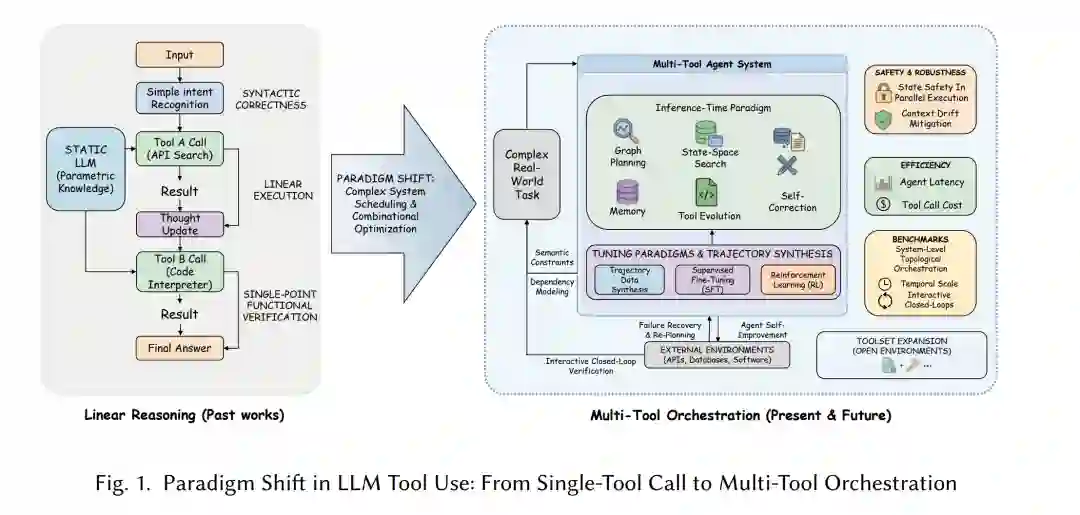
工具调用赋予了大语言模型(LLMs)获取外部信息、调用软件系统以及在数字环境中执行任务的能力,突破了模型仅凭自身参数所能解决的问题范畴。早期研究主要探讨模型能否准确选择并执行单一工具调用。然而,随着智能体系统的演进,核心问题已从孤立的指令调用转向了长轨迹下的多工具编排。这种编排涉及中间状态管理、执行反馈、环境动态变化,以及安全性、成本和可验证性等实际约束。 本文全面综述了多工具大语言模型智能体的最新进展,并对这一快速发展的前沿领域进行了深度分析。首先,我们统一了任务定义,并明确区分了单次调用工具使用与长程(Long-horizon)编排。随后,我们围绕六个核心维度对相关文献进行了系统梳理:推理时规划与执行、训练与轨迹构建、安全与控制、资源约束下的效率、开放环境中的能力完备性,以及基准测试的设计与评估。此外,我们还总结了多工具智能体在软件工程、企业工作流、图形用户界面(GUI)及移动系统中的代表性应用。最后,本文探讨了构建可靠、可扩展且可验证的多工具智能体所面临的主要挑战,并指出了未来的研究方向。
https://arxiv.org/abs/2603.22862
1 引言
尽管大语言模型(LLMs)在自然语言处理领域展现出卓越的推理与生成能力 [121],但受限于静态的参数化知识、潜在的幻觉风险以及缺乏与物理或数字环境的交互,其解决复杂现实问题的能力仍受到制约。工具学习(Tool learning)通过赋予模型调用外部 API(如搜索引擎、代码解释器)的能力来应对这些局限,从而建立起“感知-动作”循环。TALM [129]、MRKL [76]、Toolformer [144] 和 ReAct [205] 等早期工作通过教学模型识别单一意图并正确格式化 API 请求,为该领域奠定了基础,有效地将工具使用内化为一种扩展的语言能力。 随着任务复杂度的提升,单一工具的线性应用已不足以应对现实世界的挑战。多工具利用(Multi-tool utilization)代表了一个独立的研究课题,它涉及组合优化 [103]、程序化语义约束及系统调度 [65] 的交叉领域。自主智能体的决策空间经历了从简单的二元工具选择,到解决单任务中一系列耦合决策的质变。这一过程包括动态工具子集选择、跨工具依赖建模、串行与并行调度、错误恢复以及重规划。当工具使用延伸至涉及状态变更(state-mutating)写操作的长程链条时,如何在并行执行下维持状态一致性并管理竞态条件(race conditions),成为系统稳定性的核心瓶颈。 因此,该领域的主要研究目标已从单点调用的正确性转向复杂环境下多工具链的端到端执行力与鲁棒性。本文首先回顾了推理时推理范式与架构,强调了从串行链式推理向结构化图执行的转变,以及旨在平衡长程规划复杂性与执行效率的双系统架构。随后,我们探讨了数据合成与训练范式,重点关注轨迹合成与闭环验证方法,以解决多工具使用中的组合空间与长尾依赖问题。此外,我们分析了安全性与鲁棒性,特别是并行执行下的状态安全、长链中的上下文偏移 [142] 以及隐私风险的缓解策略。讨论还涵盖了运行效率,评估了端到端智能体延迟、工具调用成本及推理预算 [127]。针对系统完备性,我们审视了在工具或信息缺失的非完备环境下的自适应策略。最后,我们追踪了基准测试评价标准从单点功能验证向系统级拓扑编排及交互式闭环的演进。基于这些现有挑战,我们提出了未来的研究议程,为构建可靠、高效、可扩展的多工具智能体系统提供理论参考与技术路径。
1.1 目标与动机
工具增强型 LLMs 的研究始于一个相对简单的问题:模型能否选择合适的工具并生成有效的调用?这种抽象对于智能体系统而言已不再充分。许多实际任务要求智能体在长轨迹中协调多个工具、维护中间状态、从失败中恢复,并在延迟、成本和安全性的约束下运行。在这些场景中,关键挑战不仅在于工具的接入,更在于编排(Orchestration)。 本综述受当前文献中存在的两个缺口所驱动。首先是概念缺口:尽管“工具使用”、“工具调用”、“工具检索”、“工作流执行”和“编排”等术语指向不同的能力层级,但在现有文献中往往被随意混用。其次是结构缺口:规划、训练、安全、效率、基准测试及开放环境适应性通常被孤立研究,而实际部署的智能体系统则依赖于这些维度的相互作用。
1.2 相关工作
越来越多的综述工作考察了 LLMs 中的工具使用及相关智能体课题,但长程多工具编排鲜少被作为核心问题进行独立探讨。Wang 等人 [178] 从语言模型的视角考量了何谓工具,并提供了外部工具的统一视图。Qu 等人 [140] 综述了 LLMs 中的工具学习,涵盖了规划、工具选择、工具调用及响应生成。Shen [153] 回顾了 LLM 工具使用,侧重于工具整合、训练方法以及从“工具使用”向“工具创建”的转变。Li [89] 总结了基于 LLM 智能体的主要范式,包括工具使用、规划和反馈学习。Luo 等人 [116] 对 LLM 智能体进行了更广泛的综述,横跨方法论、应用与挑战。Chen 等人 [27] 聚焦于基于 LLM 的多智能体系统,而非单一智能体内部的多工具编排。He 等人 [56] 调查了 LLM 智能体中的安全与隐私风险。Mohammadi 等人 [123] 则回顾了 LLM 智能体的评估与基准测试。 本综述与上述文献在以下几个方面有所不同:它将多工具编排(而非泛化的工具使用或更广泛的智能体系统)作为主要分析单元。它围绕六个相互关联的维度组织该领域:推理、训练与轨迹构建、安全与控制、效率、能力完备性以及评估。此外,它对先前工作中经常混淆的概念划定了清晰的界限,包括工具调用、工具检索、编排和工具集扩展。最后,它将方法论的进展与近期基准测试和应用中从“调用级正确性”向“系统级可靠性”的转变联系起来。