
综述 | 从问答到任务完成:Agent系统与Harness设计
论文标题:From Question Answering to Task Completion: A Survey on Agent System and Harness Design 作者:Jianyuan Guo、Zhiwei Hao、Chengcheng Wang、Cheng Fan、Tingzhang Luo、Hongguang Li、Ying Gao、Hefei Mei、Jiankun Peng、Rongjian Xu、Minjing Dong、Han Wu、Mengyu Zheng、Kai Han、Shiqi Wang、Chang Xu、Yunhe Wang 论文链接:https://arxiv.org/abs/2606.20683 项目合集:https://github.com/ggjy/Awesome-Agent-Engineering

图1:论文首页摘要。本文把 LLM Agent 的核心问题从“模型是否足够强”推进到“模型与执行 harness 如何耦合”。
导读
这篇综述关注一个非常现实的问题:为什么同一个基础模型,放进不同 Agent 系统后,任务完成率、稳定性、成本和安全性会差别很大?作者给出的答案是,现代 LLM Agent 不能只被理解为“模型加工具”,而应被理解为“基础模型 + 执行 harness”的耦合系统。 所谓 harness,可以理解为围绕模型运行的一整套执行基础设施:它决定模型看到什么、上下文如何组织、控制循环如何推进、动作如何被执行、状态如何保存、结果如何验证和治理。Agent 的成功不再只是参数规模、训练数据或推理能力的函数,而是模型能力、运行时架构、任务结构和评测设计共同作用的结果。 论文按照 Agent 工程演化脉络展开:从 Prompt Engineering,到 Workflows and Context Engineering,再到 Harness Engineering,最后走向 Agent-Native Training and Co-Evolution。它的价值不在于再给 Agent 做一个组件清单,而是解释工程瓶颈如何从“提示词怎么写”迁移到“运行时如何稳定完成长程任务”。
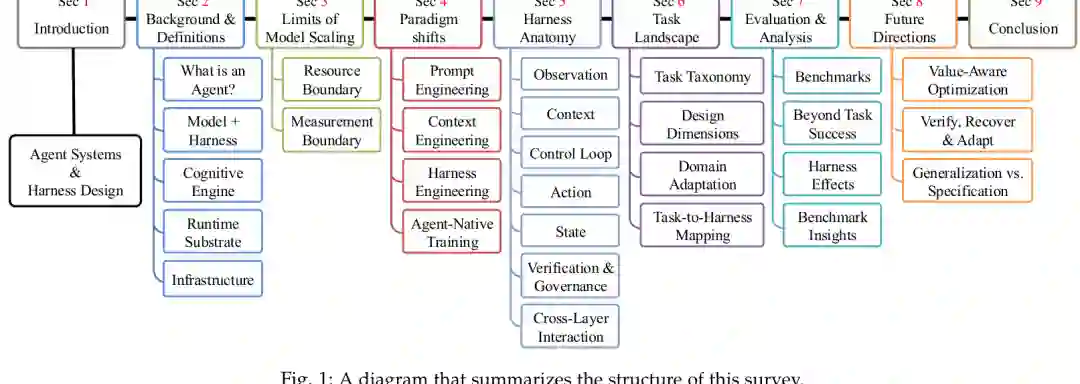
图2:综述结构图。论文从定义、模型扩展边界、工程范式、harness 解剖、任务图谱、评测分析和未来方向逐层展开。
1. Introduction | 引言
LLM-based agents 标志着从被动问答到主动任务完成的转变。早期聊天界面主要优化单轮回答质量,而现代 Agent 需要感知环境、调用工具、更新状态、跨多步执行动作,并在失败时验证和恢复。 这种转变让传统模型中心视角变得不够。对问答任务来说,更强模型、更大数据、更好对齐通常能带来可预期收益;但对长程任务完成来说,Agent 必须反复观察、构造上下文、选择动作、保存状态、处理反馈和恢复错误。此时性能瓶颈可能不在基础模型本身,而在执行环境和 harness 设计。 作者提出,Agent 质量包括成功率、效率、安全性和泛化性,它们来自模型能力、运行时基础设施、任务结构和评测设计之间的交互。本文因此采用 model-harness lens,分析 Agent 系统如何从 prompt 技巧演化到可组合、可学习、可治理的运行时系统。
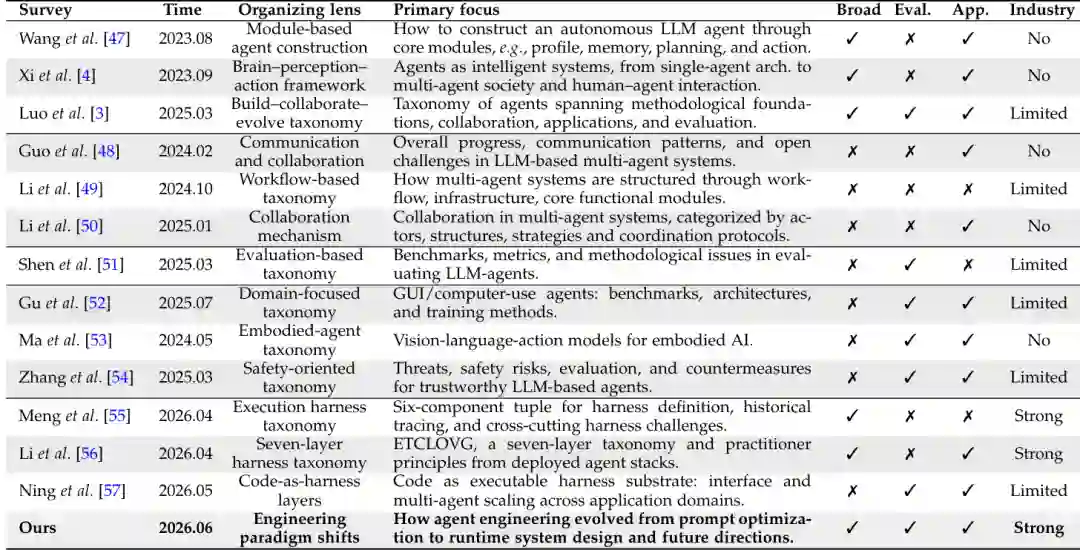
图3:与已有 Agent 综述的对比。本文强调工程范式迁移、harness 中心视角,以及学术证据与工业实践结合。
2. Background and Definitions | 背景与定义
什么是 Agent
论文区分了 Agent 的功能视角和实现视角。功能上,Agent 是一个围绕目标组织五类操作的闭环系统:感知、状态维护、推理与决策、行动、反馈适应。目标和环境决定具体任务,但闭环性质决定它不同于一次性推理脚本。 实现上,LLM Agent 不只是基础模型。作者将其写成模型层与 execution harness 的组合。模型提供语言理解、推理、规划和动作提议;harness 则提供可观测环境、上下文组装、动作执行、状态持久化、失败检测与修复。

图4:Agent 功能闭环。Agent 通过感知、状态、推理决策、行动和反馈适应与外部环境交互。
Harness 作为运行时基座
论文把 harness 定义为围绕模型的运行时基础设施,而不只是单个工具、记忆模块或 prompt 模板。它决定哪些环境信号进入模型,如何构建上下文,如何推进控制循环,哪些动作可执行,状态如何存储,以及如何验证、约束和恢复执行。 这一视角解释了为什么在基础模型不变时,改造 SWE-agent 的 agent-computer interface、添加 checkpoint、设计沙箱和验证循环,仍能显著改变性能。模型能力要转化为可靠任务完成,必须经过 harness 的组织、限制和放大。
3. The Limits of Model-Centric Scaling | 模型中心扩展的边界
论文指出,模型扩展仍然重要,但不再足以解释 Agent 性能。更强模型可以提升推理、代码生成和多模态理解,但长程任务是轨迹级问题:每一步观察、上下文选择、动作执行、状态保存和错误恢复都会产生累积影响。 作者强调两类边界。第一是资源-性能边界:模型越大、推理越强,成本、延迟、部署复杂度也越高;在 Agent 场景中,模型会被多次调用,单次调用成本会被长轨迹放大。第二是测量边界:静态基准可能无法区分真实任务能力,因为当 frontier 模型在 MMLU-Pro、GPQA Diamond 等指标上分数接近时,细小差异未必对应真实长程任务差异。 对 Agent 来说,评测必须考虑任务时长、步骤数、环境交互、工具使用、状态持久化、安全约束和恢复需求。否则,强模型在静态问答中的优势可能在真实运行时被上下文漂移、错误动作、状态丢失或验证不足抵消。
4. Paradigm Shifts in Agent Engineering | Agent工程范式迁移
论文将 Agent 工程演化分成四个阶段。第一阶段是 Prompt Engineering,核心是通过提示词激发模型已有能力,包括 few-shot、chain-of-thought、self-consistency、tree-of-thought、ReAct 等。它解决的是“如何问”和“如何诱导推理”的问题,但无法稳定管理知识缺失、长期状态和外部执行。 第二阶段是 Workflows and Context Engineering,优化对象从单个 prompt 转向多步任务的信息生命周期。它关注检索、记忆、工具定义、上下文压缩、技能披露和中间产物管理。问题从“答案是否正确”转向“上下文是否足以支撑多步任务”。 第三阶段是 Harness Engineering,真正闭合 observe-reason-act-feedback 循环。此时系统不仅组装上下文,还要执行动作、观察结果、验证状态、处理错误、回滚和恢复。harness 成为主要设计对象。 第四阶段是 Agent-Native Training and Co-Evolution。一部分 agentic 行为,如规划、工具使用、验证、恢复,开始被训练进模型参数;同时模型、harness 和改进循环可能在部署经验中共同演化。
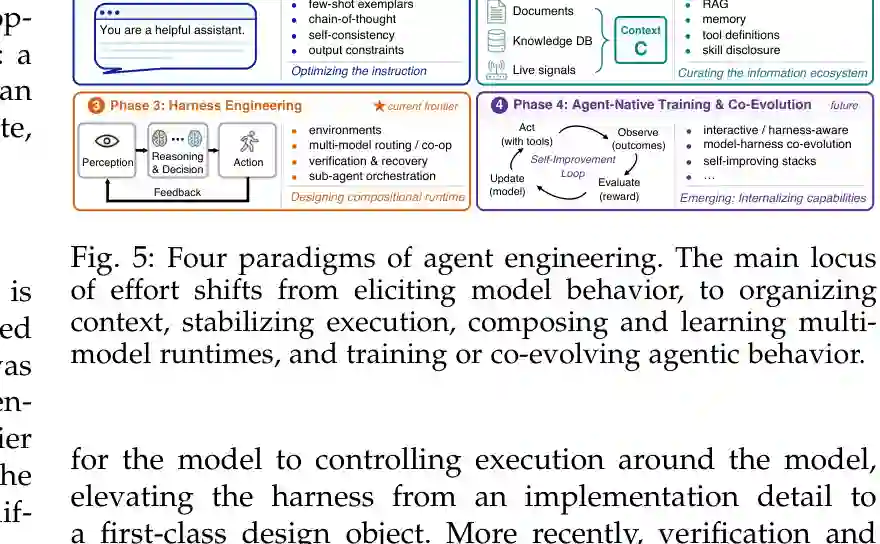
图5:Agent 工程四个范式。工程重点从提示词、上下文组织、运行时稳定执行,逐步走向模型-harness 共演化。
5. Anatomy of the Execution Harness | 执行Harness解剖
六个运行时职责
本文的核心贡献之一,是把 execution harness 拆成六个相互耦合的运行时职责:Observation Interface、Context Manager、Control Loop、Action Interface、State and Artifact Store、Verification and Governance。
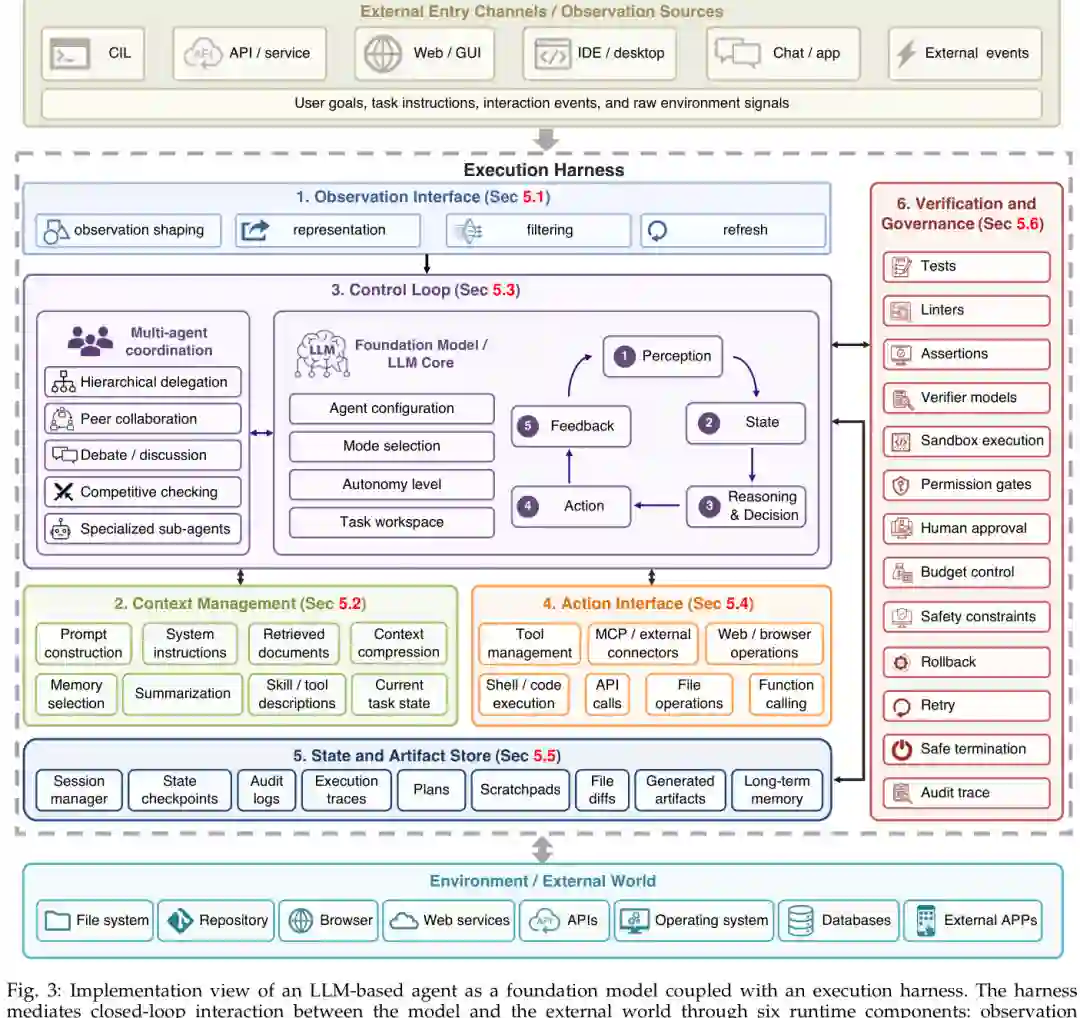
图6:LLM Agent 的执行 harness 架构。模型位于闭环中央,外部环境通过六类运行时职责被观察、组织、执行、保存和验证。 Observation Interface 负责把终端输出、文件 diff、截图、DOM、API 响应、日志、检索片段等环境信号转换成模型可用观察。关键不是暴露所有状态,而是暴露对下一步决策有用、忠实且可处理的状态。 Context Manager 决定什么信息进入上下文、何时进入、以什么形式进入,包括 prompt 构造、系统指令、检索、记忆选择、压缩、摘要、工具描述和当前任务状态。它管理的是动态信息生态,而不是静态上下文窗口。 Control Loop 组织观察、推理、行动和反馈循环,包括步骤调度、停止条件、重试、反思、委派、handoff、多 Agent 协作和多模型路由。长期任务是否稳定,很大程度取决于控制循环如何处理不确定性。 Action Interface 将模型输出映射为可执行操作,如函数调用、MCP 工具、shell 或代码执行、浏览器动作、文件操作、API 调用和子 Agent 调用。动作接口的质量直接决定工具是否可组合、可约束、可恢复。 State and Artifact Store 持久化对话历史、计划、scratchpad、checkpoint、日志、执行轨迹、diff、记忆记录、生成文件和任务产物。长程任务失败往往不是因为模型不会推理,而是因为状态保存、检索或更新策略出错。 Verification and Governance 负责测试、断言、验证器模型、沙箱、权限门、人类审批、预算控制、安全约束、回滚、重试、安全终止和审计轨迹。它让 Agent 从“听话执行”走向“可控执行”。
跨层耦合
这六层不是独立模块。更丰富的 observation 会改善 grounding,但增加上下文选择和压缩成本;更强 action interface 扩大能力边界,也提高权限和安全压力;更完整的 state store 增强连续性,却可能带来陈旧信息和状态漂移。harness 设计因此是系统级优化,而不是简单堆组件。
6. Task Landscape and Harness Configuration | 任务图谱与Harness配置
不同任务会给 harness 施加不同压力。论文用三个维度刻画任务:任务时长、环境类型和自治程度。单步任务主要依赖上下文管理和验证;多步任务开始依赖动作接口、状态存储和治理;长程任务需要跨步骤保存计划、证据和中间产物;开放式任务还需要预算控制、停止条件、回滚和人类升级。
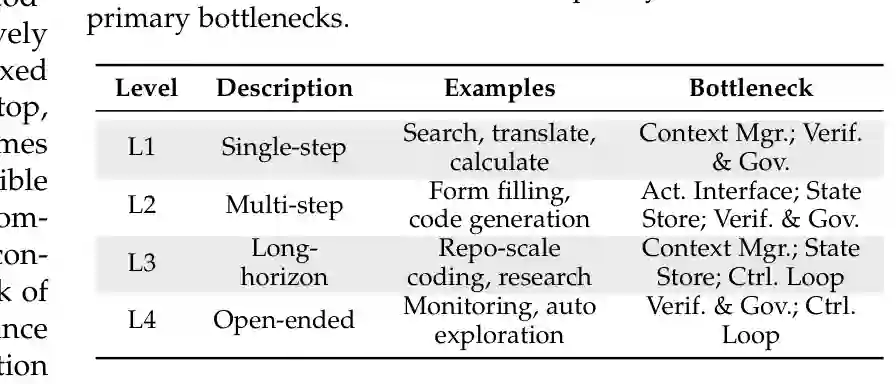
图7:任务复杂度等级与主要瓶颈。任务越长、越开放,harness 的状态、控制和治理压力越大。 环境类型同样重要。代码和终端任务可以依赖文件系统、测试和日志形成强验证信号;浏览器和桌面任务引入视觉状态、DOM grounding 和不可逆副作用;知识型任务依赖证据质量、来源和综合能力;物理环境则带来实时约束和不可逆风险。 论文的核心建议是:不要按应用标签设计 Agent,而要按任务压力配置 harness。一个浏览器 Agent、编码 Agent 和研究 Agent 可能都用同一个 LLM,但需要完全不同的观察、动作、状态和验证策略。
7. Evaluation and Analysis | 评测与分析
Agent 评测不能只报告 task success。论文认为,可靠比较需要同时考虑成功率、稳定性、效率、延迟、安全性和过程质量。否则两个系统最终分数相同,背后的资源消耗、重试次数、上下文规模、失败恢复能力可能完全不同。

图8:LLM Agent 代表性基准。不同基准覆盖交互网站、真实 GitHub issue、桌面环境、终端任务、MCP 工具使用和企业式任务。 论文梳理 SWE-bench Verified、Terminal-Bench 2.0、WebArena 等基准证据,指出 model 和 harness 都会影响最终成绩。在固定模型下,不同 harness 可以让 Terminal-Bench 分数相差超过 10%,差异来自命令接口、状态表示、上下文管理、停止条件和恢复策略。WebArena 也显示,浏览器 Agent 的成功不仅取决于模型,还取决于页面状态如何暴露、动作如何约束、搜索与重试预算如何配置。 作者因此提出,benchmark 应报告更丰富的运行时数据:token/API 成本、工具调用次数、重试次数、P95 延迟、恢复行为、安全违规和轨迹可审计性。Agent 评测应从“分数排行榜”走向“运行时画像”。
8. Outlook and Future Directions | 展望与未来方向
价值感知优化
未来 Agent 不应只最大化任务成功率,而应进行 value-aware optimization。不同任务的用户价值、成本约束、延迟要求和风险容忍度不同。高价值高风险任务可以接受更强验证和更高成本,而高频常规任务更需要低成本、短轨迹和严格停止策略。
学会验证、恢复和适应
执行轨迹不仅是评测记录,也是训练资源。未来 Agent 应从轨迹中学习如何验证中间状态、诊断失败、从局部错误恢复,并跨任务适应。规划和工具使用只是第一步,真正可靠的 Agent 还要学会何时停止、何时重试、何时升级给人类。
泛化与规格边界
harness 泛化仍是难点。一个在 SWE-bench 上有效的 harness,不一定适合 WebArena 或 Terminal-Bench;一个适合企业内部工具的 Agent,也不一定能泛化到开放互联网。未来需要研究 model-harness compatibility,即模型能力和运行时暴露方式之间的匹配关系。
9. Conclusion | 结论
这篇综述的主张非常明确:LLM Agent 的进步不应只归因于基础模型增强,也不能把工具、记忆和验证看作附属模块。Agent 的可靠性、效率、安全性和泛化能力,来自模型与 execution harness 的耦合。 从问答到任务完成,工程瓶颈已经从“如何写提示词”迁移到“如何组织上下文、稳定执行、保存状态、验证结果和恢复错误”。未来更强的 Agent 系统,很可能不是单纯更大的模型,而是模型能力、harness 设计、任务结构和价值感知评测共同演化的结果。