
周期表视角下的大模型推理综述:范式、方法与失败模式
论文标题:The Periodic Table of LLM Reasoning: A Structured Survey of Reasoning Paradigms, Methods, and Failure Modes 论文链接:https://arxiv.org/abs/2606.11470 作者:Avinash Anand, Mahisha Ramesh, Avni Mittal, Ashutosh Kumar, Erik Cambria, Zhengkui Wang, Timothy Liu, Aik Beng Ng, Simon See, Rajiv Ratn Shah

大语言模型已经在问答、编程、数学、检索和多模态任务中表现出越来越强的推理能力,但“模型是否真的在推理”仍然是一个复杂问题。很多时候,模型能给出正确答案,却无法稳定解释过程;能在熟悉 benchmark 上表现很好,却在分布迁移、长链条推理、跨语言或社会认知场景中迅速退化。 这篇 103 页综述系统梳理了 300 多篇近年论文,试图用“周期表”的方式组织 LLM 推理研究:不同推理范式不是孤立方法,而是分布在“分解、领域、语境、增强、学习反思、跨边界”六类组合维度,以及从基础训练到高阶认知的不同层级上。论文的价值不在于简单罗列方法,而在于把 CoT、多跳、数学、常识、多模态、代码、RAG、工具智能体、RL、多语言、元推理和社会认知放进同一张地图。 导读
这篇综述可以从三个问题理解。 第一,LLM 推理到底发生在哪里?论文认为,推理不是模型内部运行了显式符号引擎,而是在“上下文流、注意力/MLP、下一 token 分布、采样与搜索”反复循环中外化出来。CoT、工具调用、检索结果和中间草稿,本质上都进入上下文流,成为后续 token 的条件。 第二,当前推理研究有哪些主要范式?论文提出 36 类方法族,覆盖 Chain-of-Thought、多跳推理、数学推理、视觉/多模态、RAG、工具增强、RL 推理、多语言、元推理、自校正、社会认知等,并进一步把它们映射到统一的“问题-分解-检索-步骤-验证-聚合-答案”流程中。 第三,为什么“准确率提升”不足以证明推理能力?论文反复强调,推理评估不能只看最终答案,还必须关注忠实性、鲁棒性、校准、跨域泛化、效率与安全。否则 benchmark 可能高估进展,掩盖模型在因果抽象、多步一致性、跨语言公平和社会偏见上的失败。
1 Introduction | 引言
论文开篇指出,LLM 的推理能力已经覆盖多步问题求解、组合推理、时间一致性、有限因果/反事实推理等任务,但这些能力高度依赖提示方式、任务表述、模型规模和评测方法。规模提升通常会增强推理表现,却不能保证推理稳定;CoT 能展示中间步骤,却不一定忠实反映模型真实计算过程。 作者把 LLM 推理放回模型生成机制中理解:模型每次前向传播都根据已有上下文生成下一个 token 的分布;一条完整的推理链,是数百次这种决策串联起来的结果。所谓“模型写下中间步骤”,其实是把中间状态写回上下文,让后续生成可以引用这些文本痕迹。
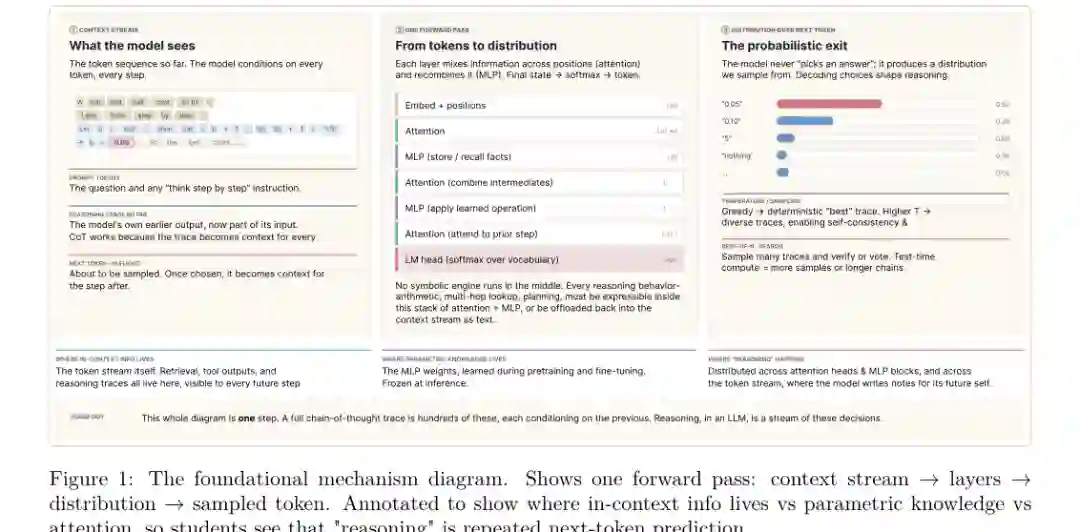
这解释了为什么 CoT 有时有效:它把中间结论显式放入上下文,为后续步骤提供可访问的状态。但它也解释了 CoT 的局限:文本化理由可能只是事后合理化,并不保证每一步都忠实、必要或正确。因此,论文将推理能力视为多个子能力的组合,包括分解、检索、验证、计划、执行、反思、跨模态对齐和社会认知。
2 Methodology | 方法论
论文采用结构化文献综述方法,从 arXiv、Semantic Scholar、Google Scholar、Papers with Code 和 ACL Anthology 收集 300 多篇论文。筛选标准包括主题相关性、近五年代表性、方法清晰度、实验证据、创新性和可复现性。 从覆盖分布看,代码/算法推理、元推理/RAG/RL/CoT/数学/工具增强等方向占据较大比例;常识、时序、多跳和社会认知类论文数量相对较少。这种分布本身说明了研究重心:社区正在从“让模型说出推理步骤”转向“让模型搜索、验证、调用工具、学习反思,并在复杂环境中保持一致”。
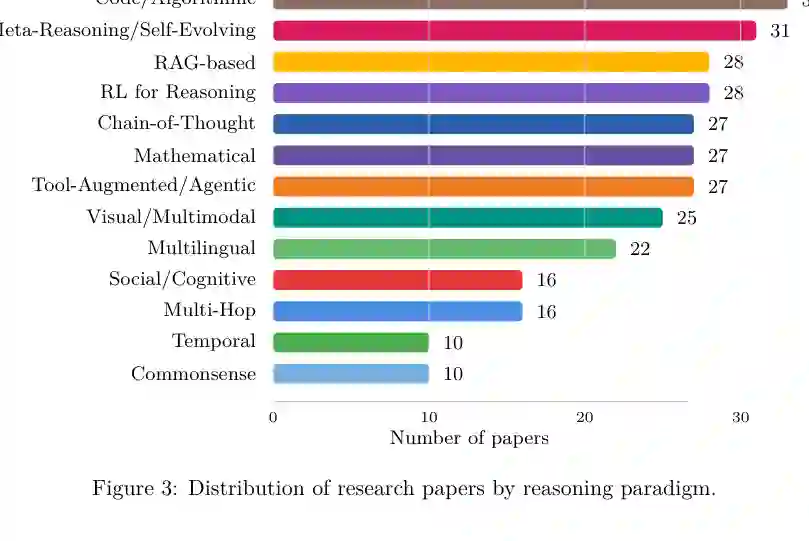
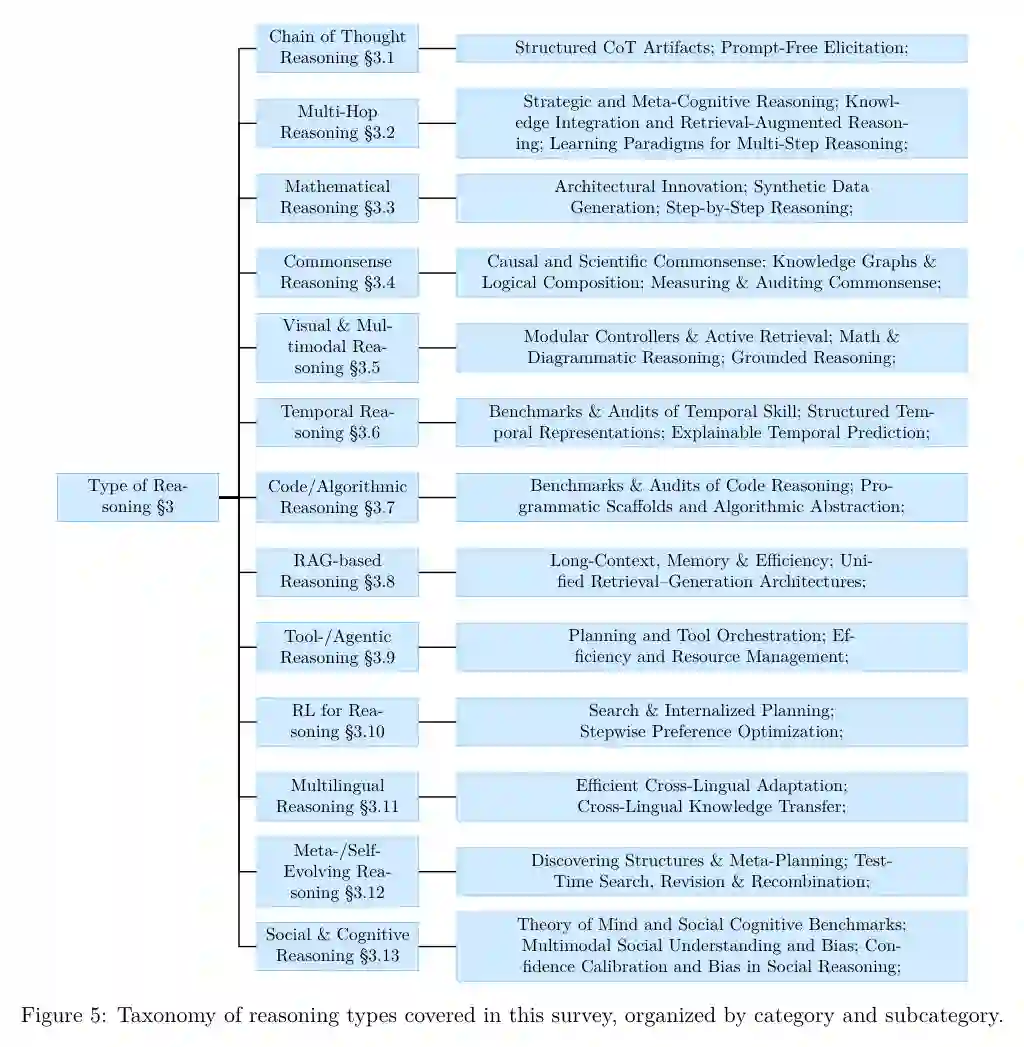
作者进一步将文献组织成层级化分类:一方面按推理类型划分,如 CoT、多跳、数学、常识、多模态、时序、代码、RAG、工具/智能体、RL、多语言、元推理和社会认知;另一方面分析每类中的方法趋势、实验设置和开放问题。
3 Type of Reasoning | 推理类型
论文最核心的贡献是“LLM 推理周期表”。它把 36 类方法组织成 6×6 网格:列表示组合范式,包括逐步分解、领域特化、语境与接地、增强推理、学习与反思、跨边界推理;行表示从基础技巧到高阶认知的层次。

这张图的意义在于,它提醒我们不要把 CoT、RAG、工具调用或 RL 看成互斥方案。现代推理系统往往会同时占据多条路线:先用 CoT 分解问题,再用 RAG 检索证据,用工具执行计算,用 verifier 打分,用 self-consistency 或搜索聚合答案。
推理范式的总图
论文将推理类型进一步展开为树状结构:CoT 强调显式中间步骤;多跳推理强调跨证据整合;数学和代码推理要求可执行、可验证、严格正确;常识与社会认知要求世界知识、意图理解和价值敏感性;RAG、工具增强和智能体推理把外部知识、搜索、API 与执行环境纳入推理回路;RL 和元推理则把推理过程本身变成可学习、可搜索、可优化对象。
论文还提出一个统一骨架:Question -> Decompose -> Retrieve -> Step -> Verify -> Aggregate -> Answer。不同范式的差异,主要体现在是否需要分解、是否检索外部证据、是否执行工具、是否验证中间步骤、是否聚合多条路径。
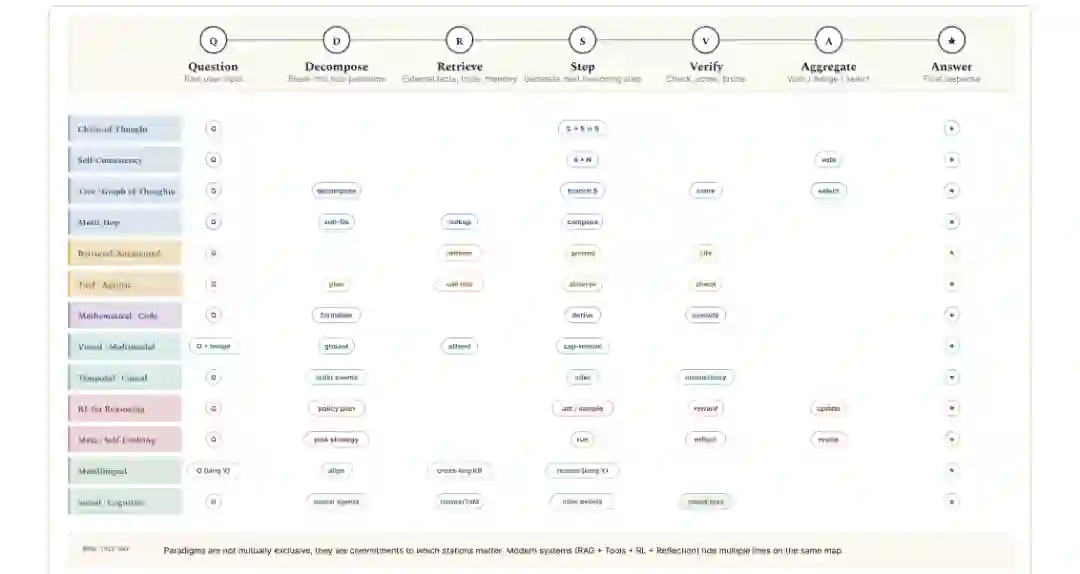
逐步分解与多跳推理
CoT 的基本价值是把隐式问题求解转化为显式中间步骤,从而让模型更容易维护状态、执行顺序推理,并允许人类或外部模块检查局部错误。但论文提醒,CoT 对符号、数学、多步结构任务收益更明显,对依赖直觉、常识或隐式认知的任务未必稳定。 多跳推理则进一步要求模型跨多个实体、文档或事实链条建立联系。其常见失败包括第一跳检索成功但后续知识整合失败、证据顺序扰动导致结论变化、模型只拼接相似文本而没有真正组合逻辑。近年来的方向包括战略性检索、图结构知识融合、RAG 与多跳推理结合、以及更细粒度的中间链路评测。
数学、代码与可验证推理
数学推理是检验 LLM 推理质量的强约束场景,因为一个小错误就可能破坏整条解题链。论文总结的主要趋势包括:架构层面的数学能力增强、合成数据生成、过程监督、推理时搜索与验证、以及面向 Olympiad 难题的高阶抽象评估。
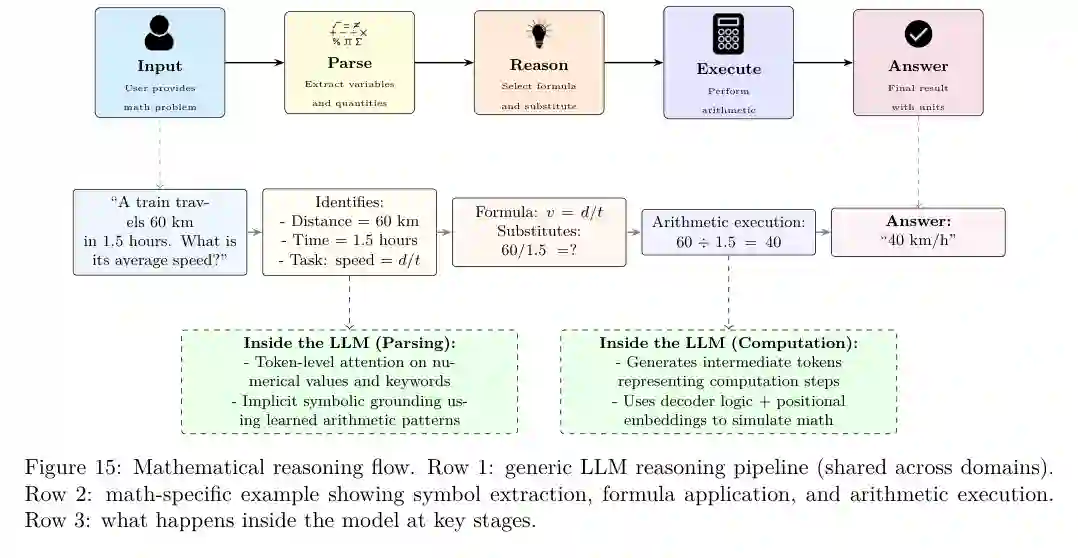
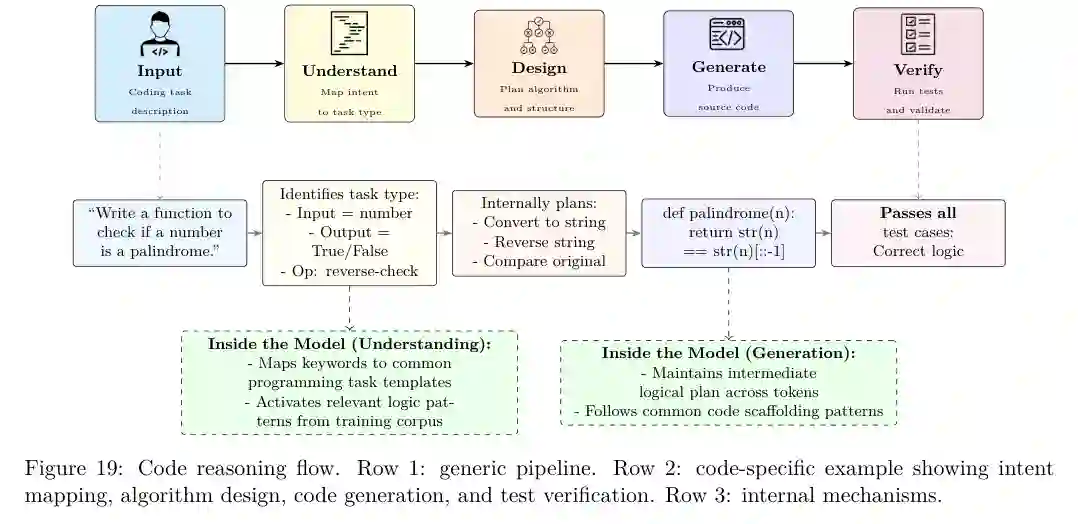
代码和算法推理与数学类似,但更强调可执行性。模型不仅要理解任务意图,还要设计程序结构、生成代码并通过测试验证。论文认为,代码推理研究正在从“补全代码”走向“可执行脚手架、单元测试、程序验证和真实软件工程任务”。
RAG、工具增强与智能体推理
RAG 扩展了模型的外部知识访问能力,尤其适用于事实性、多文档、长上下文和知识密集型任务。论文指出,RAG 推理并不是简单“检索后回答”,而是涉及查询改写、文档检索、重排序、证据融合、答案生成和多维评价。
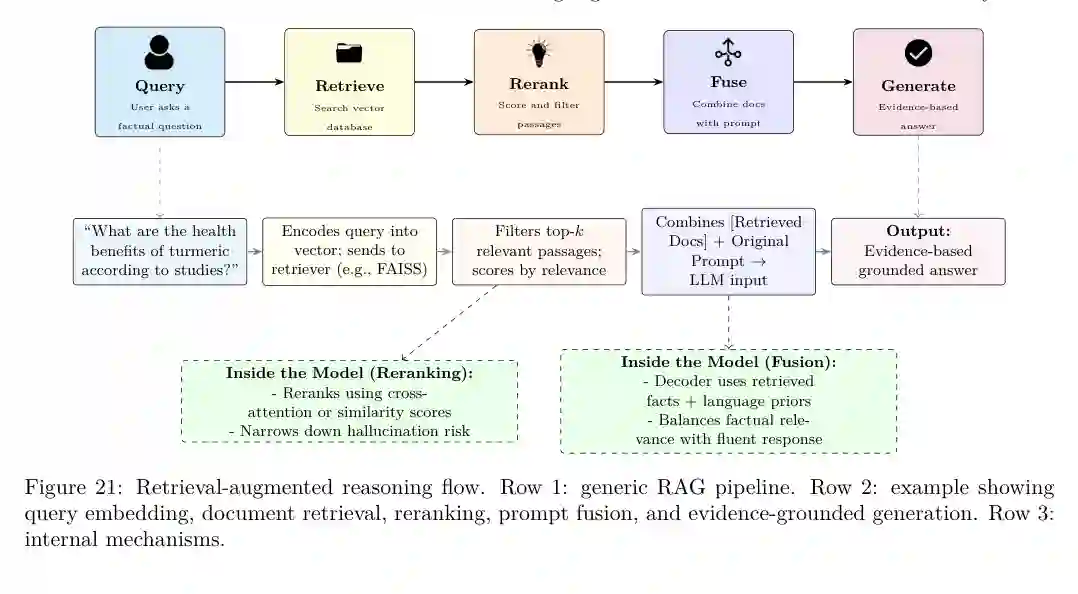
工具增强和智能体推理则把 LLM 从被动文本生成推进到交互式问题求解。模型可以规划任务、调用搜索、计算器、代码解释器或 API,并根据工具返回结果调整策略。它缓解了模型无法访问实时信息、精确计算和长程记忆的问题,但也引入了工具选择错误、执行失败、安全边界和多步状态管理难题。
强化学习与元推理
RL for reasoning 的关键不只是提高最终答案,而是学习搜索策略、优化推理链、分配测试时计算,并通过过程奖励鼓励更可靠的中间步骤。论文把这一方向概括为三根杠杆:学会搜索、优化推理链、治理计算预算。
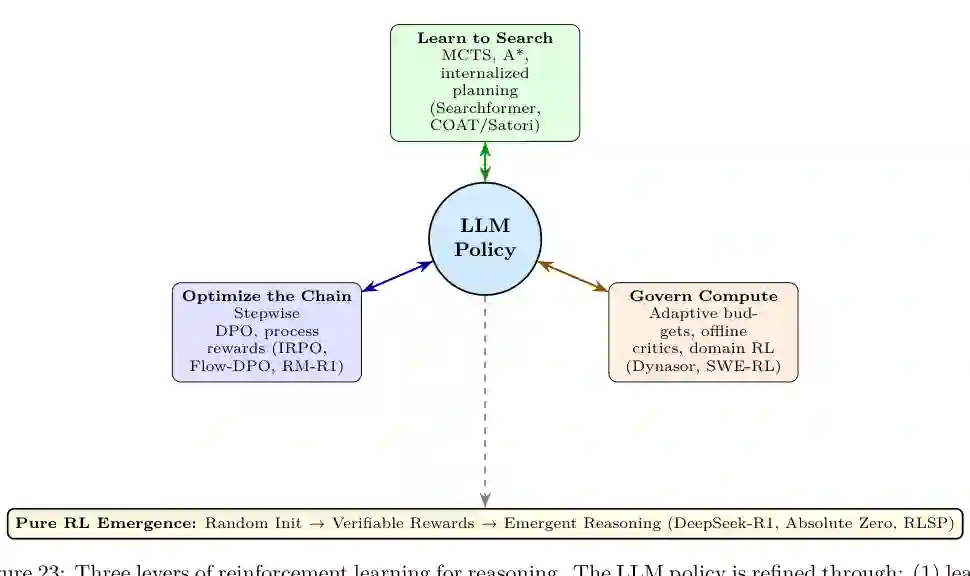
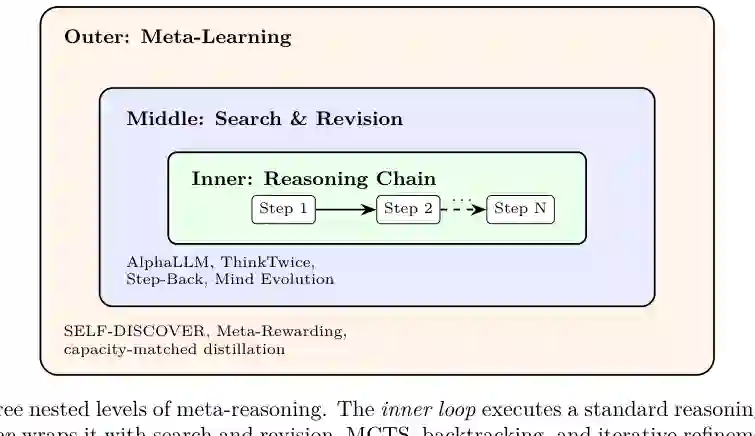
元推理进一步把“模型自己的思考”当作对象来计划、批判、修改和扩展。论文将其分为三层:内层是标准推理链,中层是搜索与修订循环,外层是发现可复用推理结构、匹配模型容量并通过元评判器优化。
多语言、社会认知与安全
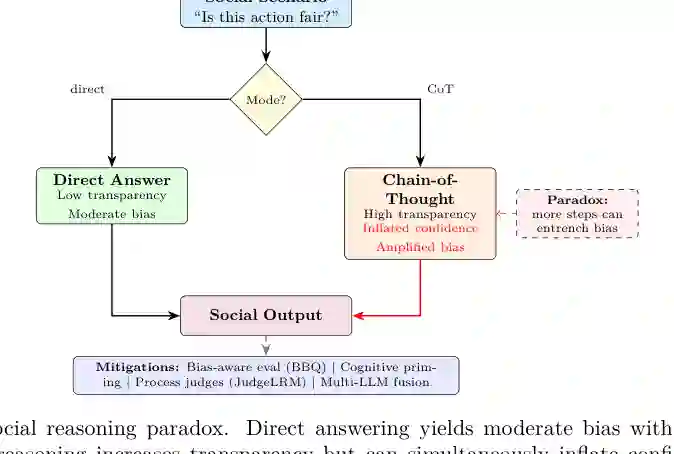
多语言推理强调跨语言知识迁移、推理路径对齐和低资源语言公平。论文指出,翻译正确不等于推理一致;不同语言中的知识结构、文化常识和表达方式可能导致推理路径偏移。 社会与认知推理要求模型理解信念、意图、情绪、社会规范和群体互动。这类任务尤其容易暴露模型的偏见、过度自信和价值错配。论文提出一个“社会推理悖论”:CoT 提升透明度,但也可能放大信心和社会偏见,因此需要偏见感知评测、过程级 judge 和多模型融合。
4 Synthesis and Open Challenges | 综合与开放挑战
论文在综合部分强调,当前推理研究的核心矛盾,是“可见的准确率提升”与“不可见的推理质量”之间的落差。一个模型可能在最终答案上得分高,却缺乏忠实推理链、跨域鲁棒性、概率校准、长程一致性和安全可控性。
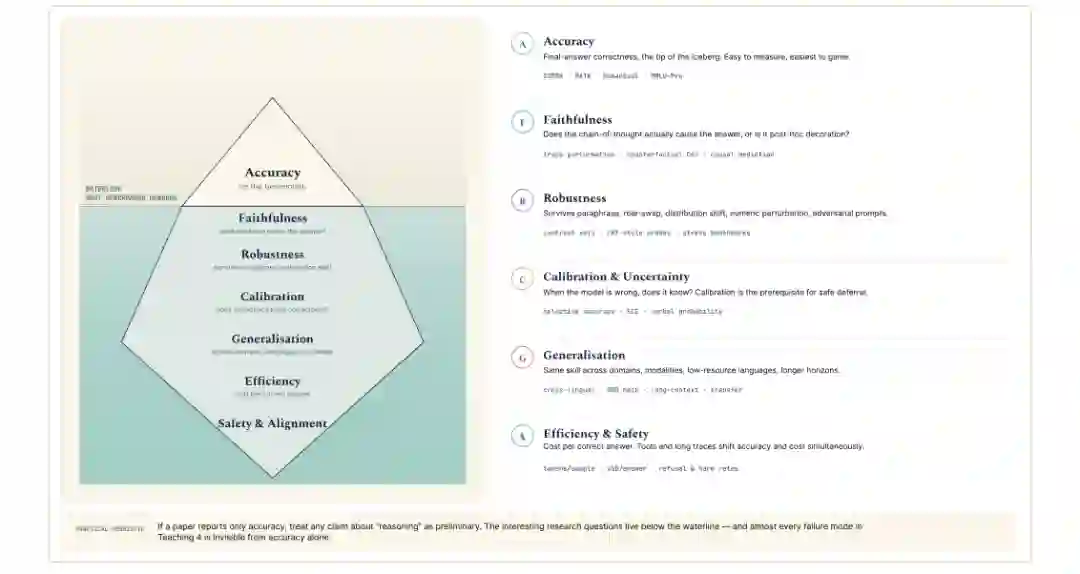
作者总结的开放挑战包括:
- 忠实性:推理链是否真的导致答案,还是事后装饰?
- 鲁棒性:换一种表述、改变证据顺序、加入干扰项,模型是否仍能保持逻辑稳定?
- 校准:模型是否知道自己何时不确定,能否安全拒答或寻求工具帮助?
- 泛化:推理能力能否迁移到新领域、新语言、新模态和更长时间跨度?
- 效率:更长 CoT、更多采样、更多工具调用是否值得其成本?
- 安全:智能体工具调用、社会推理和多语言部署是否会引入新的偏见与攻击面?
论文认为,未来更有希望的方向不是继续孤立堆叠某一种技巧,而是构建统一推理框架:内部推理与外部知识访问结合,过程监督与奖励建模结合,工具执行与安全治理结合,跨语言与跨模态表示对齐结合。换言之,下一阶段的推理系统更像“可控的混合架构”,而不是单一 prompt 技巧。
5 Conclusion | 结论
这篇综述把 LLM 推理研究从零散方法整理成一张结构化地图。它既承认 CoT、RAG、工具调用、RL 和元推理带来的真实进展,也明确指出当前推理能力仍然统计化、脆弱且分布敏感。模型能生成类似推理的文本,并不意味着它拥有稳定、可验证、可泛化的推理机制。 最重要的启发是:评估推理不能只问“答对了吗”,还要问“为什么答对、过程是否忠实、换个场景是否仍然成立、代价是否可接受、风险是否可控”。如果只用准确率衡量推理,很多失败模式会被 benchmark 掩盖。 面向未来,论文提出的方向非常清晰:发展模块化、工具增强、认知对齐的推理系统;用过程监督、奖励模型和验证器提升中间步骤质量;将代码执行、检索、记忆和多模态接地纳入推理闭环;并建立能同时衡量推理深度、连贯性、泛化性和安全性的统一评价框架。 对于研究者和工程实践者而言,这篇综述的意义在于提供了一张“导航图”:当我们谈论大模型推理时,不能只谈 CoT 或 RL,而要看它处在推理周期表的哪一格、解决流程中的哪一环、对应哪种失败模式,以及是否真的提升了水面之下的推理质量。
