

在无需额外训练的情况下,将多个神经网络的能力整合至单一统一模型中,模型合并(Model Merging)已成为一种变革性范式。随着微调大语言模型(LLMs)的迅速激增,合并技术为模型集成(Ensembles)和全量重新训练提供了一种具备计算效率的替代方案,使从业者能够以极低的成本构建具备特定能力的组合模型。 本综述通过 FUSE 分类体系——一个涵盖基础(Foundations)、统一策略(Unification Strategies)、**场景(Scenarios)和生态系统(Ecosystem)**的四维框架,对大语言模型时代的模型合并进行了全面且系统化的审视。我们首先确立了合并技术的理论基础,包括损失曲面几何(Loss Landscape Geometry)、模式连通性(Mode Connectivity)以及线性模式连通性(LMC)假设。随后,我们系统地回顾了算法图景,涵盖权重平均(Weight Averaging)、任务向量算术(Task Vector Arithmetic)、稀疏化增强方法、混合专家(MoE)架构以及进化优化方法。针对每一类方法,我们分析了其核心公式,重点介绍了代表性工作,并探讨了实际应用中的权衡取舍。 此外,我们还考察了其在多任务学习、安全对齐(Safety Alignment)、领域专业化、多语言迁移及联邦学习等下游任务中的应用。最后,我们调研了由开源工具、社区平台和评估基准组成的支撑生态,并识别了关键的开放性挑战,包括理论鸿沟、扩展性瓶颈以及标准化需求。本综述旨在为研究人员和从业者提供结构化基础,以推动模型合并领域的发展。
1 引言 (Introduction)
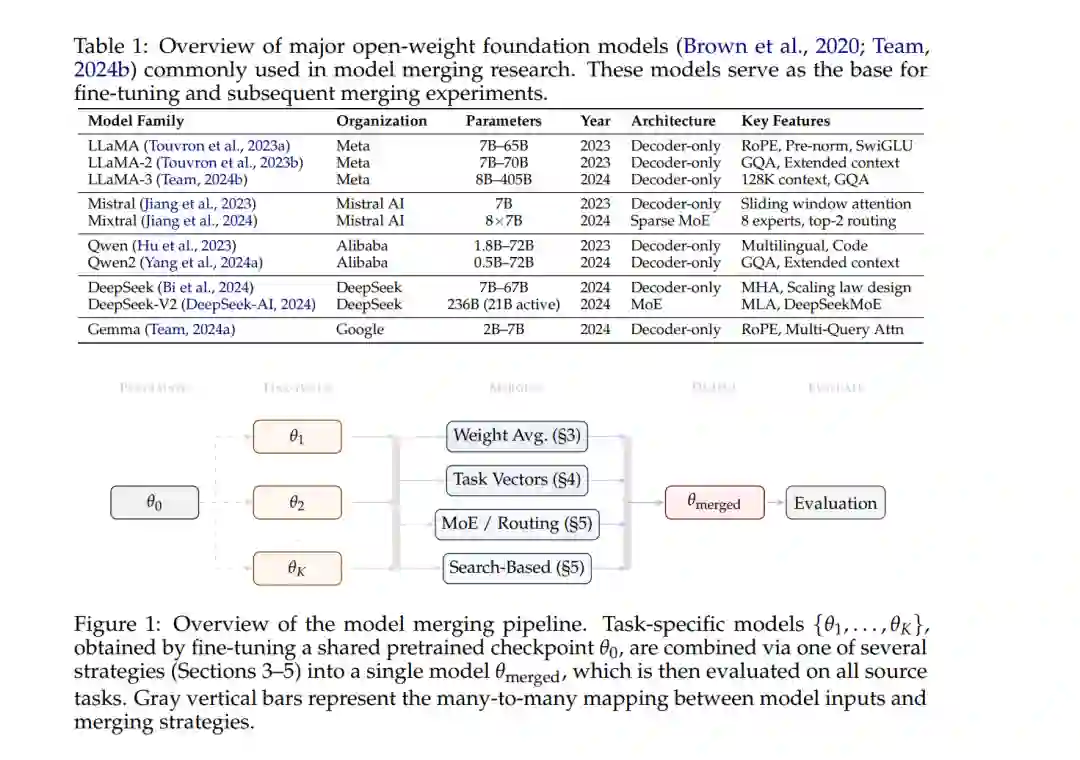
模型合并(Model Merging)将多个已训练神经网络的参数组合成单一统一模型,从而在无需推理端集成(Inference-time ensemble)开销的前提下继承各模型的能力 (Li et al., 2023a)。与在运行期间聚合多个独立模型预测结果的集成方法不同,合并技术直接作用于权重空间(Weight Space),生成的单一模型其计算成本与任何单个源模型相当。早期研究表明,对使用不同随机种子训练的模型进行参数平均可以提高泛化性能 (Izmailov et al., 2018)。起初,这些技术主要应用于在相同数据集上训练的同质模型(Homogeneous models),其中随机权重平均(Stochastic Weight Averaging, SWA)成为沿单一优化轨迹组合检查点(Checkpoints)的一种原则性方法 (Garipov et al., 2018)。随着大规模预训练语言模型 (Devlin et al., 2019) 的出现,模型合并的范畴大幅扩展,使得将针对完全不同任务微调的模型组合成具备多任务能力的统一系统成为可能 (Ilharco et al., 2023)。这种从“检查点平均”到“跨任务组合”的演进,标志着学术界对神经网络知识复用概念的转变。 LLaMA (Touvron et al., 2023a)、Mistral (Jiang et al., 2023)、Qwen (Hu et al., 2023)、DeepSeek (Bi et al., 2024)、Gemma (Team, 2024a) 和 CLIP (Radford et al., 2021) 等预训练基座模型的涌现,为模型合并创造了兼具实际可行性与科学吸引力的条件。其核心见解在于:基于共享预训练初始化微调的模型往往位于同一个损失盆地(Loss Basin)中,表现出线性模式连通性(Linear Mode Connectivity, LMC) (Singh & Jaggi, 2020),允许在不穿过高损失屏障的情况下进行直接权重插值 (Garipov et al., 2018)。这种理论基础,结合开源微调大语言模型的激增,激发了对合并方法论的浓厚兴趣。过去两年见证了研究活动的爆发,诸如任务向量算术(Task Vector Arithmetic)、稀疏化增强合并以及激活感知(Activation-informed)(Hammoud et al., 2024) 等新颖技术在组合专业化模型方面取得了显著成功 (Yadav et al., 2023; Yu et al., 2023; Huang et al., 2024)。在实践中,合并后的模型在包括 Open LLM Leaderboard (Li et al., 2023b) 在内的竞争性榜单中名列前茅,证明了战略性的模型组合可以产生超越单个微调变体的能力 (Wortsman et al., 2022a; Jang et al., 2024)。专用工具包如 mergekit (Goddard et al., 2024) 的建立进一步降低了这些技术的门槛,使得无需深厚的工程背景即可实验复杂的合并策略。理论理解、经验成功与实用工具 (Goddard et al., 2024) 的交汇,使模型合并成为了现代 LLM 开发的核心技术。 近期已有一些综述开始探讨这一快速演变领域的各个方面。Yang et al. (2024b) 和 Li et al. (2023a) 对深度学习中的模型融合技术进行了广泛探讨,而 Yadav et al. (2024a) 则专门关注混合专家(MoE)风格的组合方法。Yang et al. (2024b) 更广泛地考察了协作策略,涵盖了合并与集成方法。然而,现有综述缺乏统一的视角来系统性地连接解释合并成功的理论基础、有效执行合并的算法策略、提供价值的下游应用场景,以及支持部署的实际生态系统。尚未有工作全面覆盖从损失曲面几何与模式连通性理论到评估方法论及社区工具的完整频谱,也未提出用于导航该空间的统一分类体系。 本综述对大语言模型时代下的模型合并进行了系统性论述,架起了理论理解与实际应用之间的桥梁。表 1 总结了合并研究中常用的主要开源权重基座模型 (Brown et al., 2020; Team, 2024b)。如图 2 所示,本综述围绕 FUSE 分类体系展开,这是一个涵盖基础(Foundations)、统一策略(Unification Strategies)、场景(Scenarios)和生态系统(Ecosystem)的四维框架。该框架根据合并为何有效、如何执行、何处产生价值以及哪些资源提供支持来组织该领域。图 1 提供了模型合并流程的示意图。本综述的主要贡献如下: 1. 提出 FUSE 分类体系作为原则性的组织框架,全面分类了模型合并研究:包括损失曲面几何、模式连通性和权重空间对称性等理论基础;涵盖权重空间平均、任务向量算术、几何插值和架构级组合的算法统一策略;包括能力增强、对齐与安全、以及效率驱动型部署的应用场景;以及涵盖工具包、基准测试和社区资源的生态系统基础设施。 1. 提供合并方法论的深度技术分析,阐明每种方法背后的数学原理,并对其各自的优势、局限性及适用场景提供对比性见解。 1. 对应用领域进行系统性审查,综合归纳了关于模型合并在多任务泛化、多语言迁移、偏好对齐和联邦学习场景中何时及如何交付实际效益的经验证据。 1. 识别开放性挑战并明确具有前景的未来研究方向 (Li et al., 2025),包括理解“可合并性”的理论鸿沟、日益增长的模型规模带来的扩展性限制,以及自动化与动态合并系统的机遇。
本综述余下部分安排如下:第 2 节确立理论基础;第 3-5 节介绍由浅入深的统一策略;第 6 节探讨应用场景;第 7 节讨论生态系统、开放挑战及未来方向。
