GLANCE:用视觉-语言好奇心驱动VLM智能体主动探索
论文标题:What You Think is What You See: Driving Exploration in VLM Agents via Visual-Linguistic Curiosity
作者:Haoxi Li, Qinglin Hou, Jianfei Ma, Jinxiang Lai, Tao Han, Sikai Bai, Jingcai Guo, Jie Zhang, Song Guo
录用信息:ICML 2026 Spotlight
论文链接:https://arxiv.org/abs/2605.03782
一、引言
VLM(视觉-语言模型)智能体正越来越多地通过显式的CoT(思维链)推理将世界建模能力内化到策略中,使其能够在行动前进行心理模拟。然而,仅靠被动推理已访问过的状态,在稀疏奖励任务中远远不够——智能体缺乏主动揭示"已知的未知"的认识驱动力。
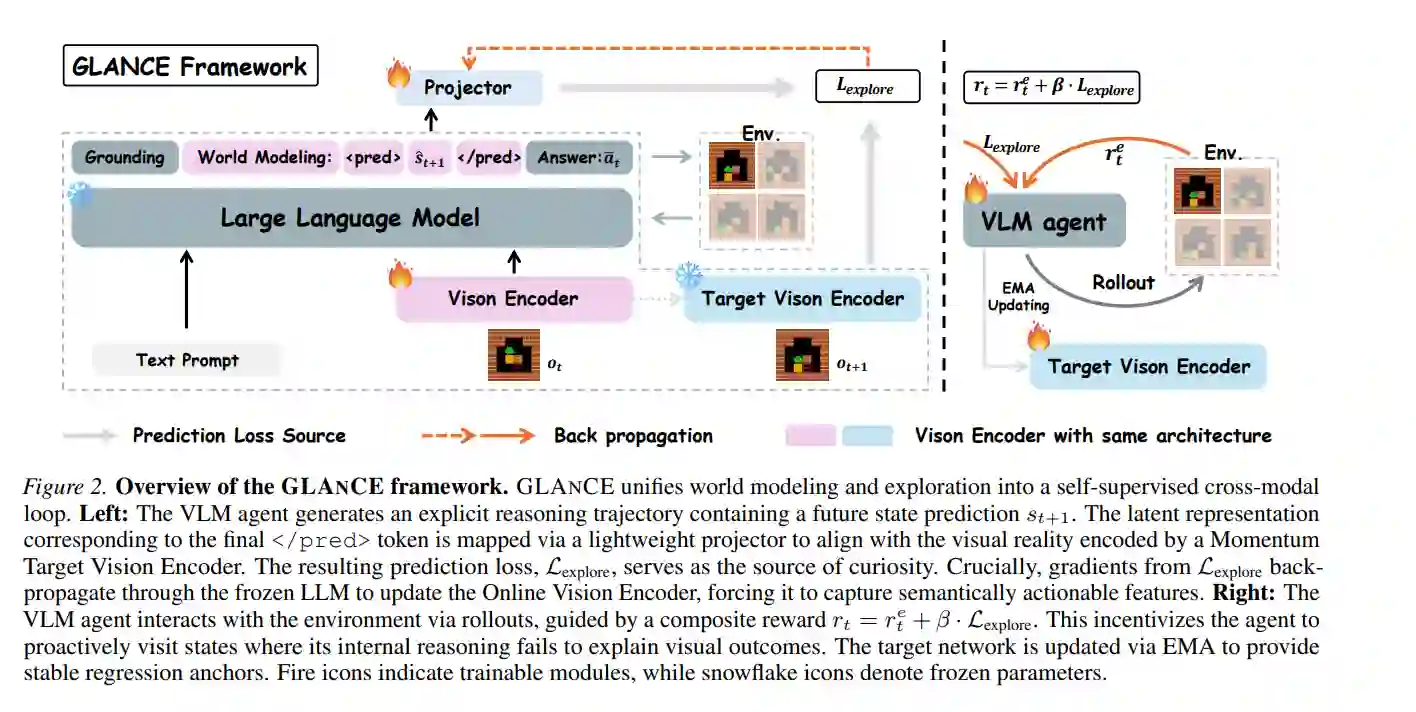
本文提出GLANCE(Grounding Linguistic Alignment for Curiosity Exploration),一个统一框架,通过将智能体的语言世界模型与视觉现实对齐,将推理与探索无缝桥接。
二、核心思想:你之所想即你之所见
GLANCE的核心洞察是:VLM智能体"想"什么,应该能预测它"看"到什么。
具体来说,GLANCE将智能体语言预测的潜在表示投影到经动量更新的目标网络的视觉表示空间中,利用两者之间的差异作为:
- 世界建模目标——塑造视觉编码器以捕捉语义可操作的特征
- 好奇心驱动的内在奖励——引导智能体主动探索其内部模型不确定的区域
这使探索从随机搜索转变为主动证伪——智能体会主动访问那些当前推理无法解释视觉结果的状态。
三、方法架构
GLANCE包含两个并行的流:
Online VLM智能体
- 视觉编码器
f_v+ LLM主干Λ_ℓ - 生成包含世界建模的推理轨迹:
<Obs>s_t</Obs><Res>z_t</Res><Pred>s_{t+1}</Pred><Ans>a_t</Ans> - 轻量级投影器
g_ψ将语言假设映射到视觉特征空间
动量目标网络
- 结构上与Online编码器相同
- 参数通过EMA更新:
φ ← α·φ + (1-α)·v - 提供稳定的回归目标,防止表示坍塌
跨模态预测目标
预测损失定义为语言预测与视觉现实之间的MSE:
ℒ_explore = || ŷ_{t+1}/||ŷ_{t+1}|| - sg(y_{t+1}/||y_{t+1}||) ||²
梯度不更新LLM,但会反向传播更新视觉编码器和投影器,迫使视觉编码器学习与逻辑推理语义一致的特征。
好奇心驱动的内在奖励
r_t^i = β · ℒ_explore
r_t = r_t^e + r_t^i
四、关键挑战与解决方案:好奇心枯竭(Curiosity Drain)
问题:预训练LLM主干已具备丰富语义,轻量投影器会快速过拟合到浅层视觉特征,导致内在奖励早期消失,智能体误以为已掌握环境而停止探索。
解决方案——课程式探索(Curriculum Exploration):
- 周期性地重新初始化投影器权重
- 同时保留不断演化的视觉编码器
- 迫使智能体用增强后的视觉感知重新审视熟悉状态
- 发现之前被投影器过拟合掩盖的细微差异
这使探索变为自定进度的课程:随着视觉编码器捕捉到日益复杂的语义,重新焕活的投影器不断揭示新的"已知未知"层。
五、实验评估
GLANCE在以下五类智能体任务上进行了评估:
| 任务类型 | 环境 | 评估指标 |
|---|---|---|
| 网格谜题 | Sokoban变体 | 成功率 |
| 3D导航 | KABOOM、Habitat | 成功率 |
| 物体操控 | LIBERO (10任务) | 成功率 |
| 几何重建 | SVG生成 | 感知相似度 (DINO+DreamSim) |
主要发现
- 全面超越现有方法:在几乎所有任务上显著优于Vagen和VLM-RL等利用型方法
- 无外在奖励也能学习:仅靠好奇心驱动的内在奖励即可学习有效的探索策略
- 课程式探索至关重要:周期性重新初始化投影器是维持长期认识驱动的关键
- 轻量级架构:VLM智能体同时作为世界模型和策略,无需人类演示
六、意义与展望
GLANCE展示了将"思考"与"看见"协同对齐,是构建自主、好奇且物理可信的智能体的基本前提。其核心贡献在于:
- 首次将VLM智能体的语言推理与视觉感知通过好奇心学习统一
- 提出课程式探索解决了好奇心枯竭的实践挑战
- 在无需人类演示的稀疏奖励场景下取得了显著性能提升
未来的发展方向包括扩展到更复杂的连续控制任务,以及探讨如何在多智能体系统中利用这种跨模态好奇心。