
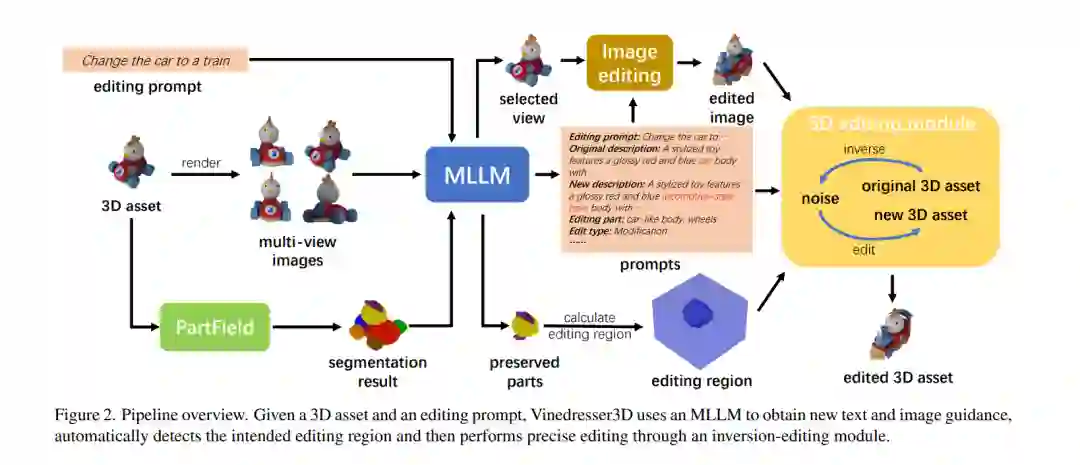
文本引导的 3D 编辑旨在通过自然语言指令对现有的 3D 资产进行修改。现有方法在协同理解复杂提示词、自动化 3D 编辑定位以及保持非编辑区域内容完整性方面仍面临巨大挑战。本文提出 Vinedresser3D,这是一种用于高质量文本引导 3D 编辑的智能体化框架(Agentic Framework),该框架直接在原生 3D 生成模型的潜空间(Latent Space)中执行操作。 针对给定的 3D 资产与编辑提示词,Vinedresser3D 利用多模态大语言模型(MLLM)推断原资产的详尽描述,精准识别编辑区域及类型(增补、修改或删除),并生成解耦后的结构级与外观级文本引导。随后,该智能体自主选择具备丰富信息的视角,并调用图像编辑模型以获取视觉引导。最后,通过一种集成交错采样模块(Interleaved Sampling Module)的基于逆向算子的修正流(Rectified-flow)内补绘制管线,在 3D 潜空间中完成编辑任务;该机制在确保 3D 一致性并保留未编辑区域的同时,实现了严苛的提示词对齐。 针对多种 3D 编辑场景的实验结果表明,Vinedresser3D 在客观评估指标与主观人类偏好研究中均优于现有基准方法,并实现了精确、连贯且**免掩码(Mask-free)**的 3D 编辑。
成为VIP会员查看完整内容
相关内容
最新内容
相关VIP内容
相关资讯