
综述 | 3D场景图:开放挑战与未来方向
论文题目:3D Scene Graphs: Open Challenges and Future Directions 论文链接:https://arxiv.org/abs/2606.19383 论文主页:https://3dscenegraphs.com 论文机构:University of Stuttgart、Sapienza University of Rome、Google、MIT、University of Freiburg、University of Montreal、Mila、TU Munich 等 论文类型:Annual Review of Control, Robotics, and Autonomous Systems Volume 10 邀稿综述

导读
3D Scene Graph(3DSG)正在成为空间智能、机器人和具身 AI 中非常重要的一类表示。它试图把低层几何地图与高层语义、对象关系、层次结构和可执行任务连接起来:既知道“物体在哪里”,也知道“物体是什么、与谁相邻、属于哪个房间、能被如何使用、对任务有什么意义”。 这篇综述系统梳理了 2019-2026 年 3DSG 研究的发展,重点不是简单罗列论文,而是围绕几个关键问题展开:什么是 3DSG?它由哪些节点、边、特征、层次和动态结构组成?3DSG 如何从传感器数据构建?它如何服务场景理解、导航规划、操作和新兴空间 AI 应用?现有评测为何仍然碎片化?未来要怎样走向真实世界部署? 文章的核心判断很明确:3DSG 的潜力不只是“给 3D 地图加语义标签”,而是作为物理 AI 的结构化世界表示,连接几何、语义、关系、语言、行动和长期记忆。但要走到这一步,领域还需要统一定义、可比较构建流程、可复用 benchmark、动态一致性建模,以及面向真实任务的评价方式。
1 Introduction | 引言
自主智能体在非结构化真实环境中行动,需要同时具备几何精度和语义理解。传统 SLAM、点云、网格和地图表示擅长度量几何,却难以支持高层推理、长期记忆和交互任务;纯语言或隐式表示拥有丰富语义,却缺少物理空间 grounding。3D Scene Graph 正是为了连接这两端而出现。 3DSG 将场景表示为图:节点可以是对象、房间、区域、楼层或环境,边可以是空间关系、语义关系、层次关系、动作关系或时间关系,节点和边还可以带有几何、语义、多模态 embedding 或文本描述。这样的表示紧凑、可解释、可查询,也天然适合连接机器人任务、视觉理解和语言推理。
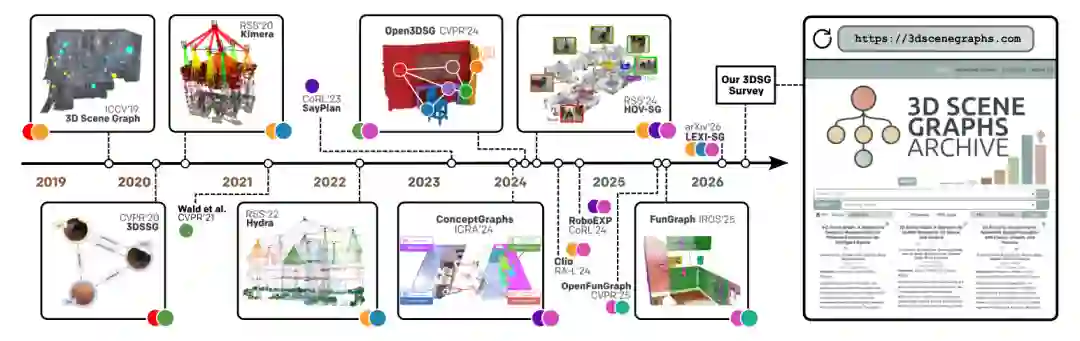
论文指出,3DSG 兴起背后有三股力量:第一,SLAM 与 3D 重建让大规模几何地图更可靠;第二,目标检测、实例分割和基础模型提升了语义抽取能力;第三,LLM/VLM 的发展让结构化世界表示成为语言、感知和行动之间的重要接口。 但领域仍然碎片化。不同社区对 3DSG 的定义、构建流程、评测协议和应用目标并不一致。本文因此围绕四个问题组织综述:什么是 3DSG;如何构建 3DSG;如何使用和评价 3DSG;开放挑战和未来方向是什么。
2 Relation to Prior Surveys and Scope | 相关综述与范围
已有综述分别从 2D scene graph、SLAM、3D 场景表示、LLM for 3D perception、world models 等角度讨论过相关问题,但多数没有把 3DSG 的结构、构建、应用、评测和现实限制作为一个统一对象来分析。 早期 scene graph 综述主要关注 2D 图像理解,难以覆盖 3D 环境中的部分可观测、度量 grounding 和大规模空间扩展问题。SLAM 和场景表示综述通常把 3DSG 看作几何地图的结构化扩展,强调物体/关系抽象与度量地图的融合,却较少讨论语义关系、开放词表、任务规划和交互能力。LLM for 3D reasoning 综述则强调 3DSG 作为可解析结构对语言推理的价值,但不是专门分析 3DSG 领域本身。 本文的范围更聚焦:它希望统一 3DSG 的形式化定义,梳理节点、边、层次、动态和功能性建模选择,讨论从原始观测构建 3DSG 的常见方法,并总结场景理解、导航规划、操作和新兴应用中的评价方式。作者还提供了配套网站 3dscenegraphs.com,用于持续整理和检索 3DSG 论文。
3 What is a 3D Scene Graph? | 什么是 3D场景图
论文将 3DSG 形式化为一个包含节点、边、几何 grounding、节点特征、边特征以及可选层次标签的图结构。节点代表 3D 空间中被 grounding 的实体或概念,可以是对象、对象部件、房间、楼层或区域;边表示节点之间的关系,可以是 directed、undirected,也可以允许同一节点对之间存在多条关系。 节点特征通常分为几何属性和语义属性。几何属性包括中心点、包围盒、形状等;语义属性包括类别、材质、颜色、多模态 embedding 或文本描述。边特征可以描述空间关系、语义关系、功能关系、可达性、包含关系或动作效果。
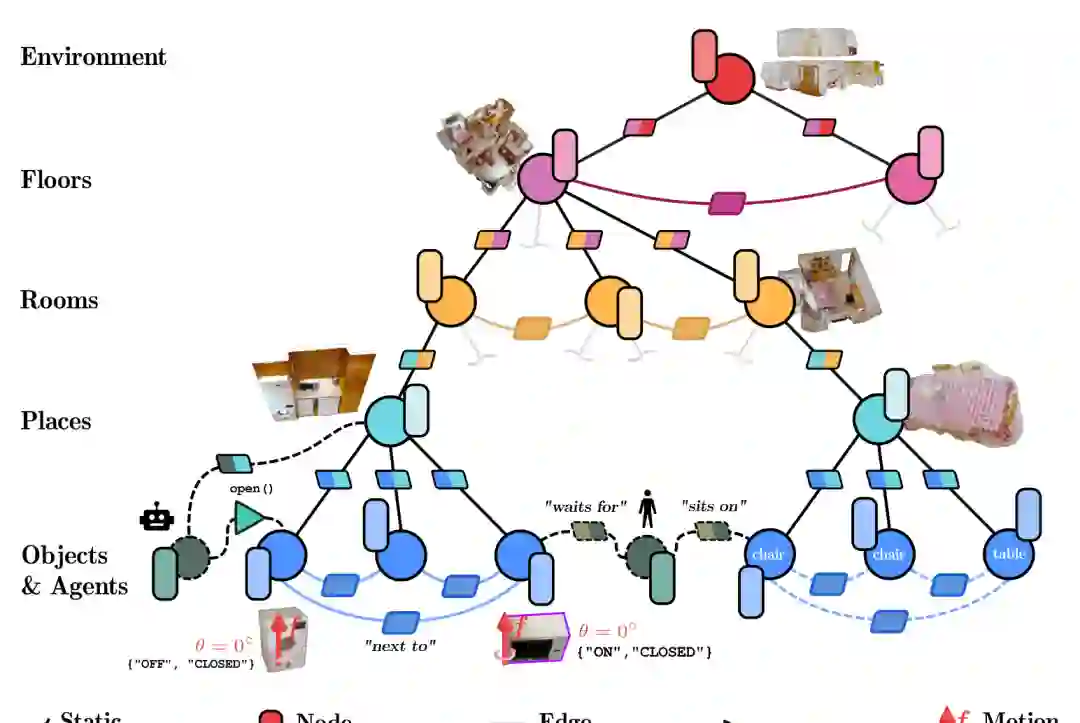
论文重点讨论三类建模扩展。 第一是层次结构。室内环境中常见层次包括 environment、floor、room、place、object;户外环境则更难,因为缺少明确房间边界,常需要按道路、交叉口、区域、可通行空间或功能区域组织。开放挑战在于:抽象层次到底应由几何边界定义,还是由任务、功能或拓扑结构定义?如何自动推断对不同任务都有意义的抽象层? 第二是动态建模。真实场景不是静态的:物体会移动,门会开关,人会行动,机器人也会改变环境。3DSG 需要表示时间变化、数据关联、不确定性和未来状态。当前多数方法更擅长追踪对象轨迹,较少建模关系变化、高层空间抽象的动态演化,以及过去、现在、未来之间的一致性。 第三是功能性与可行动性。一个对象不仅有类别和位置,还可能有 affordance、可交互状态和动作效果。例如杯子可抓取,门可打开,椅子可坐,开关可改变灯光状态。将功能性写入 3DSG,是它从描述性场景表示走向任务级空间智能的关键。
4 How are 3D Scene Graphs built? | 如何构建3D场景图
构建 3DSG 通常要从 RGB-D、点云、mesh、SLAM 轨迹、实例分割、2D/3D 检测、语言描述或多模态模型输出中抽取图结构。论文将构建问题概括为五个维度:processing、nodes、edges、priors、consistency。
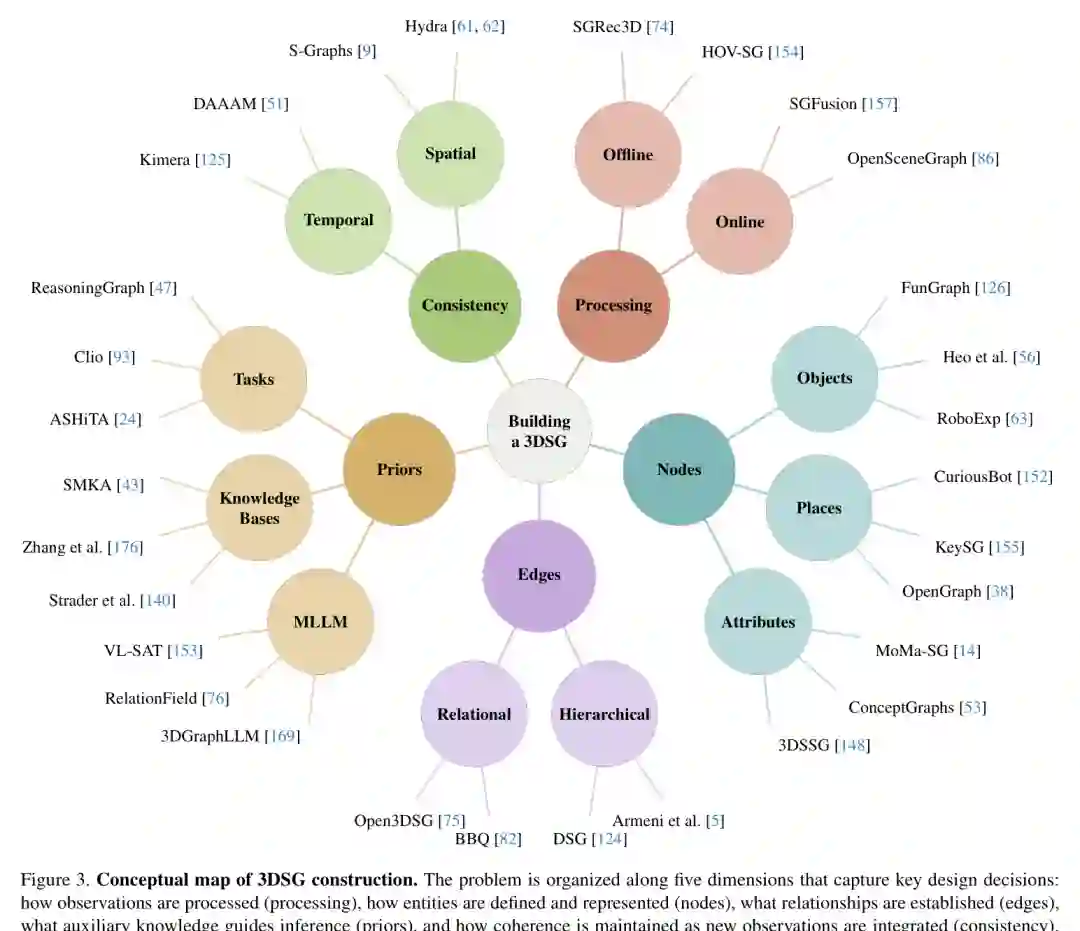
在 processing 维度上,方法可分为 online 和 offline。Online 方法在机器人运行时增量更新图,适合 SLAM、导航和交互;offline 方法先融合场景,再批量构图,通常更适合高质量语义理解和离线分析。 在 node 维度上,核心问题是“什么应该成为节点”。最常见的是对象节点,但还可以包括房间、地点、功能区域、开放词表实体、语言查询相关区域,甚至 agent 和可交互 affordance。随着基础模型发展,开放词表 3DSG 正在成为重要方向:系统不再局限固定类别表,而是利用 VLM/LLM 生成对象候选、描述和语义 embedding。 在 edge 维度上,边可以表示空间邻接、支撑、包含、相对位置、语义关系、层次父子关系或动作关系。关系推断可通过几何规则、学习模型、语言模型或多模态推理完成。当前挑战是边的类型和语义缺乏统一标准,不同论文中的 “relation” 可能含义差别很大。 在 priors 维度上,先验可以来自任务、知识库、LLM/MLLM、物理约束或常识。例如 LLM 可以帮助推断“杯子通常在桌上”“椅子可坐”“厨房中可能有柜台区域”,但也可能引入幻觉或与几何观测不一致的假设。 在 consistency 维度上,3DSG 必须在多视角、多时间、多传感器和多抽象层之间保持一致。对象的跟踪、合并、遗忘、动态更新和不确定性传播,都会影响图是否可靠。论文特别强调,当前很多方法把一致性主要当作几何对齐问题,而较少处理语义一致性、关系一致性和长期记忆中的边界情况。
5 How are 3D Scene Graphs used and evaluated? | 如何使用和评价3D场景图
3DSG 的价值不仅在于能否准确表示场景,还在于它能否支持下游任务。论文从 intrinsic evaluation、scene understanding、planning and navigation、manipulation、emerging applications 几类应用来梳理。
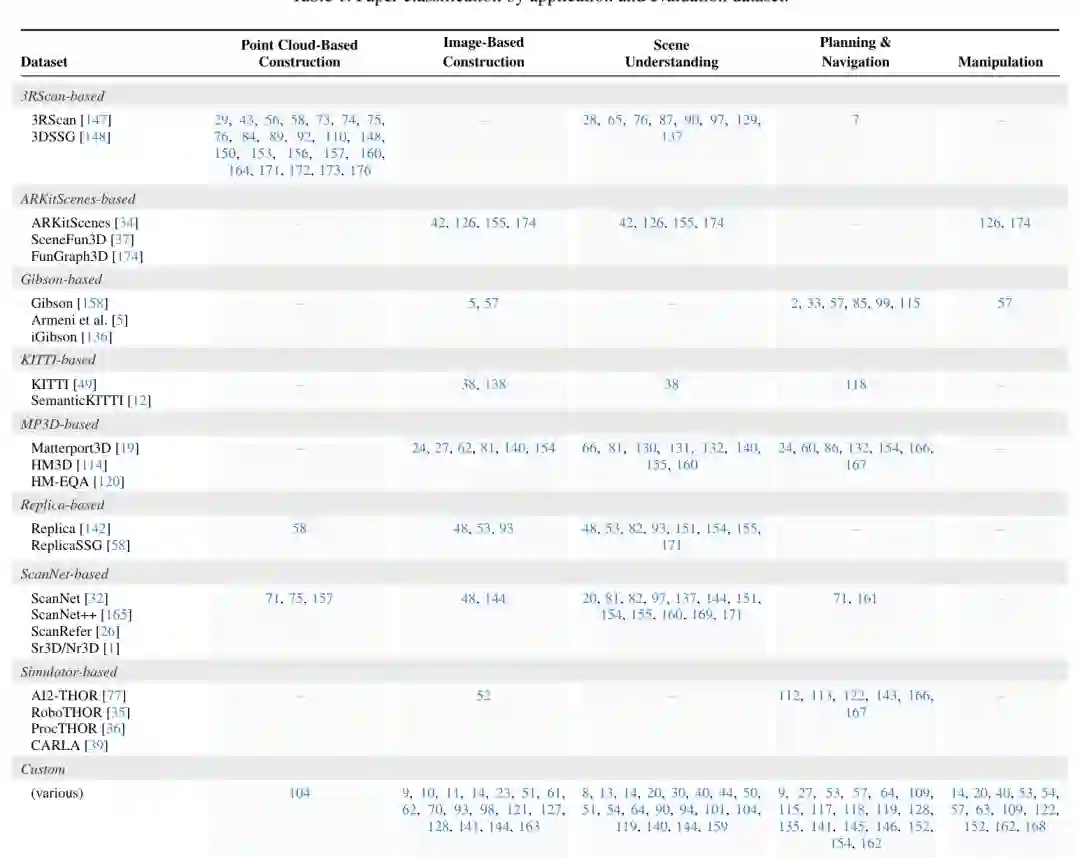
Intrinsic evaluation 关注图自身质量,例如节点和边是否正确、对象实例是否被正确分割、语义标签是否准确、关系预测是否合理。常见指标包括 precision、recall、F1、mIoU、Chamfer distance、3D reconstruction metrics、relation recall 等。但对非对象节点和抽象关系,ground truth 往往很难定义,导致评测协议不统一。 Scene understanding 是 3DSG 的重要动机。3DSG 可支持跨模态实体 grounding、语言查询、关系推理和多跳问答。例如用户问“红色椅子旁边的窗户在哪里”,系统可以在图的对象、房间、关系和属性之间进行结构化搜索。近年方法还将 3DSG 序列化为 JSON 或图结构文本,让 LLM 在节点和边上推理。但当图变大后,直接序列化会迅速超出上下文窗口,因此需要检索、压缩、子图选择和图 RAG。 Planning and navigation 中,3DSG 可将高层语言目标 grounding 到对象、房间或可通行区域,再转化为路径规划或任务规划问题。它既可以帮助符号规划器生成 PDDL/LTL 目标,也可以帮助机器人利用语义拓扑图、可达性图和层次结构进行导航。未来挑战包括动态场景、场景 fidelity、任务规划与底层运动规划的更紧耦合。 Manipulation 中,3DSG 能为抓取、交互、对象搜索和长期任务提供结构化上下文。对象之间的支撑关系、遮挡关系、可操作状态和 affordance 对操作很关键。未来方向包括把长期记忆、可验证动作效果和 VLA 模型结合起来,让机器人不只“看到对象”,还理解对象如何被使用。 Emerging applications 包括开放词表空间问答、面向具身智能的长期记忆、数字孪生、交互式场景编辑、预测未来对象状态,以及作为物理 AI world model 的显式结构接口。这些方向把 3DSG 从传统 robotics map 推向更广义的 spatial AI representation。 论文也指出评测是当前最大短板之一。不同任务使用不同数据集和指标,很多 benchmark 只评估对象层或场景理解局部能力,很少系统评估层次、关系、动态、一致性、长期可维护性和任务成功率之间的关系。
6 Conclusion | 结论
论文总结认为,3DSG 已经从早期的结构化场景表示,发展为连接几何、语义、关系、语言和行动的核心候选表示。它可以服务于场景理解、导航规划、操作和新兴空间智能应用,也可能成为未来 physical AI 和 embodied AI 的显式世界模型接口。 但领域仍面临多重挑战。 第一,表示层面仍缺少统一标准。节点、边、层次、动态和功能性如何定义,不同系统差异很大。第二,构建流程尚不稳定,尤其是开放词表识别、多视角一致性、动态对象、长期更新和语义幻觉控制。第三,应用层面还没有充分证明 3DSG 在复杂真实任务中优于更简单表示。第四,评测层面缺少跨任务、跨数据集、跨层次的 benchmark,导致方法难以公平比较。 未来 3DSG 的关键方向,是从静态场景描述走向任务驱动、动态一致、可验证、开放词表、可与语言模型交互的结构化世界表示。对机器人和空间智能而言,3DSG 的重要性可能不在于它是否成为唯一表示,而在于它为几何地图、语义理解、语言推理和行动规划提供了一个可解释、可查询、可组合的中间层。
7 Author Contributions | 作者贡献
论文作者团队由多家机构共同组成,包括 University of Stuttgart、Sapienza University of Rome、Google、MIT、University of Freiburg、University of Montreal、Mila 和 TU Munich。作者分工覆盖综述结构设计、论文整理、图表制作、网站建设、章节撰写和技术反馈等。公众号正文不展开逐项作者贡献,但保留这一节以对齐原文结构。
8 Acknowledgments | 致谢
原文最后致谢了支持该综述和相关研究工作的机构与项目。更重要的是,作者提供了持续更新的 3D Scene Graphs Archive 网站,帮助社区检索和扩展 3DSG 论文集合,这对一个快速增长但仍然碎片化的领域非常有价值。