
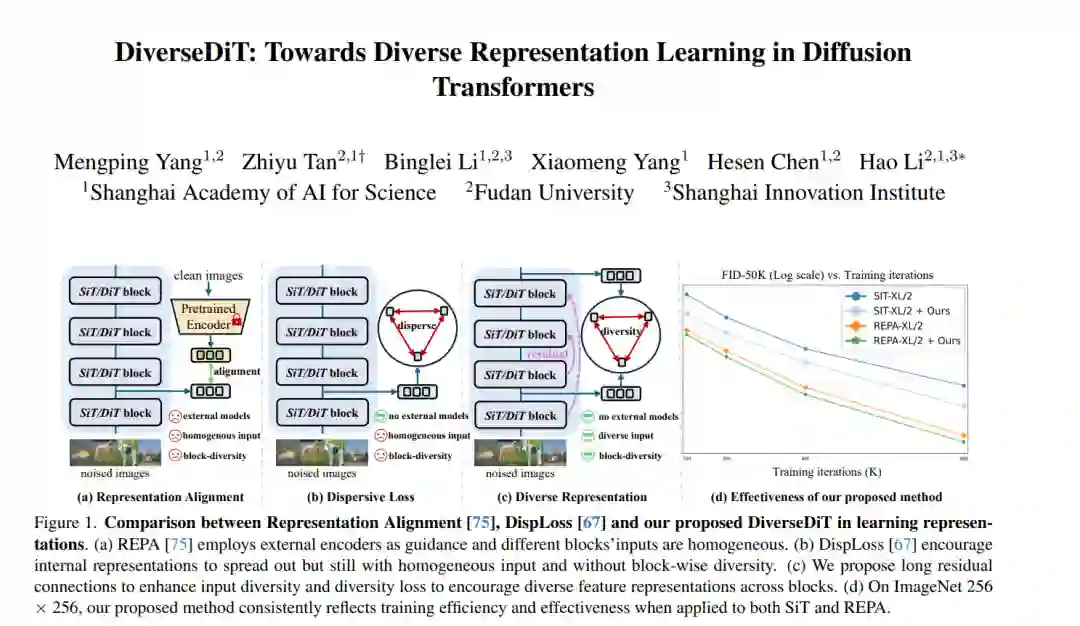
扩散 Transformer (DiTs) 近期凭借其卓越的可扩展性 (scalability),在视觉合成领域引发了变革性突破。为了增强 DiTs 捕获深层内部表征的能力,诸如 REPA 等近期的研究引入了外部预训练编码器以进行表示对齐 (representation alignment)。然而,支配 DiTs 内部表示学习的底层机制仍未得到充分探索。为此,本文首先对 DiTs 的表示动力学 (representation dynamics) 进行了系统性研究。通过分析不同设置下内部表征的演变及其影响,我们发现跨块的表示多样性 (representation diversity) 是实现高效学习的核心要素。基于这一关键洞察,我们提出了 DiverseDiT —— 一个旨在显式提升表示多样性的创新框架。DiverseDiT 通过引入长残差连接 (long residual connections) 来丰富跨块的输入表示多样性,并利用表示多样性损失函数促使各模块学习差异化特征。在 ImageNet 256×256 及 512×512 规模上的大量实验表明,DiverseDiT 在不同规模的骨干网络上均实现了稳健的性能提升与收敛加速,即便在极具挑战性的单步生成 (one-step generation) 场景下亦表现出色。此外,我们证明了 DiverseDiT 与现有的表示学习技术具有良好的互补性,能够进一步提升模型性能。本研究为理解 DiTs 的表示学习动力学提供了重要见解,并为增强模型效能提供了一种切实可行的方案。项目代码已开源至:https://github.com/kobeshegu/DiverseDiT。
成为VIP会员查看完整内容
相关内容

最新内容
相关VIP内容
相关资讯