
导读
在科学研究的自动化浪潮中,AI智能体正从回答简单问题、运行预定义流程,逐步迈向能自主提出并执行研究步骤的新阶段。从蛋白质工程到语言模型优化,已有智能体系统能生成假设、设计实验、编写代码、并基于实验反馈改进模型。然而,现实中的科学实验往往是长期的、探索性的,需要持续的并行假设验证、灵活的方向调整,以及对失败经验的有效沉淀。现有AI智能体通常局限于短期任务,要么沿着单一轨迹前进,要么通过中央规划器协调固定目标,这使得它们在面临证据变化或需要并行探索时显得力不从心。 为了解决这一痛点,来自哈佛大学的研究团队(Shanghua Gao, Ada Fang, Marinka Zitnik)提出了 AutoScientists,一个去中心化的自组织AI智能体团队系统。其核心创新在于:让多个长期运行的智能体通过共享实验状态进行协调,围绕有前景的假设自发组织成团队,在耗费计算资源执行实验前对提案进行批判,并共享成功与失败的经验以减少冗余探索。AutoScientists并非依赖固定流水线或中央调度员,而是通过智能体间的讨论与一个共享论坛来集体决定研究方向,这标志着AI智能体协作范式从“命令与控制”向“自组织与共识”的转变。 这篇论文值得每位关注AI智能体、科学自动化工具开发以及计算生物学和机器学习的研究者深入阅读。它不仅提出了一个简洁而优雅的框架,还在生物医学机器学习(BioML-Bench)、语言模型训练优化(GPT)和蛋白质适应性预测(ProteinGym)三个极具挑战性的基准上,以匹配的实验预算显著超越了所有现有最先进的AI智能体系统。本文将为您结构化精读这篇论文,剖析其设计精髓与实验结果。
论文基本信息

摘要
科学研究的推进遵循着假设生成、实验设计、执行与修订的迭代循环。AI智能体可以自动化这一过程的部分环节,但现有方法通常遵循单一的研究轨迹,或通过具有固定目标的中央规划器进行协调。因此,它们难以在长期实验中维持并行探索、适应实验证据的变化,或保存失败方向的知识。 本文介绍了 AutoScientists,一个用于长期计算科学实验的去中心化AI智能体团队。智能体能够解释共享的实验状态,围绕有前景的假设自组织成团队,在消耗实验计算资源前对提案进行批判,并共享成功与失败的经验以减少冗余探索。在匹配的实验预算下,AutoScientists在生物医学机器学习、语言模型训练优化和蛋白质适应性预测三个领域均显著优于先前的AI智能体。 在包含生物医学成像、蛋白质工程、单细胞组学和药物发现的24项任务的BioML-Bench上,AutoScientists的平均排行榜百分位达到74.4%,比最强的AI智能体(Autoresearch的66.07%)提升了+8.33%。在GPT训练优化任务中,AutoScientists达到目标验证bits-per-byte的速度是Autoresearch的1.9倍(34个实验 vs 65个实验)。更引人注目的是,在单智能体已无法找到任何改进的起跑线上(val_bpb=0.9777),AutoScientists仍然发现了7个改进,而Autoresearch在相同条件下接受了0个。在ProteinGym适应性预测任务中,AutoScientists发现了一种针对ACE2-Spike结合的方法,其Spearman相关系数比当前最佳模型提升了+12.5%;将该方法不加修改地应用于全部217个ProteinGym试验时,平均提升也达到+6.5%。
引言:论文要解决什么问题
现有AI智能体在科学研究中的应用正从“回答问题和运行预定义工作流”向“提出并执行研究步骤”演进。然而,大多数当前方法仍局限于短视界任务。它们呈现以下核心局限:
- 无法维持并行探索:现有系统通常遵循单一研究轨迹,或者在固定目标下通过中央规划器(如PI-scientist-critic组织或Manager-Developer-Critic管道)进行协调,无法同时并行地追求多个有前景的方向。
- 难以适应实验证据变化:科学实验是动态的,随着实验证据的积累,最初看起来有希望的假设可能被证明是死胡同,而新的方向会涌现。现有智能体缺乏根据实时证据灵活调整研究策略的能力。
- 无法保存失败方向的知识:失败的实验在科学探索中同样宝贵,它们能帮助团队避免重复踏入死胡同。但现有系统往往忽视或丢弃这些失败经验,导致冗余探索和计算资源浪费。
针对上述痛点,AutoScientists提出了一个全新的框架:一个去中心化的、自组织的AI智能体团队,它不依赖固定的流水线或中央调度员,而是通过智能体间的讨论和共享论坛来集体决定研究方向。这个系统旨在解决的核心问题正是:如何在长期计算科学实验中,让多个智能体像人类科研团队一样,进行高效的并行探索、灵活的适应性调整以及失败经验的有效沉淀。
方法:核心思路与技术路线
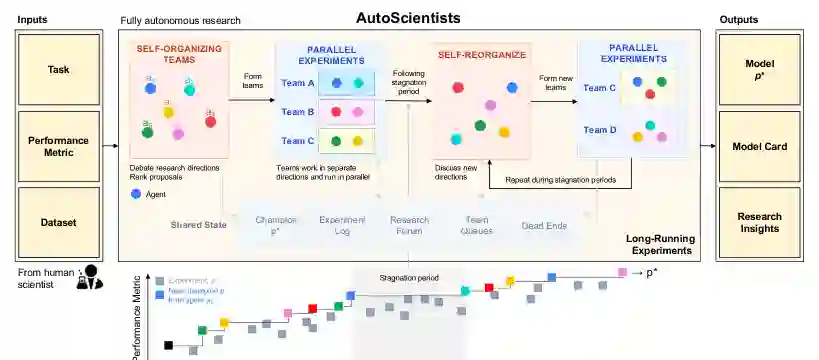
问题形式化
AutoScientists首先将长期科学实验形式化为一个迭代搜索过程。系统接收一个任务描述、一个可选的初始程序(如训练脚本)p0、一个数据集D以及一个评估指标ℓ。数据集D由一个训练集Dtrain和一个评估协议(可以是验证集Dval,或基于Dtrain的交叉验证方案)组成。 一个长期运行的LLM智能体系统 A={a1, ..., an} 会迭代地提出并生成新的程序。这里的长期运行智能体 ai 会持续存在于整个搜索过程中,维护内部状态,并根据累积的经验更新其行为,这与一次性生成解决方案的单次智能体有显著不同。每个被提出的程序p在Dtrain上进行训练,并通过ℓeval进行评估。系统的目标是找到一个最优程序 p*,其中P表示搜索过程中智能体探索的程序空间。
AutoScientists方法:自组织与团队协作
AutoScientists的核心是一个精巧的两阶段循环机制,通过共享状态S而非中央规划器来协调所有智能体。 1. 讨论与自组织阶段
在初始化时,AutoScientists没有预设任何团队或研究方向。当需要讨论时(系统启动时或性能停滞时),所有智能体读取任务描述、当前最优程序(champion)p*,以及共享论坛F上的历史帖子。 讨论过程分为多轮:
- 早期轮次 所有智能体独立分析p*,提出修改方案,相互批判竞争性的提议,并识别搜索空间中的空白。
- 后期轮次 智能体将自身组织成K个团队
{T1, ..., TK},每个团队被分配一个研究方向。讨论轮次中的最后一个智能体会将所有提案整合成一个“任务清单”R,记录每个团队、其研究轴心和成员,并写入共享状态S。后续的智能体会在各自的下一个心跳周期内读取并采纳这个清单。
当一个团队停止产生改进时,会触发新一轮的讨论。智能体可以通过共享论坛提出创建、合并、拆分或重新平衡团队的提案,这些更改需获得受影响团队的认可才能生效。这种机制使得AutoScientists能够在运行过程中动态地重新分配精力,放弃已经枯竭的方向,将资源集中到更有前景的路径上。 2. 执行与共享状态阶段
一旦团队形成,系统进入执行阶段。各团队并行运行实验,并将结果写入共享状态S。共享状态S是协调的核心,它包含了所有当前和历史的实验记录、成功和失败的路径、以及任务清单等关键信息。通过共享状态,智能体可以了解全局进展,避免重复已被验证无效的实验,并从成功的实验中获得启发。 3. 停滞触发与团队重组
当系统在评估指标ℓeval上的性能陷入停滞时,智能体会重新开启讨论。他们会回顾所有团队的实验结果,通过共享论坛进行交流,并可能重新组织团队。这个循环会持续运行,直到设定的预算或时间耗尽。 关键设计亮点:
- 去中心化 没有中央规划器,所有协调通过共享状态S和讨论实现。
- 提案预评估 在执行实验之前,智能体通过讨论批判性地过滤掉弱提案,节省计算资源。
- 知识共享 成功和失败的方向都被记录在共享状态中,减少了冗余探索。
- LLM无关性 AutoScientists方法本身与底层LLM无关,论文中使用的基模型是Claude Code coding agent (Claude Sonnet 4.6)。
- 默认配置 团队由3个分析智能体(负责分析和讨论)和6个实验智能体(负责执行实验)组成,所有智能体使用相同的基模型。
自组织机制为什么重要
AutoScientists 的核心不只是“多开几个智能体并行跑实验”,而是把长期科研实验拆成了三个相互耦合的机制:共享状态、团队自组织和停滞后的重组。共享状态让所有智能体都能看到当前 champion、实验日志、研究论坛、团队队列和 dead-end registry;团队自组织让智能体围绕不同研究方向形成小组,而不是由一个中心规划器固定分配任务;当某个方向停止产生改进时,系统会重新进入讨论阶段,让团队合并、拆分或转向新假设。 这种设计的关键价值在于,它把科学探索中的“失败知识”也纳入系统记忆。许多自动化科研系统只保留成功结果,但长期实验真正昂贵的是反复走进同一个死胡同。AutoScientists 将失败方向、拒绝理由和实验诊断写入共享状态,使后续智能体可以绕开低价值搜索区域,把预算集中到更有希望的方向上。
实验:设置、指标与结果
实现细节
所有智能体使用相同的基模型:Claude Code coding agent,基础LLM为Claude Sonnet 4.6。每个智能体由一个确定性监视器在心跳循环中重复调用。AutoScientists被分配了H100 GPU用于执行实验。默认团队配置为3个分析智能体和6个实验智能体。
数据集与评价指标
- BioML-Bench:一个包含24项端到端生物医学机器学习任务的基准,涵盖生物医学成像(4项)、药物发现(9项)、蛋白质工程(6项)和单细胞组学(5项)。每个任务提供自然语言任务描述、训练数据、测试输入和示例提交格式。主要评价指标为排行榜百分位(leaderboard percentile,相对于公开人类提交),同时报告是否超过排行榜中位数、是否获得奖牌以及完成率。
- GPT训练优化:使用Autoresearch引入的GPT nanochat训练优化基准。每次实验是单次5分钟的GPT训练运行,在单个H100 GPU上执行,通过验证bits-per-byte (val_bpb) 进行评估(数值越低越好)。
- ProteinGym:包含217个试验的适应性预测基准,使用Spearman相关系数评估预测的排序准确性。
主实验结果
1. BioML-Bench结果
AutoScientists在所有已评估系统中取得了最高的平均排行榜百分位,达到74.40%(标准误差6.20%),相比最强的AI智能体Autoresearch的66.07%(7.38%)提升了+8.33个百分点。AutoScientists完成了全部24项任务,成为唯一一个在所有任务中都生成可行输出的系统。 从领域层面看,AutoScientists在药物发现领域提升最大,平均排行榜百分位达到64.52%(8.37%),远超Biomni的47.91%(10.77%)。在蛋白质工程领域,虽然绝对值很高(96.97%),但该领域已较为饱和,AutoScientists和Autoresearch都达到了相近数值。生物医学成像是最具挑战性的领域,每个任务都需要大规模图像模型训练。 2. GPT训练优化结果
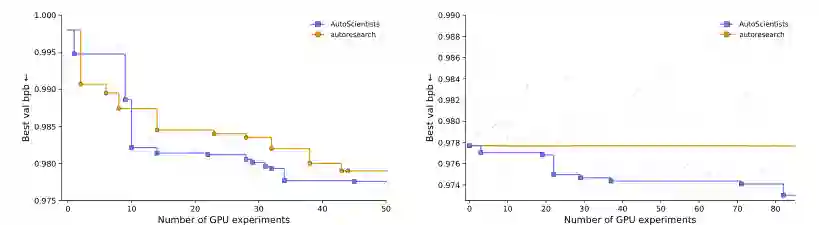
- 从Autoresearch基线出发 当AutoScientists和Autoresearch从相同的基线代码(val_bpb=0.998)开始搜索时,AutoScientists在34个实验后达到了val_bpb≈0.978,而Autoresearch需要65个实验才能达到相同值。这意味着AutoScientists实现了1.9倍的加速。
- 从AutoScientists champion出发 更令人印象深刻的是,当两者从AutoScientists经过50个实验后获得的最优程序(val_bpb=0.9777)出发,并给予相同的“死胡同”知识文件(EXPLORED.md),AutoScientists在93个实验中接受了7个改进,最终达到val_bpb=0.9730;而Autoresearch在100个实验中接受了0个改进。这充分展示了AutoScientists在已经高度优化的起点上继续发现改进的能力,而这种场景下单智能体方法已经完全失效。
3. ProteinGum结果
AutoScientists发现了一种针对ACE2-Spike结合预测的方法,其Spearman相关系数比当前最佳模型提升了**+12.5%。更令人惊叹的是,将该方法不加任何修改地应用于全部217个ProteinGym试验时,平均Spearman相关系数比先前最佳结果提升了+6.5%**。这表明AutoScientists发现的方法不仅针对单一任务有效,还具有很强的泛化能力。
与固定流水线范式的差异
AutoScientists 与许多现有 AI 科研智能体的差异,可以概括为从“任务流水线”转向“研究社区”。固定流水线通常将角色预先写死,例如规划者提出想法、开发者实现代码、评审者打分,整个系统围绕一个中心目标推进。这类设计在短任务中清晰高效,但在长期科学实验中容易形成单一路径依赖:一旦早期方向判断错误,后续实验就会不断围绕错误方向做局部修补。 AutoScientists 则允许多个团队在不同假设上并行工作,并让团队结构随着证据变化而重组。它把“谁该继续探索什么方向”本身也作为一个动态决策问题,而不是固定配置。这一点非常接近真实科研团队:研究者会开组会、争论方向、暂停低收益路线、把一个方向拆成多个子方向,或把两个相近方向合并。论文的价值就在于把这种组织行为转化成可执行的智能体机制。 从工程实现角度看,共享状态 S 是这套系统的“组织记忆”。Champion 记录当前最优模型和复现实验所需的超参数;experiment log 保留每次实验的结果和诊断;research forum 记录提案、反驳和机制解释;team queues 与 dead ends 则让各团队知道哪些方向正在被探索、哪些方向已经被证明低收益。没有这些结构,多个智能体很容易退化为彼此独立的随机搜索;有了这些结构,系统才可能形成持续积累的集体搜索。
结果解读
从结果看,AutoScientists 的优势主要体现在两类场景。第一类是搜索空间大、单次实验成本高、需要跨方向试错的任务,例如 BioML-Bench 中的药物发现和生物医学机器学习任务。系统通过团队并行探索和提案预评估提高了有效实验比例。第二类是已经接近局部最优、单智能体继续优化困难的任务,例如 GPT nanochat 训练优化中从 AutoScientists champion 出发的设置。此时 Autoresearch 在 100 次实验中没有接受任何改进,而 AutoScientists 仍能接受 7 个有效修改,说明团队讨论和 dead-end registry 对突破停滞有实际作用。 需要注意的是,这些结果并不意味着任意增加智能体数量都会更好。论文附录提到团队规模涉及并行性收益和过度订阅之间的权衡:智能体过少会限制探索宽度,智能体过多则可能带来协调和重复成本。因此,AutoScientists 的贡献更准确地说是提出了“可重组的长期科研团队结构”,而不是简单的暴力并行。
消融与分析
论文包含专门的消融实验章节(Ablations of AutoScientists)和附录扩展消融结果。虽然原文未明确说明具体的消融数值,但附录中展示了与Autoresearch在匹配和扩展计算下的比较,以及团队规模敏感性分析(并行性增益和过度订阅)。图5通过实例展示了AutoScientists如何实现智能体多样化、识别饱和方向、在不同团队间转移假设以及退出死胡同方向等关键行为,为系统的有效性提供了定性支持。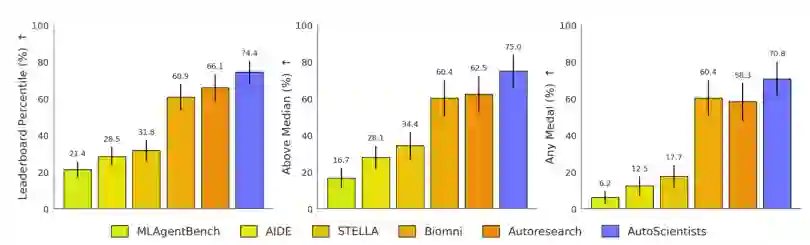
结论:贡献、局限与启发
主要贡献
- 提出了新颖的自组织智能体团队范式:AutoScientists通过去中心化的讨论和共享状态,解决了现有AI智能体在面对长期科学实验时难以维持搜索、适应变化和沉淀知识的问题。
- 在三个挑战性基准上取得了显著性能提升:在BioML-Bench、GPT训练优化和ProteinGym上,AutoScientists在匹配实验预算下均优于最先进的AI智能体,最高提升幅度达到+12.5%。
- 证明了“集体搜索”优于“个体寻优”:AutoScientists通过提案预评估、记录成功和失败方向、共享状态以及在进展停滞时重组团队,使得实验试错更加高效,避免了重复踏入死胡同,并且能在单智能体已经无法继续改进的平台上持续发现有效的修改。
局限性与未来工作
原文未明确说明局限性。但从论文设计和实验设置中,我们可以推断出一些潜在局限:系统性能高度依赖于底层LLM(Claude Sonnet 4.6)的推理和任务规划能力;团队规模(9个智能体)和共享状态的维护带来了额外的计算和协调开销;在非常依赖领域先验知识的任务中,通用LLM可能面临挑战。
启发与展望
AutoScientists不仅是一个具体的AI系统,更代表了一种科学研究新范式的雏形。它展示了如何通过模仿人类科研团队的集体协作机制(如讨论、同行评审、知识共享、动态重组)来增强AI系统在复杂长期任务中的能力。对于AI智能体研究者而言,这意味着未来的工作可以更多地关注“如何设计智能体之间的交互规则”,而不仅仅是“如何训练更强的单一智能体”。对于科学自动化工具开发者而言,AutoScientists提供了一个优雅的架构,可应用于各种需要长期并行探索的计算科学领域。
对科学自动化的启发
这篇论文给科学自动化工具的启发是:未来的 AI 科研系统不应只追求“单个智能体更聪明”,还要设计“多个智能体如何协同”。在计算生物、材料发现、模型训练优化等领域,真正的瓶颈往往不是生成一个候选方案,而是在有限预算内管理大量候选方向、识别停滞、复用失败经验,并把局部发现迁移到新的团队或任务中。 AutoScientists 也提醒我们,科研智能体需要产出可审计的过程,而不只是最终分数。模型卡、实验日志、失败方向注册表和研究发现报告,使人类科学家能够追踪最终结果是如何出现的。这一点对高风险领域尤其重要:如果一个系统自动发现药物筛选模型或蛋白适应性预测方法,人类需要知道它依赖了哪些数据、尝试过哪些方向、为什么放弃某些方案,以及最终模型在哪些边界条件下可靠。
原文信息
本文内容基于以下论文的结构化精读: AutoScientists: Self-Organizing Agent Teams for Long-Running Scientific Experimentation
作者:Shanghua Gao, Ada Fang, Marinka Zitnik 原文链接:http://arxiv.org/abs/2605.28655v1