
导读
用户模拟(User Simulation)是计算机科学中的长期研究课题,其核心目标是构造能够替代真实用户的行为代理,从而支持系统评测、交互优化、数据增强等多种应用。近年来,大语言模型(LLM)凭借其强大的语言生成能力,使合成用户对话的保真度达到了前所未有的高度,推动了对话用户模拟子领域的迅速发展。然而,相关文献分散在对话系统、推荐系统、社交模拟等多个方向,缺少统一组织与系统分析的专门综述。由Adobe Research和南加州大学等多机构合作的团队(Bo Ni等30位作者)正是针对这一空白,撰写了《A Survey on LLM-based Conversational User Simulation》。
该综述的创新之处在于提出了一个涵盖用户粒度(user granularity)和模拟目标(simulation objectives)的新分类法,并围绕三个核心问题组织全文:(1)模拟谁?——用户身份与群体;(2)模拟什么?——用户的属性、行为、偏好等目标;(3)如何模拟?——技术路线与生成策略。通过这一统一框架,作者系统梳理了近年来的代表性方法、评估协议与常用数据集,并指出了关键开放挑战。 对于关注对话系统、用户建模、LLM应用的研究者和实践者来说,这篇综述提供了清晰的领域全景,有助于快速了解当前主流方法、技术演变以及未解决的问题。文章的信息密度高,分类严谨,附录中包含了与相关综述的对比分析,非常适合作为入门或系统化的参考资料。
论文基本信息

原文链接 http://arxiv.org/abs/2604.24977v1
摘要
用户模拟在计算机科学中长期以来扮演着重要角色,其潜力支持着广泛的应用。语言作为人类交流的主要媒介,构成了社会互动和行为的基础。因此,模拟对话行为已成为一个关键研究领域。大语言模型(LLM)的最新进展通过实现高保真的合成用户对话生成,极大地催化了这一领域的进步。本文综述了基于LLM的对话用户模拟的最新进展。我们提出了一个涵盖用户粒度和模拟目标的新分类法。此外,我们系统分析了核心技术和评估方法。我们旨在让研究社区了解对话用户模拟的最新进展,并通过识别开放挑战和将现有工作组织在统一框架下,进一步促进未来研究。
引言:论文要解决什么问题
尽管用户模拟研究已有数十年历史,从经典的Bradley-Terry-Luce模型到基于统计的协同过滤、矩阵分解,再到近年基于LLM的模拟方法,大量工作聚焦于从数据中学习用户偏好与行为。然而,这些方法大多针对特定应用领域(如推荐系统、搜索),且往往需要大量用户数据进行训练。LLM的出现显著改变了这一局面:它可以通过提示工程在零样本或少样本条件下生成丰富的、情境化的用户交互,从而大幅降低了模拟成本,并拓宽了模拟任务的通用性。 然而,现实用户交互的“对话性”是一个核心维度——语言作为人类交流的主要媒介,在模拟用户时必须显式建模多轮、互动性的对话过程。已有工作如USimAgent、BASES等在搜索、推荐等场景中取得了进展,证明了对话式用户模拟能够提升系统与用户需求的对齐。但遗憾的是,该领域缺少一个专门组织并分析对话用户模拟子领域的综述。现有综述往往涵盖更广的用户模拟范围(如信息访问系统评测),或聚焦于特定技术(如LLM代理),但未系统审视“对话式”用户模拟的独特问题。 本文旨在填补这一空白。作者通过提出一个包含三个基本问题的统一分类框架——(1)模拟谁?(2)模拟什么?(3)如何模拟?——来组织现有文献。这一框架帮助读者理解不同工作之间的内在联系和差异。与已有综述相比,本文专注于对话用户模拟,并在附录A.3中详细讨论了自己与相关综述的定位区别。
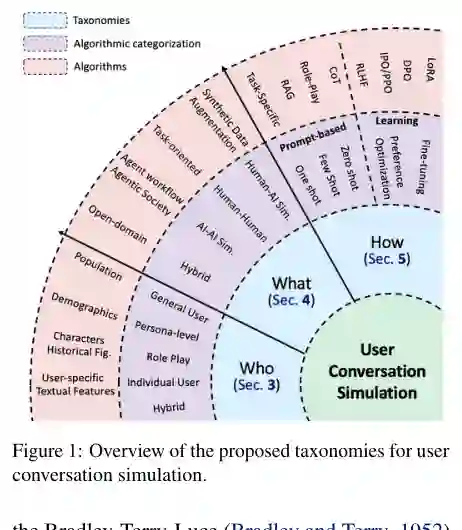
方法:核心思路与技术路线
本文作为综述论文,其“方法”部分实质上是综述的框架与分类体系。作者围绕三个基本问题构建了完整的分析路线:
1. 模拟谁?(Who is being simulated?)
该维度关注模拟对象,即用户身份与群体。作者将其分为两个子层次:
- 用户类型(User Granularity):包括个人用户模拟(如基于用户画像、人格特征生成特定个体的行为)和群体用户模拟(如模拟用户群组的互动,或代表性人口统计群体的对话模式)。例如,一些工作通过构建带有特定人格(如外向型、健谈型)的LLM代理来模拟个人用户;另一些工作则模拟多用户之间的对话,用于评测系统在多人场景下的表现。
- 模拟目标(Simulation Objectives):包括生成式目标(如生成用户与系统的交互对话)和评价式目标(如让LLM扮演用户来评估系统回复的符合度)。LLM-as-a-judge方法即属于后者,让LLM模拟用户对推荐或对话系统的反馈。
Figure 2: Overview of the proposed taxonomy for who is being simulated, i.e., the target of simulation. 来源:原论文 PDF 第 3 页。
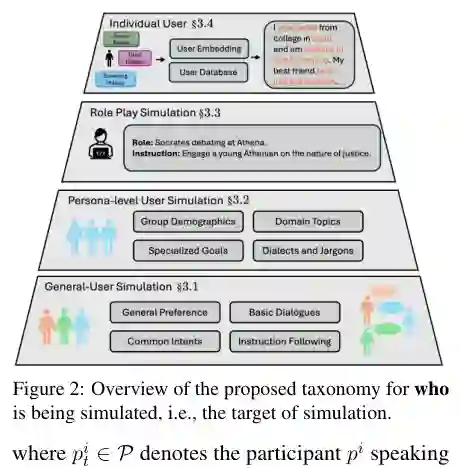 Figure 2: Overview of the proposed taxonomy for who is being simulated, i.e., the target of simulation. 来源:原论文 PDF 第 3 页。
Figure 2: Overview of the proposed taxonomy for who is being simulated, i.e., the target of simulation. 来源:原论文 PDF 第 3 页。2. 模拟什么?(What is being simulated?)
该维度关注模拟的内容层面,即生成用户对话所需刻画的属性或行为。作者归纳了以下几类核心内容:
- 用户属性(User Attributes):包括人口统计学特征(年龄、性别、教育背景)、人格特质、领域知识水平、兴趣偏好等。这些属性通常作为Prompt中的特征描述,引导LLM生成符合特定用户画像的对话。
- 用户行为(User Behaviors):指具体对话中的行为模式,如提问、回答、确认、反驳、情绪表达等。部分工作模拟用户在检索或推荐场景中的点击、查询、浏览等行为,并扩展到对话形式。
- 用户偏好(User Preferences):处理用户偏好时,需要模拟其对不同选项的排行、选择或打分。例如,模拟用户在推荐对话中对备选商品的偏好反馈,或者模拟用户对系统建议的满意度评分。
- 用户目标与知识状态(User Goals & Knowledge State):许多任务导向型对话系统需要模拟用户的知识状态(已知道什么?未知什么?)和任务目标(订酒店?查航班?)。MultiWOZ等数据集常被用于构建此类模拟器。
3. 如何模拟?(How is the conversation simulated?)
该维度关注技术手段,即如何生成对话的流程与内容。作者将其分为两大技术路线:
- 数据驱动方法(Data-driven Methods):基于真实对话数据(如MultiWOZ、Taskmaster等)训练用户的对话策略模型。早期方法使用RNN、Transformer等架构;近年来,LLM通过微调(fine-tuning)或上下文学习(in-context learning)实现高保真模拟。典型做法包括:使用预训练LLM,在少量领域数据上微调,使其学会用户角色;或者直接使用零样本Prompt,让LLM根据用户画像描述生成对话。
- 提示工程方法(Prompt Engineering Methods):不修改模型参数,而是通过精心设计的提示模板来控制LLM的行为。这些提示通常包含用户角色设定(persona)、对话历史、当前轮次信息、输出格式约束等。这类方法灵活、成本低,但与数据驱动方法相比,可能缺乏源数据分布的一致性。一些工作探索了多轮提示、思维链引导、角色扮演提示等技术来提升模拟的连贯性和真实性。
此外,作者还讨论了混合方法,即结合数据驱动和提示工程的优势,例如先用数据驱动方法训练一个基础模拟器,再通过提示注入特定知识或约束。 整体上,这三个问题形成一个三维坐标轴,覆盖了从“谁在模拟”到“模拟什么”再到“怎么模拟”的完整链条。这种分类法既保持了通用性(覆盖个人、群体、不同目标),又提供了清晰的定位方式。
配图:方法结构
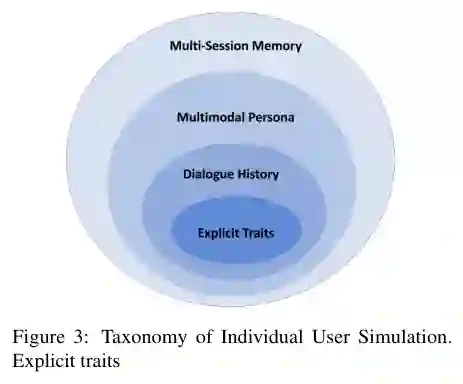
实验:设置、指标与结果
原文未明确说明。本文为综述论文,没有进行新的实验。然而,作者在综述中系统分析了现有工作的评估方法,主要包括以下几个方面:
- 评估协议 现有工作分为自动评估和人工评估两类。自动评估常使用对话完成率、语义相似度(如ROUGE、BLEU)、用户目标达成率、F1等指标;人工评估则侧重真实性、一致性、多样性、自然度等维度。部分工作还采用用户满意度问卷调查或众包人工评分。
- 常用数据集 综述列举了多轮对话数据集,如MultiWOZ(任务导向型)、Taskmaster(开放域)、PersonaChat(人格化对话)等。这些数据集被广泛用于训练和评估对话用户模拟器。此外,还有一些针对特定领域(如推荐、搜索)的定制数据集和工具,如USimCRS、BASES等。
- 评估挑战 作者指出,目前缺乏统一的基准测试来公平比较不同模拟方法。跨方法的完整考核研究超出了本文范围。
尽管没有新的实验数据,该综述通过对现有评估工作的整理,提供了指导性建议:建议研究者结合自动和人工指标,并注意基线方法的选择、数据隐私与伦理审查。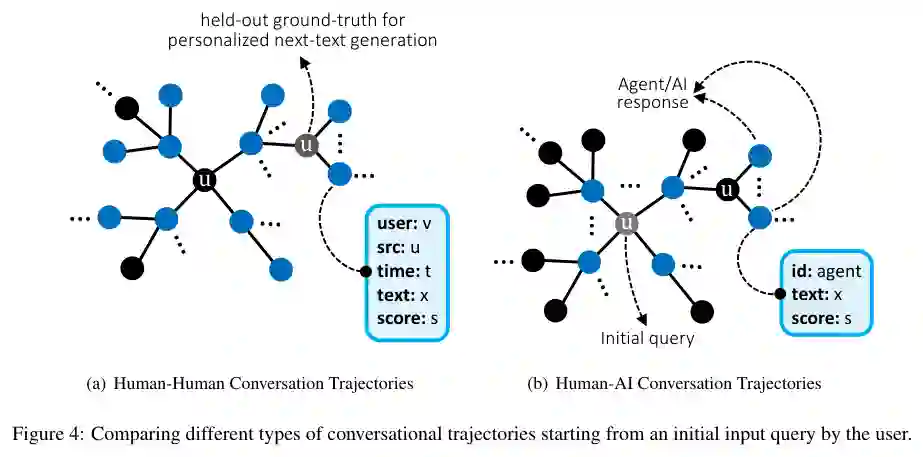
结论:贡献、局限与启发
贡献
本文通过Who、What、How的统一框架回顾了基于LLM的对话用户模拟的代表性文献,主要贡献包括:
- 提出了新的分类法:首次同时考虑用户粒度(个人vs群体)和模拟目标(生成vs评价),有助于定位不同工作的侧重点。
- 提供了现有方法的广泛概述:讨论了每种方法的优势和局限,并按下游应用(如对话系统评估、推荐系统优化、社交模拟等)进行了分类。
- 检查了评估协议和常用数据集:汇总了主流评估手段与标准数据集,为方法选择提供了参考。
- 指出了关键开放挑战和未来研究方向:包括如何提升模拟的一致性、多样性、鲁棒性和可信度,以及如何应对伦理问题。
局限
作者坦诚指出了本文的局限:
- 分类法的覆盖性 为了平衡通用性和清晰度,某些混合或特定领域的方法可能无法完美契合所提出的类别。例如,既模拟个人又模拟群体的多代理方法可能难以被单一维度完全界定。
- 缺乏完整基准测试 尽管总结了数据集和评估,但跨方法的全面考核研究超出了本文范围。读者在比较不同方法时需谨慎。
- 时效性 该领域发展迅速,新方法不断涌现,综述基于截至提交时的文献,可能未涵盖所有最新工作。
启发与未来方向
基于综述分析,作者提出了若干值得关注的开放挑战:
- 一致性 如何确保模拟用户在整个对话过程中行为一致(如人格、偏好不突变)?
- 多样性 如何生成多样化的用户行为,避免陷入同质化模式?
- 鲁棒性 模拟器在面对系统错误或对话波动时能否保持合理表现?
- 伦理考量 模拟公开人物可能引发虚假信息;构建人口统计人群画像可能强化刻板印象;合成数据的溯源与披露问题需要关注。建议研究者在文档中明确交代数据来源、代表性和隐私合规。
- 可解释性 如何让模拟行为可被解释和审计,增强可信度。
