但从方法特性可以推测,消融的可能方向包括:去除自蒸馏、仅使用深度或光流一种线索、不使用线性上下文学习等。然而,这些细节在论文材料中未被提及,因此本文如实记录为“原文未明确说明”。
配图:实验结果

结论:贡献、局限与启发
贡献
LILA 的主要贡献有两个方面:
- 提出了一种新颖的训练技术——线性上下文学习。该方法使编码器-解码器模型能够从无标签视频中学习,生成具有强大几何、语义和时序属性的高分辨率特征图。
- 全面评估了 LILA 在三个与训练线索模态不同的任务上的表现:视频目标分割、表面法线估计和语义分割。所有任务上都实现了相对于已建立基线的显著改进。
局限性
原文未明确讨论局限性。但从方法本身可以合理推断潜在的不足:第一,依赖离线深度和光流网络的质量——虽然 LILA 能容忍噪声,但极端噪声(如遮挡区域、运动模糊严重时)可能仍然会影响学习;第二,线性上下文学习假设特征在线性投影下与线索图一致,对于某些复杂场景(如非刚性变形)可能过于严格;第三,训练需要视频数据,尽管无标签,但仍需存储和计算开销。不过这些推测不属于论文明确结论,因此本文不将其作为正式局限性陈述。
启发
LILA 的工作为像素级表示学习开辟了一条新道路:巧妙利用视频中的时间维度作为自由监督信号,仅通过线性投影的一致性约束就学到了复杂的时空表征。其“训练用视频、推理用单帧”的特点极具实用价值。未来工作可能探索更复杂的投影形式(如非线性)、结合更多的模态(如语义分割的弱监督信号),或者将 LILA 扩展到更广泛的密集预测任务(如 3D 重建、场景流动估计)。