尽管溯因推理(Abductive Reasoning)——即针对观察到的现象推断最合理解释的过程——在人类发现与意义构建(Sense-making)中发挥着基础性作用,但在大语言模型(LLMs)领域中受到的关注相对较少。尽管 LLMs 取得了飞速发展,但目前对溯因推理及其多维特征的研究仍呈现碎片化状态,缺乏系统性的整合。
本文呈现了首份关于 LLM 溯因推理的综述,追溯了其从哲学基础到当代人工智能实现的演进轨迹。为了解决该领域普遍存在的概念混淆和任务定义脱节的问题,我们确立了一个统一的两阶段定义,并据此对既往研究进行了形式化分类。该定义将溯因过程解构为:假设生成(Hypothesis Generation),即模型填补认知鸿沟以生成候选解释;以及假设筛选(Hypothesis Selection),即对生成的候选方案进行评估并选取最合理的解释。
在此基础上,我们提出了详尽的文献分类体系,涵盖了研究任务、数据集、底层方法论及评估策略。为了进一步验证该框架,我们针对当前 LLMs 的溯因任务开展了小型基准测试(Benchmark),并对不同模型规模、模型家族、评估风格以及生成与筛选任务类型进行了深入的对比分析。此外,通过综合近期实证结果,我们探讨了 LLM 在溯因推理上的表现与其在演绎及归纳任务表现之间的关联,从而为其整体推理能力提供洞察。
分析结果揭示了当前方法的关键短板——从静态基准测试的设计和狭窄的领域覆盖,到有限的训练框架以及对溯因过程缺乏机制性的理解。最后,我们提出了未来的研究方向,包括构建更丰富的评估框架、引入“解释美德”的强化学习、多智能体架构以及电路级可解释性,旨在推动该领域向更严谨的溯因推理能力迈进。
1 引言
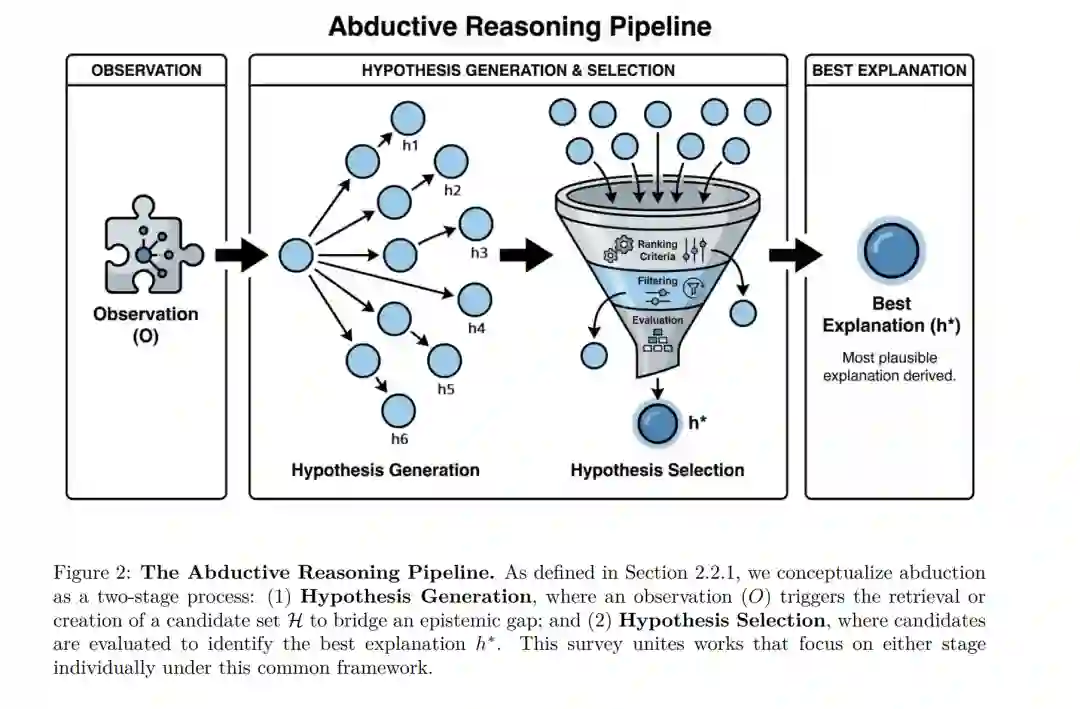
医生面对病症与教科书不符的患者;物理学家观察到本应不可能存在的测量值;侦探走进一个线索杂乱无章的房间。在这些场景中,关键步骤并非单纯地应用已知规则,而是去推测幕后可能发生的情况:即虚构一个合理的“故事”,若该故事属实,则能让原本令人困惑的观察结果变得顺理成章。 这就是溯因推理(Abductive Reasoning):给定观察结果 $O$,推导出假设 $H$,使得在 $H$ 成立的前提下,$O$ 变得合乎逻辑(Peirce, 1931–1958)。一个简单的日常故障排查例子是:你的浏览器显示错误,你推测“可能是 Wi-Fi 断了”,因为若该假设成立,出现错误便在预料之中。溯因推理最早由哲学家查尔斯·桑德斯·皮尔斯(Charles Sanders Peirce)形式化定义,它是人类意义构建、科学发现和诊断推理的基石(Aliseda, 2006)。它是从数据到解释的一种扩张性(Ampliative)且具易错性(Fallible)的飞跃。 近年来,对通用人工智能(AGI)的追求重新点燃了计算建模溯因推理的巨大兴趣。如图 1 所示,大语言模型(LLMs)的兴起引发了旨在赋予模型溯因能力的爆发式研究。早期自然语言处理(NLP)工作集中在常识推理任务,例如为日常情景生成解释,或从备选项中选择最可能的诱因。近期研究已扩展到多种复杂领域:例如,研究者探索了结合文本与视觉的多模态语境以落地溯因推断;另有研究通过程序化规则学习从观察模式中推导底层逻辑。在专业领域,溯因推理模型正日益应用于辅助复杂的医疗诊断和法律案件分析。此外,这些方法还与知识图谱相结合,用以预测缺失关系并导出结构化解释。最后,溯因能力甚至被延伸至形式逻辑和基于规则的推理等高度严谨的领域。 尽管研究激增,但 AI 领域的溯因推理研究仍处于严重的碎片化状态,在统一定义或标准任务操作化上尚未达成共识。部分研究将溯因简化为从预设集合中选择或排序最佳假设的判别式任务,或评估单一候选假设的合理性。另有研究将其视为从零开始创建自由文本解释的生成式任务,或生成缺失的结构化知识(如事实或程序)。还有研究探索了逻辑规则或知识图谱关系等结构化假设空间。这种共同框架的缺失,导致方法论难以对比、研究进展难以累积,也难以确定未来的关键研究路径。 为了解决这一碎片化问题,我们首先考察了溯因推理的哲学与历史基础。这一背景引导我们提出一个统一的实用定义,该定义紧密借鉴了最佳解释推断(Inference to the Best Explanation, IBE)的概念。我们不将溯因视为单一整体,而是将其构想为一个两阶段过程(详见 2.2.1 节): 1. 假设生成阶段(Hypothesis Generation):目标是创造性地生成一组具有扩张性的候选假设集合 ${h_1, h_2, \dots, h_n}$。 1. 假设筛选阶段(Hypothesis Selection):基于解释美德(Explanatory Virtues)——如简洁性、连贯性和预测能力——对这些候选者进行评估,以确定唯一的最佳解释 $h^*$。
基于此模型,我们在第 3 节构建了一个全面的四轴分类学,从任务形式、数据集类型、方法论和评估方法四个维度对现有工作进行归类。除了理论分类,本综述还提供了详尽的实证分析(第 4 节)。我们对多种现代 LLM(参数量从 3B 到 72B,包括 Qwen2.5、Llama3.3、DeepSeek-V3.2、GPT-5.4 等)在常识及专家领域的代表性任务上进行了基准测试。我们的研究揭示了当前模型在不同复杂度下的细微优劣势。此外,通过汇总已有研究结果,我们对 LLM 在溯因、演绎和归纳推理范式下的能力进行了对比分析。 最后,通过综合研究发现,我们指出了制约该领域的关键空白:概念碎片化、领域覆盖窄、能力与评估不匹配,以及基准测试准确率与真实溯因推理之间的脱节。为了克服这些限制,我们提出了若干未来方向:包括对齐解释美德的强化学习、面向动作的领域基准测试、多智能体架构以及揭示溯因电路机制的解释性研究。 据我们所知,本文是首份专门针对 LLM 溯因推理的综述。
主要贡献
本综述的主要贡献如下: * 统一的定义框架:通过考察溯因与 IBE 的哲学基础,形式化了一个统一的两阶段(生成与筛选)定义,化解了现有的概念碎片化问题。 * 全面的分类学与文献综述:引入了全新的四轴分类学,涵盖近 70 篇核心论文,突出了研究趋势、关联及空白。 * 实证基准测试与分析:对涵盖 3B 至 72B 参数量的现代 LLM 进行了实证评估。跨范式对比分析表明,强有力的演绎或归纳能力并不能可靠地预示强大的溯因推理表现。 * 未来研究的关键方向:识别了能力-评估错配、领域覆盖窄等关键空白,并提出了基于强化学习的优化、多智能体框架设计以及神经溯因电路的机械可解释性研究等战略性方向。
**
**