随着人工智能赋能系统日益融入现代工作体系,政府机构也正将人工智能能力整合至其工作流程中。美战争部致力于开发一个结构完善、高效的评价流程,以识别并优先考虑其人工智能模型的应用场景。为实现人工智能在战争部系统中最有效的应用,评估流程应始于对候选人工智能用例的审查,清晰阐明其任务影响与技术风险,为后续筛选与投资决策提供依据。传统上,用例评估由人类领域专家执行,但此评估过程可能耗费大量人力与时间,且专家评估的差异可能导致非预期的偏差。大型语言模型的最新进展及其可用性,为增强专家评估流程以提升速度与可重复性提供了机遇,但大型语言模型亦存在其自身挑战,且其在战争部语境下与人类评估的一致性尚未得到检验。本文通过一项实证研究,使用一组精心筛选的战争部人工智能应用用例,对比了人类专家与大型语言模型增强的评估结果。团队为人类领域专家和经过提示的大型语言模型提供了具体指导,要求其根据实施可行性与任务影响标准对每个用例进行评分。通过分析人类与大型语言模型辅助评估的结果,研究了两组间的评估模式及异常值。结果表明,尽管基于大型语言模型的评估分数与人类专家评估者不同,但大型语言模型产生了与人类评估者相同的人工智能用例总体优先级排序。同时,在人类与基于大型语言模型的评估之间,观察到一种微弱但具有统计显著性的正相关。本研究结果为大型语言模型在结构化评估任务中的潜在用途与局限提供了洞见,并有助于为将人工智能辅助评估整合至战争部流程定义最佳实践,从而以有效且可重复的方式构建人工智能用例。
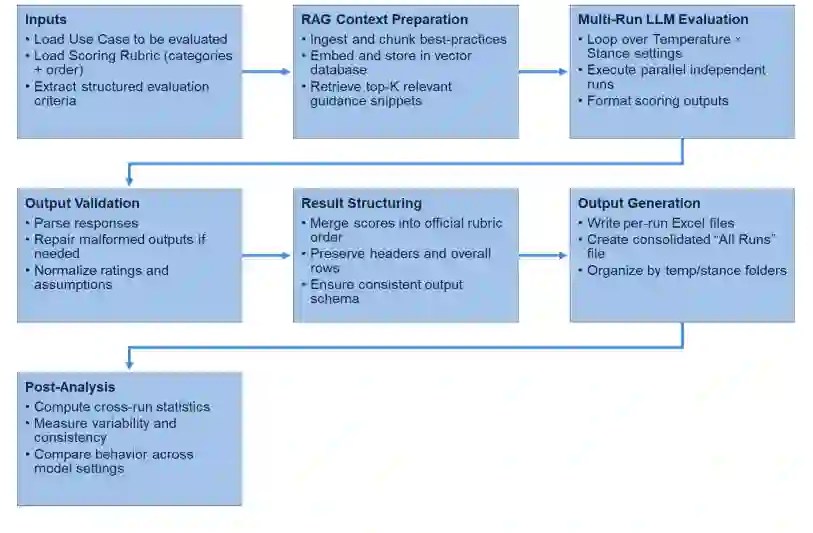
本研究基于麻省理工学院林肯实验室先前在制定优先级排序流程方面的工作,旨在确定利用人工智能实现该流程自动化的最佳实践。该优先级排序流程依赖于跨独立类别的具体用例分析。如表1所述,这些类别分为两个主要主题领域——实施可行性与任务影响。
表1. 用例评估类别描述
| 类别 | 描述 |
|---|---|
| 实施可行性 | |
| 数据可用性 | 衡量数据对人工智能完成此用例的可发现性、可访问性、质量和可用性的指标。 |
| AI模型可用性 | 衡量组织获取各种大型语言模型和AI模型以实施用例解决方案的指标。 |
| 团队AI技术专长 | 衡量负责为此用例实施AI能力的团队的技术能力和经验指标。 |
| 技术成熟度 | 衡量在其上实施AI解决方案的系统复杂度的指标,包括数据流的数量和种类、计算资源、范围、规模以及外部系统依赖性。 |
| 系统复杂度 | 衡量系统复杂度的指标,包括数据流的数量和类型、用户、输入和输出。 |
| 用户培训要求 | 用户为了能够为此用例使用AI实施所需的培训量。 |
| 采购、测试与批准 | 衡量在此用例中使用AI能力的采购、测试与批准复杂度的指标。 |
| 任务影响 | |
| 在战争部整体任务中的相对任务影响 | 成功实施此用例对更广泛的组织任务的总体影响。 |
| 任务绩效改进 | 对AI能力的投资将在多大程度上影响用户完成此用例任务的能力。 |
| 任务对任务的依赖性 | 用户的成功或失败在多大程度上依赖于此用例所具备的能力。 |
| 引入的脆弱性/风险 | 使用此用例的AI能力可能在多大程度上导致完成任务的额外风险和脆弱性。 |
| 政策、数据漂移和不确定性问题 | 使用此用例的AI能力可能在多大程度上给任务的完成增加政策、数据漂移和不确定性问题。 |
| 用户体验 | 用户将在多大程度上信任此用例AI实施的输出结果。 |