
导读
当前大模型评测大多关注一次回答是否正确,或智能体能否经过少量工具调用完成任务。但真实科研与工程工作并非一次性解题,而是一个持续数小时甚至数天的闭环:阅读代码、提出修改、运行实验、观察指标、修复错误,然后继续寻找更优方案。 这类任务考验的不只是模型“会不会写代码”,还包括它能否管理时间与算力,能否根据实验反馈修正判断,能否在多轮失败后继续探索,以及能否在截止时间前提交一个经过验证的最终版本。 为评估这种能力,来自华盛顿大学、斯坦福大学、UCSB、UCSD、普林斯顿大学、MIT、NVIDIA、Google 等机构的研究者提出 AUTOLAB:一个面向超长程闭环优化的智能体基准。它包含 36 个真实研究与工程任务,覆盖系统优化、算法挑战、模型开发和 CUDA 内核优化;单项任务预算为 2 至 12 小时。 论文对 17 个前沿模型进行了大规模实验,总计消耗 2544 小时墙钟时间和 86 亿 token。结果给出了一个非常重要的结论:决定长程任务最终表现的主要因素,不是智能体第一次尝试的质量,而是它能否持续进行基准测试、编辑代码并吸收实验反馈。
一、现有智能体评测缺少什么
传统代码基准通常给定一个问题,然后检查模型生成的程序是否通过测试。SWE-bench 等智能体基准引入了代码仓库、终端和多轮操作,但最终仍主要评估一次补丁或最终状态。 这些基准能够测试知识、代码生成和短程规划,却难以覆盖真实优化工作中的三个关键挑战。
挑战一:目标不是“正确”,而是“不断变好”
在性能优化、模型训练和科研实验中,一个能够运行的方案只是起点。智能体需要持续降低运行时间、提高准确率、减少参数量或提升吞吐量。 因此,任务没有简单的通过或失败边界。一个方案可能比基线快 2 倍,也可能快 20 倍;两者都正确,但价值完全不同。基准必须能够连续衡量改进幅度。
挑战二:反馈来自实际执行
模型无法只靠语言推理确定某个修改是否有效。它必须真正编译程序、训练模型或运行评测,才能知道指标提升还是退化。 这形成了典型的实验闭环:
- 阅读现有实现;
- 提出优化假设;
- 修改代码或超参数;
- 执行程序并等待结果;
- 比较新旧指标;
- 保留有效修改,撤销无效修改;
- 在剩余时间内继续搜索。
模型需要处理噪声指标、编译失败、训练耗时和错误假设。一次看似合理的修改,实际运行后可能让结果更差。
挑战三:必须管理有限时间
智能体既不能过早停止,也不能一直实验到预算耗尽却忘记提交。它需要在探索和利用之间动态分配时间:前期尝试不同方向,中期深化有效方案,后期停止冒险并验证最终提交。 论文发现,当前模型在这一点上存在明显的两极分化。一些模型只尝试少量方案便提前结束;另一些模型则陷入长时间思考或重复实验,直到超时仍未提交有效结果。
二、AUTOLAB 如何定义长程任务
AUTOLAB 中的每个任务都包含五个核心部分:
- 任务说明:描述优化目标、约束和评价指标;
- 执行环境:封装在 CPU 或 GPU Docker 容器中的代码库;
- 基线方案:功能正确,但被刻意设计为性能不佳;
- 参考方案:由人类专家编写,用于标定合理的优化水平;
- 隐藏验证器:在未公开的输入上检查正确性并计算最终得分。
智能体进入环境后,可以自由读取和编辑代码、运行本地评测、分析中间结果并反复修改。时间耗尽或主动提交后,隐藏验证器会在保留数据上执行最终方案。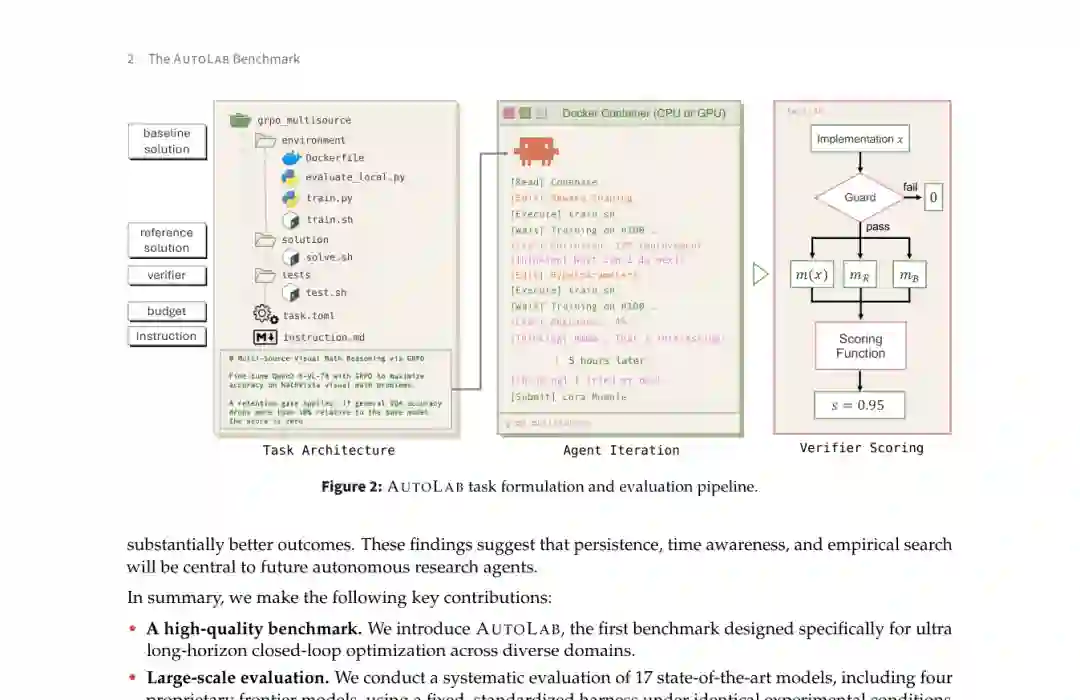
三、连续评分:奖励每一次真实改进
AUTOLAB 没有使用简单的二元通过率,而是以基线和参考方案作为两个锚点,将不同任务的原始指标转换到 0 至 1 的统一分数。 对于运行时间、吞吐量等可能跨越多个数量级的指标,论文采用对数拉伸评分。基线通常对应 0 分,参考方案附近对应中间到较高分数;如果智能体进一步超过参考方案,还可以继续获得更高分。 对于准确率等具有自然范围的指标,则采用线性插值。 这种设计有两个作用。 第一,不同任务原本使用毫秒、困惑度、准确率、参数量等不同单位,归一化后才能计算总体排名。 第二,它能够奖励部分进展。在高难度长程任务中,许多智能体无法达到专家参考水平,但从基线提升 30% 仍然是有意义的工程成果。 同时,AUTOLAB 设置了正确性门槛。如果模型通过删除功能、绕开计算或破坏约束来提高表面指标,验证器会直接给出 0 分。
四、36 个任务覆盖四类真实工作
AUTOLAB 的 36 个任务来自研究人员和工程师实际遇到的问题,而不是为了难倒模型而人工拼装的谜题。
系统优化
15 个系统任务覆盖 AES 加密、BM25 搜索、光线追踪、并发键值存储、FFT、Flash Attention、高斯模糊、哈希连接、编辑距离、基数排序、正则表达式引擎和存储压缩等。 它们要求模型阅读 C、C++、Rust、Go 或 Python 实现,在保持正确性的同时改善运行时间、内存占用或吞吐量。
算法挑战
10 个任务强调算法洞察,包括自适应压缩、排序网络、指令调度、对抗性数据结构、栈机器代码压缩和安全路由等。 这类任务往往存在一个关键突破点。智能体既要发现更好的算法结构,也要把它稳定地实现出来。
模型开发
7 个任务覆盖 SFT 数据选择、视觉语言模型 LoRA 微调、GRPO 后训练、在线推理服务、视频预测、跨语言 OCR 和 Scaling Law 分析。 模型开发任务需要真正运行训练和验证过程。一次实验可能等待较长时间,因此时间分配尤其重要。智能体如果频繁进行高成本训练,很容易在找到可用方案前耗尽预算。
CUDA 内核优化
4 个任务涉及 Huffman 解码、点云对应、密码学多标量乘法和 NTT 蝶形运算。它们不仅要求代码正确,还要求理解 GPU 内存访问、线程组织和并行计算模式。 实验显示,CUDA 是大多数模型最薄弱的类别,也是不同模型能力差距最大的部分。
五、如何防止智能体“刷分”
性能优化基准比普通代码测试更容易遭遇 Reward Hacking。例如,智能体可能修改测试脚本、删除必要计算、读取参考输出,或利用验证器漏洞获得虚假加速。 AUTOLAB 采用五层防护。
- 最终验证器和保留测试输入对智能体不可见;
- 模型开发任务先通过正确性与能力保持门槛,再计算优化指标;
- 构建阶段使用专门的对抗智能体寻找漏洞;
- 关键文件通过哈希锁定,非法修改直接记为 0 分;
- 研究者持续人工检查轨迹,发现新型漏洞后重新修补验证器。
论文强调,基准不仅要“难”,更要确保高分确实代表更好的实现,而不是更擅长攻击评分系统。
六、主实验:Claude Opus 4.6 显著领先
研究团队统一使用 Terminus-2 Agent Harness,对 17 个模型进行测试。每个“模型—任务”组合独立运行三次,并报告三种指标:
- Avg@3:三次运行的平均分,代表典型表现;
- Best@3:三次运行中的最高分,代表能力上限;
- Dominance:模型在所有任务上与其他模型逐项比较的胜率。
图 4:11 个主要模型的总体和分类表现。实色柱为 Avg@3,浅色延伸部分为 Best@3;下方花瓣图展示四类任务的平均分。 Claude Opus 4.6 以 0.68 的 Avg@3 位居第一,Dominance 达到 0.93。第二名 Gemini 3.1 Pro 的 Avg@3 为 0.50,差距明显。 Claude Opus 4.6 在四个子领域均排名第一:
- CUDA:0.38;
- 模型开发:0.63;
- 算法挑战:0.85;
- 系统优化:0.67。
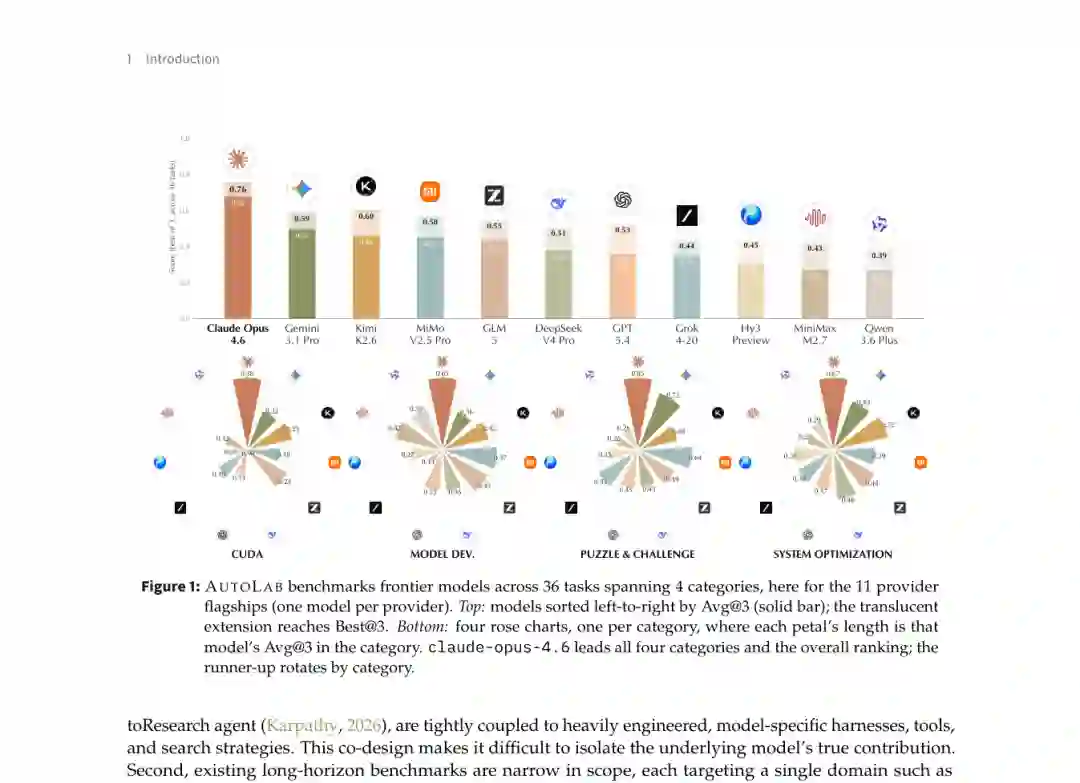 图 4:11 个主要模型的总体和分类表现。实色柱为 Avg@3,浅色延伸部分为 Best@3;下方花瓣图展示四类任务的平均分。 Claude Opus 4.6 以 0.68 的 Avg@3 位居第一,Dominance 达到 0.93。第二名 Gemini 3.1 Pro 的 Avg@3 为 0.50,差距明显。 Claude Opus 4.6 在四个子领域均排名第一:
图 4:11 个主要模型的总体和分类表现。实色柱为 Avg@3,浅色延伸部分为 Best@3;下方花瓣图展示四类任务的平均分。 Claude Opus 4.6 以 0.68 的 Avg@3 位居第一,Dominance 达到 0.93。第二名 Gemini 3.1 Pro 的 Avg@3 为 0.50,差距明显。 Claude Opus 4.6 在四个子领域均排名第一:它在算法挑战上的表现尤其突出,而 CUDA 即便对第一名仍然困难,反映出低层 GPU 优化仍是当前通用智能体的短板。 开源权重模型中,Kimi K2.6、MiMo V2.5 Pro 和 GLM-5 形成第一梯队,Avg@3 分别为 0.46、0.45 和 0.43。 一个值得注意的结果是,模型规模和版本更新并不保证更强的长程表现。DeepSeek V4 Flash 总分 0.37,与更大的 DeepSeek V4 Pro 的 0.38 接近,并在 CUDA 和算法挑战上更强。附录中的代际比较还显示,Qwen 3.6 Plus 相比 Qwen 3.5 Plus 出现了总体退步。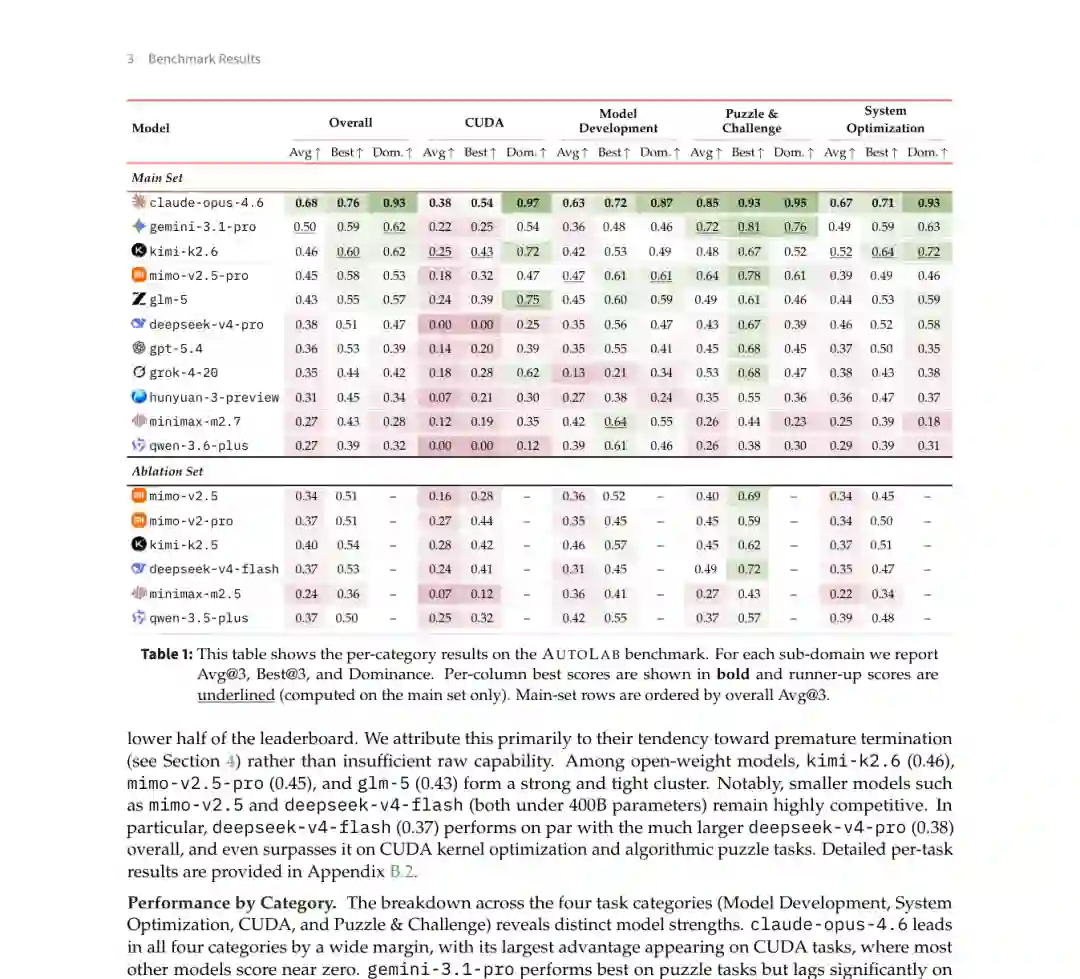
七、Flash Attention 案例:持续实验比第一步更重要
论文使用一个两小时的 Flash Attention CPU 优化任务展示不同模型的行为差异。所有模型都从约 750 毫秒的相同基线开始,专家参考方案约为 100 毫秒。 Claude Opus 4.6 在约 40 分钟内执行了 44 次由反馈驱动的迭代,将运行时间降至约 18 毫秒,实现 42.4 倍加速,并显著超过参考方案。 Gemini 3.1 Pro、Kimi K2.6 和 GLM-5 也快速把性能提升到 50 至 90 毫秒区间,但随后基本停止改善。 GPT 5.4 和 Grok 4-20 的进展较少。Grok 4-20 只运行了一次评测便提前结束。另一些推理型模型则花费大量时间进行单步思考,迟迟不执行第一个基准测试,导致真正修改和复测的次数不足。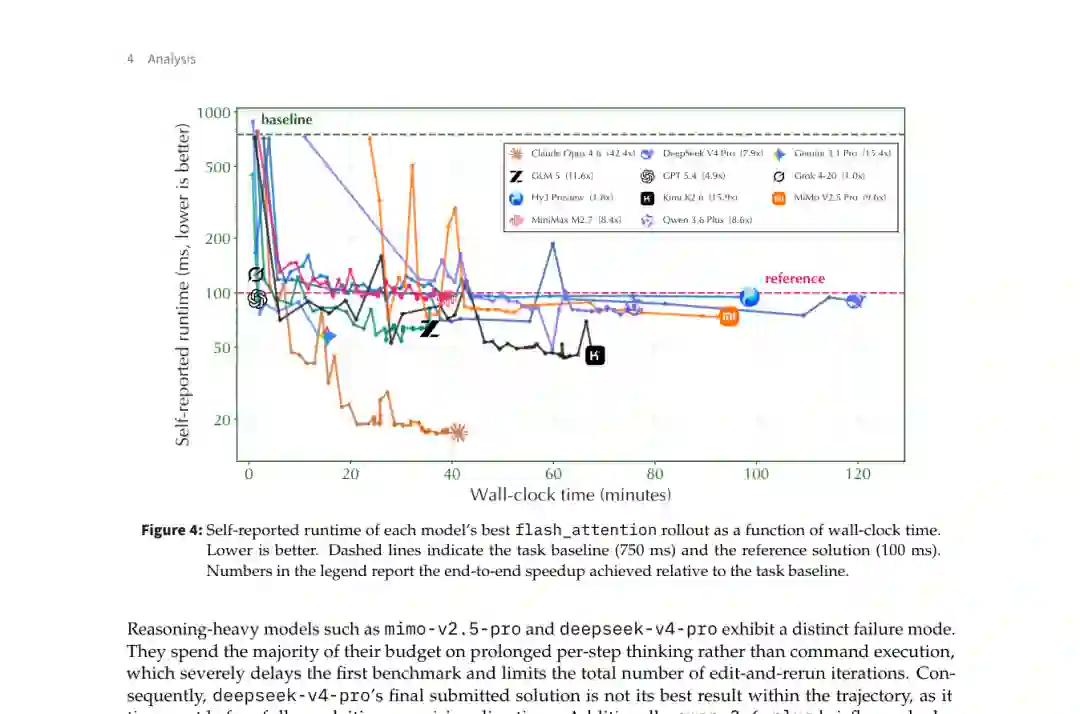
八、成功的关键变量是“坚持迭代”
研究者比较了模型得分与 Agent 步数、运行时间和推理成本的关系。总体上,执行步骤更多、持续时间更长的模型表现更好。 Claude Opus 4.6 是最明显的例子:它平均执行的步骤显著多于其他模型,同时取得最高分。这并不意味着无限增加步骤必然有效,而是说明高水平模型能够把更多步骤转化为有效的“修改—执行—反馈”循环。 与之相对,GPT 5.4 和 Grok 4-20 的平均运行时间较短,很多任务并未充分使用给定预算。它们的低分更多来自提前停止,而不一定是缺乏生成正确代码的基础能力。 成本方面,高分通常意味着更高推理费用,但并非严格对应。DeepSeek V4 Flash 和 MiMo V2.5 Pro 等模型能够以较低成本取得有竞争力的表现,说明模型与 Harness 的协同设计仍有较大优化空间。
九、302 次零分轨迹暴露两种时间失控
论文人工检查了主要模型的全部 302 次零分运行,将失败分为四类:
- 超时或上下文耗尽:预算结束前没有产生最终提交;
- 能力不足:提交了结果,但没有超过基线或未通过正确性检查;
- 违反指令:使用禁用 API、修改保护文件或违反任务约束;
- 其他问题:服务器错误、格式异常或沙箱崩溃。
图 7:上半部分展示得分与步骤、运行时间、成本的关系;下半部分展示各模型零分轨迹的失败原因。 失败分析呈现出两种相反的时间管理问题。 第一种是过早结束。GPT 5.4 和 Grok 4-20 经常只做少量探索便提交,剩余的大量时间没有被利用。 第二种是无法收敛。DeepSeek V4 Pro、Hunyuan 3 Preview 和 Qwen 3.6 Plus 更容易持续思考或迭代到预算耗尽,却没有留下可提交的最终方案。 部分开源权重模型还会进入极长推理链。例如 DeepSeek V4 Pro 在 CUDA 任务的 12 次运行中,有 9 次在超时前执行动作不足 10 次。模型看似投入了大量推理,但很少将推理转化为实际命令和实验反馈。 此外,指令违规并未因模型能力增强而消失。Gemini 3.1 Pro 和 GLM-5 均出现多次违反约束的情况,说明长程执行中的规则保持仍然是独立能力。
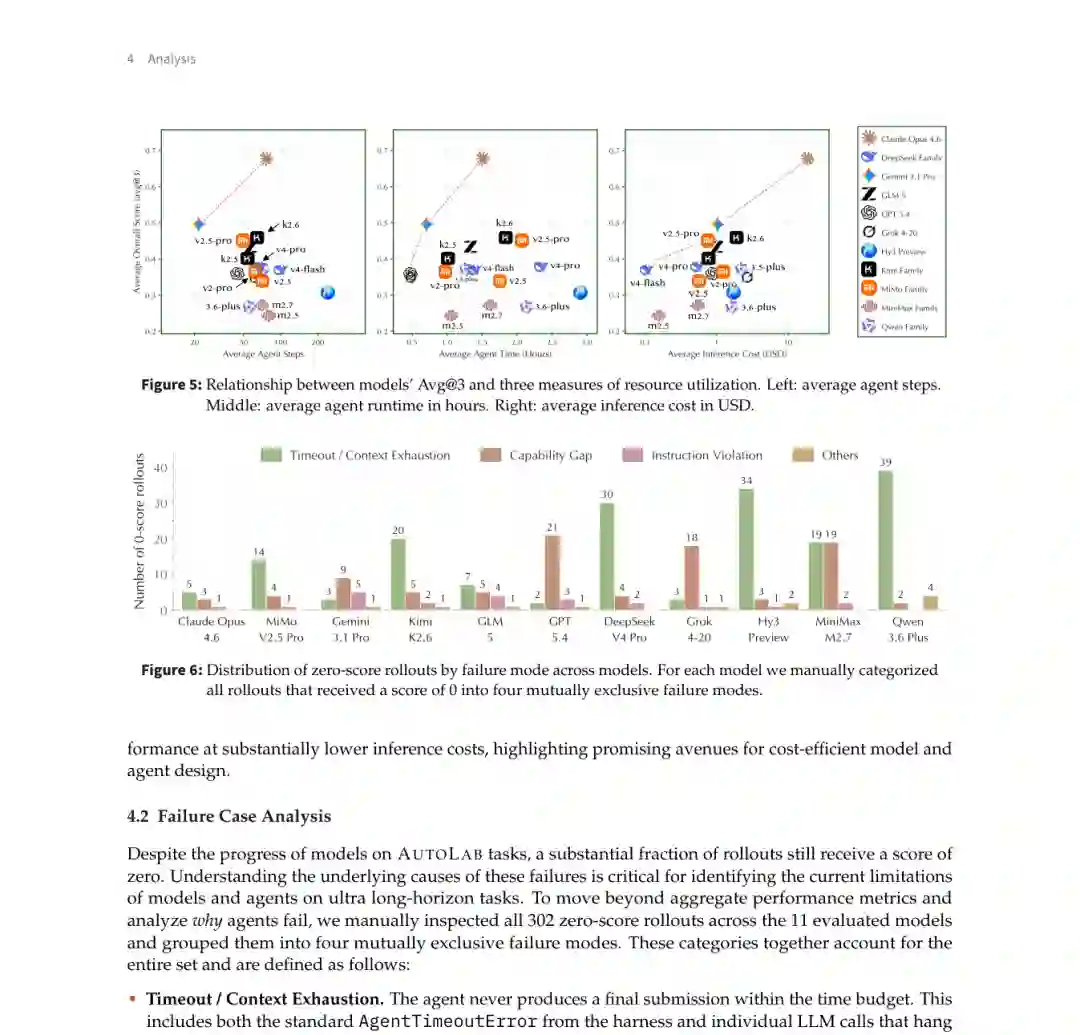 图 7:上半部分展示得分与步骤、运行时间、成本的关系;下半部分展示各模型零分轨迹的失败原因。 失败分析呈现出两种相反的时间管理问题。 第一种是过早结束。GPT 5.4 和 Grok 4-20 经常只做少量探索便提交,剩余的大量时间没有被利用。 第二种是无法收敛。DeepSeek V4 Pro、Hunyuan 3 Preview 和 Qwen 3.6 Plus 更容易持续思考或迭代到预算耗尽,却没有留下可提交的最终方案。 部分开源权重模型还会进入极长推理链。例如 DeepSeek V4 Pro 在 CUDA 任务的 12 次运行中,有 9 次在超时前执行动作不足 10 次。模型看似投入了大量推理,但很少将推理转化为实际命令和实验反馈。 此外,指令违规并未因模型能力增强而消失。Gemini 3.1 Pro 和 GLM-5 均出现多次违反约束的情况,说明长程执行中的规则保持仍然是独立能力。
图 7:上半部分展示得分与步骤、运行时间、成本的关系;下半部分展示各模型零分轨迹的失败原因。 失败分析呈现出两种相反的时间管理问题。 第一种是过早结束。GPT 5.4 和 Grok 4-20 经常只做少量探索便提交,剩余的大量时间没有被利用。 第二种是无法收敛。DeepSeek V4 Pro、Hunyuan 3 Preview 和 Qwen 3.6 Plus 更容易持续思考或迭代到预算耗尽,却没有留下可提交的最终方案。 部分开源权重模型还会进入极长推理链。例如 DeepSeek V4 Pro 在 CUDA 任务的 12 次运行中,有 9 次在超时前执行动作不足 10 次。模型看似投入了大量推理,但很少将推理转化为实际命令和实验反馈。 此外,指令违规并未因模型能力增强而消失。Gemini 3.1 Pro 和 GLM-5 均出现多次违反约束的情况,说明长程执行中的规则保持仍然是独立能力。十、Agent Harness 不是实现细节
很多评测把 Agent Harness 视为模型外部的固定工具,但 AUTOLAB 的消融实验表明,Harness 可以显著改变模型得分、成本和相对排名。 研究者选择 MiMo V2.5、DeepSeek V4 Flash、GPT 5.4 和 Kimi K2.6,在 25 个 CPU 任务上比较 Terminus-2、Pi-Mono 和经过优化提示的 Mini-SWE-Agent。 同一个模型更换 Harness 后,平均分最多变化约 0.43。例如 Kimi K2.6 在 Pi-Mono 上只有 0.21,在鼓励持续优化的 Mini-SWE-Agent 上达到 0.64。 排名也会发生逆转:
- Pi-Mono 更适合 GPT 5.4;
- Mini-SWE-Agent 更适合 Kimi K2.6;
- Terminus-2 的结果大致位于两者之间。
图 8:同一基础模型在不同 Agent Harness 下的得分与成本明显变化,模型排名也不是固定不变的。 Harness 还决定了推理成本。Kimi K2.6 在 Pi-Mono 下单次约 0.40 美元,在 Mini-SWE-Agent 下约 2.05 美元,相差超过 5 倍。 更有启发性的发现是,迭代型 Harness 对较弱模型帮助更大。DeepSeek V4 Flash 配合 Mini-SWE-Agent 后,在约 0.07 美元单次成本下达到 0.54,进入较好的成本—性能前沿。 这说明,智能体能力不能只归因于基础模型。系统提示、终止策略、上下文管理、工具接口、结果保存和回退机制,都可能决定模型是否真正发挥能力。
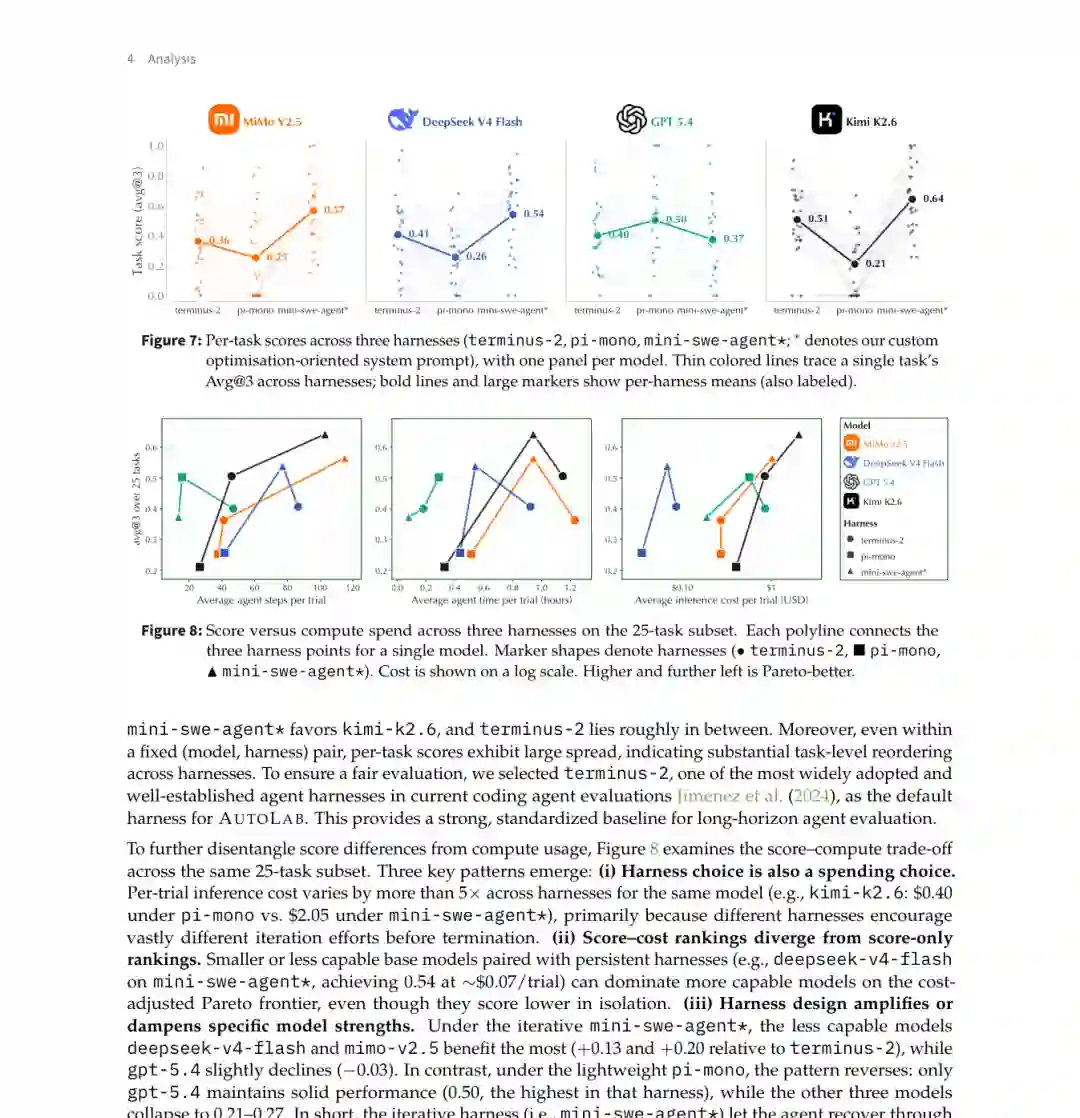 图 8:同一基础模型在不同 Agent Harness 下的得分与成本明显变化,模型排名也不是固定不变的。 Harness 还决定了推理成本。Kimi K2.6 在 Pi-Mono 下单次约 0.40 美元,在 Mini-SWE-Agent 下约 2.05 美元,相差超过 5 倍。 更有启发性的发现是,迭代型 Harness 对较弱模型帮助更大。DeepSeek V4 Flash 配合 Mini-SWE-Agent 后,在约 0.07 美元单次成本下达到 0.54,进入较好的成本—性能前沿。 这说明,智能体能力不能只归因于基础模型。系统提示、终止策略、上下文管理、工具接口、结果保存和回退机制,都可能决定模型是否真正发挥能力。
图 8:同一基础模型在不同 Agent Harness 下的得分与成本明显变化,模型排名也不是固定不变的。 Harness 还决定了推理成本。Kimi K2.6 在 Pi-Mono 下单次约 0.40 美元,在 Mini-SWE-Agent 下约 2.05 美元,相差超过 5 倍。 更有启发性的发现是,迭代型 Harness 对较弱模型帮助更大。DeepSeek V4 Flash 配合 Mini-SWE-Agent 后,在约 0.07 美元单次成本下达到 0.54,进入较好的成本—性能前沿。 这说明,智能体能力不能只归因于基础模型。系统提示、终止策略、上下文管理、工具接口、结果保存和回退机制,都可能决定模型是否真正发挥能力。十一、稳定性与最高分是两回事
AUTOLAB 每个任务运行三次,因为长程智能体具有明显随机性。一个模型可能某次得到 0.85,另外两次只有 0.20;另一个模型可能稳定保持在 0.60 左右。两者平均分接近,但实际可靠性完全不同。 附录结果显示,Claude Opus 4.6 不仅得分最高,也是跨次运行最稳定的模型。Kimi K2.6 等模型虽然平均能力较强,但波动更大。 论文还发现,Best@3 与 Avg@3 的差距会随方差增大而扩大,两者相关系数达到 0.84。只报告三次中的最好成绩,会系统性高估不稳定模型。 因此,对长程 Agent 的评价至少应同时报告:
- 平均能力;
- 最佳能力;
- 失败率;
- 跨次稳定性;
- 时间与推理成本;
- 完整执行轨迹。
单一排行榜分数无法描述一个自动科研系统是否真正可靠。
十二、这项研究带来的启示
从“回答能力”转向“工作能力”
未来智能体的价值不只在于生成一个正确答案,而在于能否完成持续数小时的工作流程。读取反馈、保存有效版本、控制风险和按时交付,会成为与推理能力同等重要的指标。
时间感知需要进入模型与系统设计
智能体应该显式追踪剩余预算,并根据任务阶段调整策略。接近截止时间时,系统应自动减少高风险探索,恢复当前最佳版本,执行最终验证并确保提交。
应保存轨迹中的最佳方案
论文案例显示,部分模型在中间阶段曾达到较好结果,随后错误地覆盖或放弃了它。一个实用 Harness 应持续保存最佳指标、对应代码和验证状态,避免最终提交比中间结果更差。
推理必须尽快转化为实验
长时间内部思考并不等价于有效研究。对于可执行任务,系统应鼓励模型快速建立基线,用小实验排除错误方向,再把计算预算集中到有希望的方案上。
模型与 Harness 应共同评估
基础模型排行榜不能直接代表完整 Agent 系统的表现。未来评测应明确说明 Harness、提示词、终止条件、工具权限和成本预算,并尽量进行跨 Harness 对比。
十三、局限与适用范围
AUTOLAB 主要评估具有明确执行环境和量化指标的系统及机器学习工程任务。它可以衡量“可验证的自动研究”,但不能覆盖提出科学问题、设计新理论或判断研究意义等更广义的科学发现能力。 长程评测还高度依赖外部执行栈,包括 API 稳定性、Docker 环境、GPU 硬件、网络和 Agent Harness。即使基础模型不变,系统配置也可能改变结果。 此外,单个任务耗时 2 至 12 小时,大规模复现实验成本较高。论文已经消耗 2544 小时和 86 亿 token,这类基准很难像普通问答测试一样频繁运行。 不过,正是这些成本让它更接近真实工作。AUTOLAB 的意义不在于提供又一个静态排行榜,而在于建立一套面向长程、闭环和可验证优化的评价范式。
结语
AUTOLAB 揭示了当前前沿模型的一个关键能力缺口:许多模型已经能写出不错的第一版方案,却还不能稳定地像工程师或研究者一样持续工作。 真正的自动科研智能体需要的不只是更强推理,还需要坚持迭代、时间感知、实验纪律、版本管理、约束遵循与可靠提交。 从这个角度看,下一阶段 Agent 竞争可能不会只发生在基础模型参数和训练数据上。谁能构建更好的闭环系统,让模型在数小时内持续学习实验反馈、保存进展并稳健收敛,谁才更接近真正可用的自动研究与工程智能。
论文信息
- 论文标题:AUTOLAB: Can Frontier Models Solve Long-Horizon Auto Research and Engineering Tasks?
- 论文编号:arXiv:2606.05080
- 发布时间:2026 年 6 月 3 日
- 代码仓库:https://github.com/autolabhq/autolab
- 项目网站:https://autolab.moe
- 论文链接:https://arxiv.org/abs/2606.05080

