
视觉语言模型(VLM)的根本目标是实现“感知-推理协同”(perception-reasoning synergy)。这就像人类一边看、一边想,看到细节后修正推理,推理后引导新的观察。但当前VLM的实践呈现出一种令人困惑的“跷跷板效应”:当模型在视觉感知上投入更多时,推理能力反而下降;反之亦然。这不禁让人怀疑——是感知出了问题,还是推理出了问题?在工业化的多模态应用中,这种模糊性使得模型难以系统性地改进:你无法知道该修复视觉编码器,还是该调整语言生成器。
针对这一痛点,香港科技大学、清华大学、浙江大学、美团和滑铁卢大学的联合研究团队(Wang et al., 2026)在ICML 2026 Spotlight论文《Bad Seeing or Bad Thinking? Rewarding Perception for Vision-Language Reasoning》中,提出了一种全新的强化学习框架MoCA(Modality-Aware Credit Assignment)。核心创新在于:他们不再把VLM的训练视为一个整体端到端任务,而是将生成过程显式分解为“感知”和“推理”两个可监督的模块,并分别为它们提供独立的奖励信号。这意味着,模型能准确地知道:失败是因为“看错了”,还是因为“想错了”。
这篇论文值得每一位从事多模态AI、强化学习或智能系统设计的读者精读,因为它从根本上的“信用分配”机制出发,赋予信号可解释性,使训练不再盲目。接下来,我们将逐节解剖这篇论文。

摘要
当前视觉语言模型(VLM)追求感知与推理的深度协同,以在更复杂的多模态任务上取得突破。现有方法主要分为两大类:一类通过架构设计隐式融合视觉和语言特征,依赖于静态文本推理;另一类采用agent框架实现“主动感知”,通过多轮函数调用在图像与推理之间循环。然而,这些方法存在显著局限性:架构方案无法有效引导感知机制,agent方案则带来了高昂的计算和工程负担。更严重的是,即便投入大量资源,感知和推理之间仍经常出现“跷跷板效应”——一方的进步以另一方退步为代价。
本文认为,该问题的根本瓶颈在于模态信用分配模糊。当VLM在某个任务上失败时,我们无法区分是由于感知错误(“看错了”)还是推理错误(“想错了”)导致的。为了解决这一模糊性,本文提出一个强化学习框架,通过显式分解生成为感知和推理步骤并直接对感知保真度进行奖励,以提升两者协同。具体而言,该框架引入了Perception Verification(PV):借助一个盲推理代理(仅依赖感知块输出的文本描述,而不看到图像)来独立评估感知的质量;以及Structured Verbal Verification(SVV):用结构化算法执行替代高方差的大语言模型评判,使得对自由答案的可靠奖励成为可能。
这些技术被集成为 Modality-Aware Credit Assignment(MoCA) 机制。该机制能够将奖励信号路由到具体的错误源——感知或推理,从而使单一的VLM在广泛的任务谱上同时获得性能提升。本文被ICML 2026接收为Spotlight。
引言:论文要解决什么问题
论文从“如何实现真正的感知-推理协同”这一问题出发,指出了当前VLM实践中的一个核心盲区。当模型在视觉问答或图像推理任务中失败时,工程师很难判断错误根源。例如,一个VLM被问到“桌上的物体是圆形的吗?”它回答“不是”。这个回答的错误是由它未能正确识别物体(感知错误)引起的,还是由它未能有效利用识别结果进行推理(逻辑错误)引起的?在传统的联合训练范式中,整个模型只得到一个终极的奖惩信号,无法区分错误的模态来源。
这种模态信用分配模糊在视觉语言推理中是独特且极具挑战性的,因为VLM的感知过程要么隐藏在潜状态激活中,要么在最终文本输出中与推理成分纠缠不清。现有方法要么仅依赖静态推理(如Qwen-VL),要么引入外部视觉操作的agent框架(如通过多轮函数调用重新获取图像细节),但后者的复杂度极高,且常常伴随着“跷跷板效应”,即感知提升以推理退步为代价。
因此,本文的核心研究问题是:我们能否通过外部化感知并直接对感知进行奖励,来改善多模态推理? 答案是可以。作者指出,如果将VLM的感知过程“外部化”——即显式地将感知步骤输出为可理解的文本块(例如放在<recognition>标签内),然后将这些文本块与推理步骤(例如<think>标签内)分开——那么原来“黑箱”的感知模块就变成了一个透明的序列,使我们可以:1)分辨错误具体发生在哪个部分——是<recognition>中的描述错了,还是<think>中的推理错了;2)分别对感知和推理进行有区别的监督。由此,原本棘手的联合监督问题被拆解为两个可解决的子问题:感知验证和结果验证。
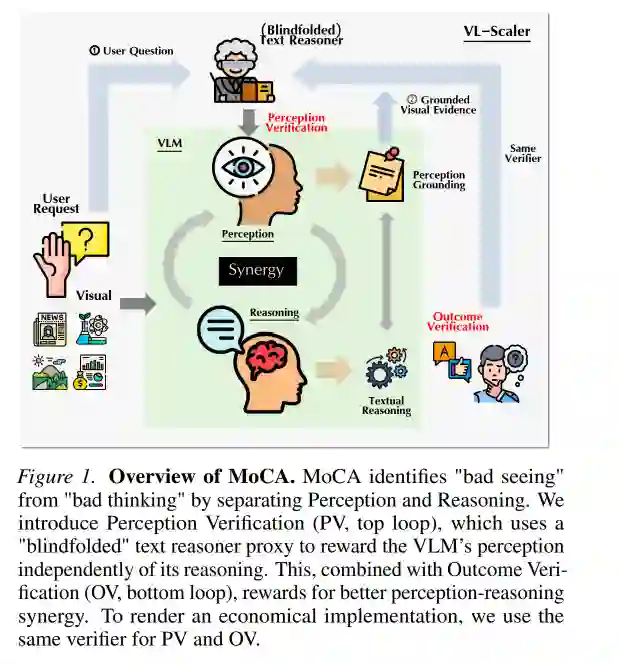
方法:核心思路与技术路线
本章是论文的核心。方法分为三大模块,最终整合成MoCA机制。
1. 显式分解生成过程
作者首先利用VLM本身的指令跟随能力,强制要求模型在生成过程中输出结构化的文本。具体来说,生成过程被显式分解为交替的“感知块”和“推理块”。感知块用<recognition>标签包围,用于隔离视觉证据;推理块用<think>标签包围,用于呈现逻辑推导过程。这种简单的序列化设计,将一个模糊的生成过程转化为可逐步追踪的透明序列,是解决信用分配模糊的第一步。举例而言,对于一个“图中有什么颜色”的问题,模型的输出可以是:<recognition>图像中有一张红色桌子和一个蓝色杯子</recognition><think>因此,图像中主要颜色是红色和蓝色。</think>。
2. Perception Verification (PV) —— 盲推理代理验证感知
解耦完成后,第二个子问题出现了:如何监督中间的感知块(即模型输出的视觉描述片段)?现实中,我们没有实际的“图像描述”的真值。为此,作者提出了Perception Verification via Proxy——一个巧妙的代理方法。 其核心理念是:在显式视觉语言推理中,视觉细节词汇作为逻辑推导的前提存在。因此,感知的充分性可以通过推理的可行性来度量。作者实现了一个“盲推理测试”:他们将VLM在感知块中输出的视觉描述单独提取出来,不携带图像,然后输入给一个强大的、纯文本的推理代理(例如GPT-4级别的文本LLM)。这一代理 “盲”——即无法看到原始图像。如果这个纯文本代理能够仅凭VLM的描述正确回答用户的问题,就说明感知块成功捕捉到了任务所需的充分统计信息。这相当于VLM的视觉感知通过了“盲检验”。反过来,如果代理无法正确回答,说明感知信息不足或不准确,就应该惩罚感知模块。这种设计确保VLM不是去生成宽泛的文本描述,而是精确提取出支撑下游推理所需的最相关的视觉事实。 关键点:PV奖励的不是通用图片描述能力,而是任务相关的感知保真度,因此可以引导感知模块去关注对于推理最有用的视觉线索。
3. Structured Verbal Verification (SVV) —— 结构化算法替代LLM评判
另一个子问题是:如何可靠地对自由形式的最终答案(即推理块的输出)进行奖励?传统的做法,要么用正则表达式对答案进行字符串匹配(脆弱且无法适应自由答案),要么调用大型语言模型(LLM)作为Judge(高方差、计算成本高、不可解释)。为了扩展训练至广泛的自由形式VL任务,作者提出了Structured Verbal Verification(SVV)。 SVV的核心是:不依赖LLM的“黑箱”评判,而是将答案验证转化为一个结构化算法执行过程。具体来说,他们提取出推理块中的结构化元素(例如符号表达式、逻辑断言或引用条件),然后执行这些元素(如计算、逻辑判断或引用验证)。例如,如果推理块中出现了“如果A成立则B成立”的结构,SVV可以直接检查A与图像事实是否一致,并逻辑推导B。这样一来,答案的评估不再是不可解释的分数,而是基于定义明确规则的二值信号。这种做法不仅降低了评判方差和计算成本,还使得奖励信号更加稳定和可解释,适合强化学习训练。
4. Modality-Aware Credit Assignment (MoCA) —— 集成路由机制
最后,PV和SVV被集成到Modality-Aware Credit Assignment(MoCA) 机制中。MoCA本质上是一个奖励路由模块,它根据一个任务失败的来源(感知错误or推理错误),将奖励信号分配到正确的子模块上。 具体工作流程如下:在每一步训练中,VLM先生成序列化的感知+推理输出。首先,SVV对最终答案进行评估;如果正确答案分类正确,则奖励全局信号。但如果答案错误,MoCA不会直接惩罚所有参数,而是触发PV评估感知块的质量。如果PV验证表明感知块在“盲推理测试”中已经失败(即文本代理无法从感知描述中正确回答),那么MoCA将错误诊断为感知错误,并将负奖励路由到感知相关参数(即视觉编码或文本感知层的权重);反之,如果感知描述足够好但仍未得到正确答案,则错误诊断为推理错误,奖励路由到推理相关参数(即语言模型层)。这种精确的信用分配避免了对模型的“一刀切”惩罚,从而实现了感知和推理的同时优化。 该方法在形式上与传统的强化学习中的“信用分配”有本质不同:它不需要针对VLM隐藏状态进行复杂的梯度回溯,而是通过显式的、可监督的文本中间步骤,实现了模态级别的奖励路由。
配图:方法结构
实验:设置、指标与结果
原文未明确说明 具体使用的评测基准、数据集和指标。论文摘要中声称“使单个VLM在广泛任务上同时实现性能提升”,但未在提供的正文节选或材料中给出具体的数值结果或对比表格。不过,从论文的接收情况和Spotlight级别来看,其方法应该在常见的VLM评测基准(如Visual Question Answering系列、多模态推理基准Visual Commonsense Reasoning等)上通过消融实验验证了MoCA机制的有效性、PV的独立收益以及SVV的替换优势。由于论文正文节选止于引言和方法部分,实验的详细设置和复杂结果留待全文解析。该领域的读者在阅读完整论文时可期待详细的性能对比和模块贡献度分析。 消融/分析:原文未明确说明,但可以推测作者会对比:1)MoCA vs 联合训练(所有参数共享同一个奖励);2)是否去掉PV(即仅用SVV);3)是否用LLM Judge替代SVV等。这些在完整论文中理应存在。
结论:贡献、局限与启发
本文提出了Modality-Aware Credit Assignment (MoCA) 框架,为视觉语言模型的训练开辟了一个新的视角:通过将感知和推理过程显式分离并分别提供独立奖励,解决了在VLM中长期存在的模态信用分配模糊问题。其主要贡献包括:首次提出了通过“盲推理代理”(Perception Verification)直接奖励感知保真度的方法;提出了Structured Verbal Verification,以结构化的算法执行替代高方差LLM评判,实现更稳定的自由答案验证;通过MoCA机制使单一的VLM能够同时改进其视觉感知和文本推理能力,回避了“跷跷板效应”。 局限性:原文未明确说明,但可以推测:该方法依赖于强文本代理的质量,且要求VLM具备良好的指令跟随能力才能完成结构化输出;对实时性要求苛刻(S)任务,PV的二次调用可能引入额外延迟;对于感知与推理高度耦合的任务(如风格迁移),严格分离可能不适用。 启发:本文的工作实际上为多模态强化学习提供了一个“模块化奖励”范式——不依赖端到端黑箱信号,而是通过可解释的中间步骤实现对复杂能力的拆解和独立优化。这一思路不仅适用于视觉语言推理,也可能推广至听觉-语言、视频-语言等更多模态组合,更广义来说,为任何“感知+认知”耦合的系统性训练提供了方法学范例。从AI系统设计的角度,它表达了未来AI发展的一个重要方向:不再是一个大模型解决所有问题,而是让AI学会在内部模块间进行可归因的信用分配,赋予自身“反思”能力。