
在动态军事环境中部署自主边缘机器人,受到领域特定训练数据稀缺和边缘硬件计算极限的双重制约。本文介绍了一种分层的零样本框架,该框架将轻量级目标检测与来自Qwen和Gemma家族、参数量为4B–12B的紧凑型视觉-语言模型串联起来。Grounding DINO作为一个具有高召回率、可文本提示的区域提议器,检测置信度高的帧会被传递给边缘级视觉-语言模型进行语义验证。在来自《战地6》的55个高保真合成视频上评估了此流程在三个任务上的表现:误报过滤、毁伤评估和细粒度车辆分类。进一步将流程扩展为一个智能化的侦察-指挥官工作流,实现了100%正确的资产部署,并在75秒以内延迟下获得了9.8/10的推理得分。一种新颖的“受控输入”方法将感知与推理解耦,揭示了不同的故障表现:Gemma3-12B擅长战术逻辑但在视觉感知上失败,而Gemma3-4B即使在输入准确的情况下也会出现推理崩溃。这些发现验证了分层零样本架构用于边缘自主的可行性,并为在安全关键应用中认证视觉-语言模型的适用性提供了一个诊断框架。
第一人称视角无人机在现代冲突中的快速扩散从根本上改变了战术格局,将廉价的消费电子产品转变为能够瘫痪重型装甲的精确制导弹药。然而,这些系统的作战效能目前仍与人的技能和情报紧密相连,而人在电子战和认知过载面前越来越脆弱。为了在复杂、信号被拒止的环境中保持杀伤力,下一代无人机需要具备机载自主能力,能够在无人干预的情况下独立执行完整的“发现、定位、终结”杀伤链。
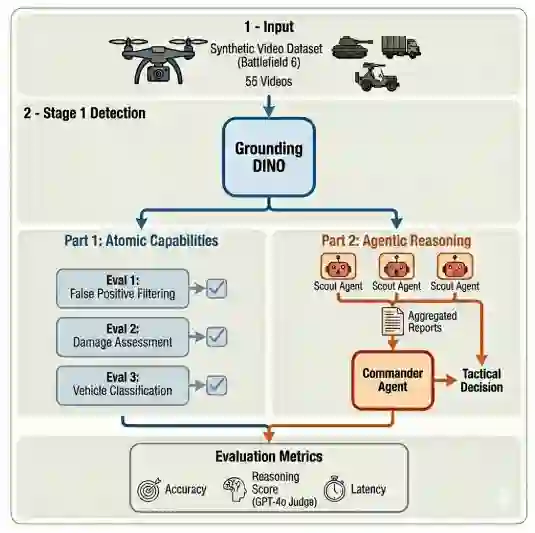
图1:分层零样本框架概览。Grounding DINO 作为语义触发器,提取高置信度帧,然后由边缘视觉-语言模型进行验证,以进行目标分类、毁伤评估和战术决策。
尽管传统的深度学习目标检测器擅长“发现”阶段,但它们缺乏“定位”和“终结”阶段所需的语义深度。一个标准的目标检测器可能正确地框出坦克,但无法区分正在燃烧的残骸和可运作的威胁,或者有效地将主战坦克优先于低价值的后勤卡车。这种语义差距至关重要;在动能场景下的误分类可能导致弹药浪费在已丧失战斗力的目标上,或者更灾难性地导致附带损伤。
视觉-语言模型结合了视觉感知和高级指令跟随能力,提供了一个有前景的解决方案。然而,在边缘机器人上部署这些模型涉及显著的权衡。小型无人机的尺寸、重量和功率约束排除了使用巨型基础模型的可能性,因此必须使用“边缘级”模型。
评估这些边缘智能体的一个关键挑战是故障的“黑箱”性质。当一个自主智能体攻击了错误目标时,标准基准测试通常无法诊断根本原因:系统失败是因为无法看到目标,还是因为缺乏对其排序的战术逻辑?区分这些故障模式对于安全认证至关重要。看不见目标的模型可以通过更好的传感器改进;而拒绝遵循交战规则的模型则构成根本性的安全风险。
本文通过引入一个专门为资源受限的边缘环境设计的分层零样本评估框架来解决这些挑战。利用源自《战地6》引擎的高保真合成数据来模拟多样化的动能场景,从而在不受到实弹测试的后勤和安全限制下进行严格、可重复的评估。通过一种新颖的“受控输入”方法将感知与推理解耦,分离了小型视觉-语言模型特定的认知故障,为其是否适用于自主目标锁定提供了细致的诊断。
总而言之,贡献如下:
- 分层零样本架构:提出了一种级联推理流程,该流程利用轻量级、可文本提示的目标检测作为对计算量要求更高的视觉-语言模型的语义过滤器。与最近关于边缘级联的研究结果一致,证明了这种方法能有效消除100%的误报,同时与密集视觉-语言模型推理相比,显著降低了系统总延迟。
- 解耦安全评估:引入了一种“受控输入”评估方法,将推理能力与视觉感知分离。通过将源自最先进视觉模型的高置信度文本状态注入决策循环,能够诊断任务失败是源于感知障碍还是语义不符。
- 边缘视觉-语言模型的诊断性见解:对参数量在4B–12B级别的开源模型进行了细致的分析。结果揭示了不同的故障模式:虽然Qwen3-VL-8B在两种模态上都表现出稳健的性能,但Gemma3-12B表现出危险的“盲眼战略家”表现型——在给定文本时拥有完美的战术推理能力,但在端到端场景中的视觉目标获取方面显著失败。
- 合成动能基准测试:验证了高保真游戏引擎作为生成罕见、边缘情况训练数据的实用性。这符合利用合成游戏环境弥合军事自动目标识别中“从仿真到现实”差距的新兴研究趋势。
