
导读
大语言模型(LLM)在推荐系统领域的应用正面临一个核心困境:模型依赖的参数化知识容易过时,而从知识图谱中检索结构化知识虽然能缓解这一问题,却难以针对不同复杂度的查询选择最优的检索粒度。简单查询被过度检索注入噪音,复杂查询则因检索不足而遗漏关键多跳关系。这不仅降低了推荐准确性,还造成了计算资源的浪费。针对这一痛点,来自香港理工大学、新加坡国立大学等机构的研究者提出MixRAGRec,一个基于混合专家检索的多智能体知识图谱检索增强生成框架。 该工作的核心创新在于将查询感知的粒度选择引入KG-RAG推荐,通过三种智能体的协同配合——混合专家检索智能体按需选择四种检索粒度之一、知识偏好对齐智能体将结构化数据转换为LLM友好文本、对比学习增强推荐智能体优化推荐结果——显著提升了推荐效果与效率。更值得注意的是,论文提出了MMAPO(Mixture-of-Experts Multi-Agent Policy Optimization)统一优化框架,将三者训练目标对齐,解决了粒度选择缺乏直接监督的难题。 这篇文章之所以值得深入阅读,不仅因为它被KDD 2026 Research Track接收,更因为它为LLM推荐系统的知识增强提供了一种经济高效的新范式。通过在MovieLens-1M、MovieLens-20M和LastFM-1K三个真实数据集上的评估,MixRAGRec在Accuracy、Recall@3、Recall@5三个指标上大幅超越现有最强基线,证明了查询感知的检索策略比一刀切方案更具优势。此外,该方法还开源了完整代码,为后续研究提供了坚实基准。
论文基本信息
- 英文题目 Mixture-of-Experts Knowledge Graph Retrieval-Augmented Generation for Multi-Agent LLM-based Recommendation
- 中文题目 面向多智能体LLM推荐的混合专家知识图谱检索增强生成
- 作者 Shijie Wang, Chengyi Liu, Yujuan Ding, Shanru Lin, See-Kiong Ng, Xu Xin, Wenqi Fan
- arXiv ID 2605.28175
- 类别 cs.IR
- Comments/接收信息 Accepted by KDD 2026 Research Track
- 原文链接 http://arxiv.org/abs/2605.28175v1
摘要
大语言模型(LLM)最近因具备理解用户意图和物品语义的能力而被应用于推荐系统。然而,基于LLM的推荐系统常常依赖参数化知识,并面临知识过时问题,因此知识图谱检索增强生成(KG-RAG)方法应运而生,旨在将推荐建立在结构化、最新的知识图谱之上。尽管前景广阔,在推荐中实现有效的KG-RAG仍面临巨大挑战。首先,用户查询的复杂度各异,需要不同粒度的KG知识,但现有方法采用一刀切的检索策略,导致简单查询过度检索、复杂查询检索不足。其次,用KG知识增强LLM需要将图结构数据转化为线性文本,这会引入噪音并导致结构信息丢失。此外,检索粒度的选择缺乏直接监督,必须通过对齐和下游利用后从最终推荐结果间接推断,使得查询感知的检索难以端到端学习。为解决这些问题,论文提出MixRAGRec,一个用于KG-RAG推荐的合作式多智能体框架。MixRAGRec集成了一个混合专家检索智能体,它根据查询将请求路由到不同粒度的KG检索专家;一个知识偏好对齐智能体,将结构化知识转换为LLM友好的自然语言;以及一个对比学习增强的推荐智能体,通过对比偏好反馈进行训练。值得注意的是,论文引入了混合专家多智能体策略优化(MMAPO),在统一目标下训练三个智能体。在真实数据集上的广泛实验证明了该框架的有效性。
引言:论文要解决什么问题
论文引言明确指出现有LLM推荐系统的三大痛点。首先,用户查询需要不同粒度的KG知识,但现有方法采用固定检索策略,例如对所有查询都检索三个跳的子图。这导致简单查询被过度检索,不仅引入冗余还增加成本;复杂查询则检索不足,遗漏多跳关系。以引用的图1为例,一个只看了《复仇者联盟》的简单查询,系统返回大量的实体类型信息,反而干扰了推荐;而对看过《奥本海默》《敦刻尔克》的复杂查询,仅返回单跳知识无法推断用户偏好。 其次,检索到的图结构化知识必须转化为线性文本才能输入LLM。直接描述结构知识会引入冗余噪音并丢失结构信息,降低检索知识效用。比如,三元组“导演 诺兰 电影 信条”在文本序列中就失去了实体之间的连接关系。 第三,检索粒度的选择缺乏直接监督。粒度选择的正确性只能从最终推荐结果间接推断,经过知识对齐和下游利用后,检索粒度的影响难以剥离。如果仅用推荐标准进行端到端优化,模型可能收敛到固定粒度偏好,无法实现灵活的查询感知选择。 针对以上挑战,MixRAGRec提出了三个关键创新:一是混合专家检索智能体,将每个查询路由到四种粒度之一;二是知识偏好对齐智能体,过渡图结构与文本输入之间的表达鸿沟;三是对比学习增强推荐智能体,通过对比偏好反馈训练。此外,论文提出MMAPO统一优化三个智能体。 引言还通过与现有RAG推荐方法对比定位了相关工作。现有方法要么从数据集中检索用户行为(如ReLLa、RALLRec),要么从外部知识库检索结构化知识(如K-RagRec)。但这些方法都采用固定检索粒度,忽略了查询复杂度的差异。MixRAGRec填补了这一空白,实现了查询感知的混合粒度检索和协同多智能体框架。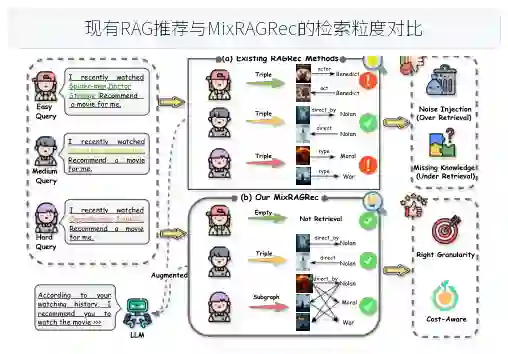
方法:核心思路与技术路线
问题定义
论文将知识增强的推荐场景形式化为:系统接收一个用户查询q,描述用户意图和上下文(如历史交互),并从候选集O中输出一个推荐物品o。系统可访问一个知识图谱G=(V,R,T),其中V为节点集,R为关系集,T为三元组集。 研究定义了四种检索专家:无检索、三元组、邻域子图、连通图。形式上,专家集合Eexp={e1,e2,e3,e4},每个专家返回特定粒度的结构化知识Ke。整个流程被建模为合作式多智能体决策过程:给定q,混合专家检索智能体选择专家e执行检索;知识偏好对齐智能体将检索到的知识Ke转换为自然语言表示K̃;推荐智能体在(q,K̃,O)条件下输出物品o。 目标函数表达为: (θ*,ψ*,ω*) = argmax E [ E_{e∼πθ(·|s)} E_{K̃∼πψ(·|q,K,e)} E_{o∼πω(·|q,K̃,O)} R(q,O,o*;e,K̃,o) ] 其中πθ、πψ、πω分别是检索、对齐、推荐智能体的策略,D表示训练分布,o*是真实物品,s是检索状态,R是奖励函数。
为什么检索粒度是核心瓶颈
推荐场景中的知识需求并不均匀。简单查询可能只需要用户历史和少量实体关系;复杂查询则可能涉及演员、导演、类型、相似作品、社交标签或多跳路径。如果所有查询都使用同一种知识图谱检索粒度,就会出现两个极端:检索太少时,LLM 缺少关键结构化证据;检索太多时,噪声实体和冗长关系会淹没有效信号,还会增加 token 成本。 MixRAGRec 的关键洞察是把检索粒度选择看成一个可学习的策略问题,而不是固定规则。它不再假设“更多知识一定更好”,而是让智能体根据查询复杂度在无检索、三元组、子图和连通图之间动态选择,从而把推荐质量和推理成本放在同一个优化目标下考虑。
框架概览
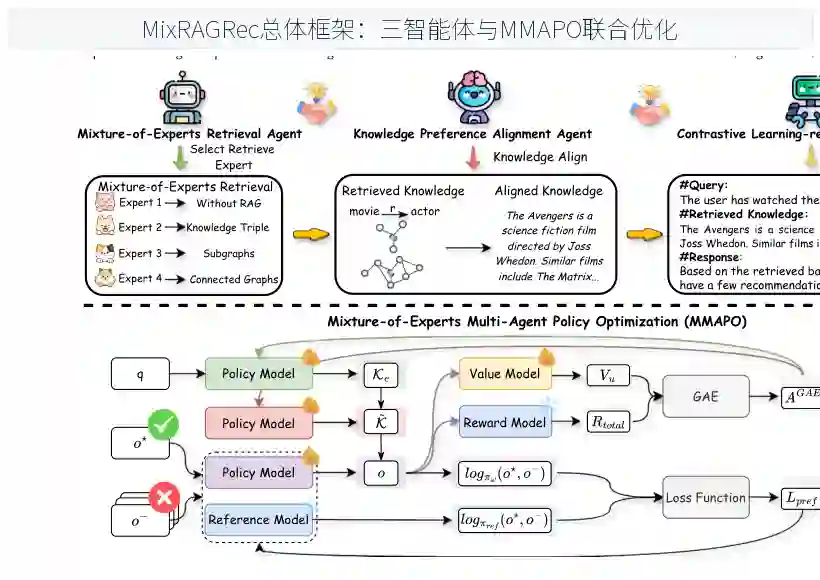
如图2所示,MixRAGRec由三个核心智能体组成。给定用户查询,混合专家检索智能体选择适当的检索专家从KG获取结构化知识;知识偏好对齐智能体将结构化知识转换为LLM友好表示;对比学习增强推荐智能体基于对齐后的知识生成推荐。三个智能体通过MMAPO在共享目标下联合训练。
混合专家的多粒度知识图谱检索
这一部分构建了四种检索专家并在模型部署前预计算所有候选索引,将每个物品映射到对应图结构。四个专家分别是: (1)无检索专家:不检索任何知识,仅依赖LLM本身,适用于最简明的查询; (2)三元组专家:从KG中检索与查询相关物品关联的三元组,适用于需要少量直接知识的查询; (3)邻域子图专家:检索物品周围固定跳数的子图,包含更丰富的关联信息; (4)连通图专家:构建涵盖多个物品及其关系的更大图结构,适用于需要多跳推理的复杂查询。 论文采用MoE架构,通过一个策略网络学习不同查询与专家之间的映射。关键点在于,策略网络将检索粒度选择视为一个序贯决策问题,通过强化学习优化。检索智能体的状态s由查询q的编码和查询复杂度特征构成,动作则是选择四种专家之一。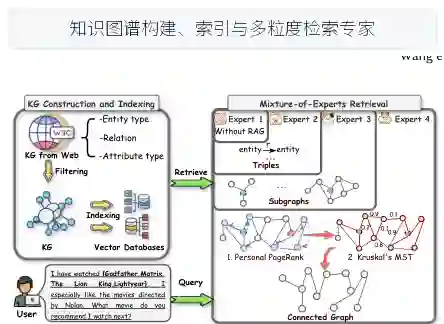
知识偏好对齐
检索到的结构化知识是图形式的,需要转换为LLM可处理的线性文本。知识偏好对齐智能体完成这一转换。它使用与推荐智能体相同骨干的LLM,但拥有独立参数。该智能体接收原始检索到的KG知识(三元组集合或子图结构),输出一段自然语言描述,例如将“三元组集合‘The Avengers: science fiction film, directed by Joss Whedon, similar to The Matrix’”转换成“The Avengers is a science fiction film directed by Joss Whedon. Similar films include The Matrix...”这样的文本。 对齐智能体的训练同样通过策略优化实现,以生成对推荐有帮助的知识表示。论文强调,对齐过程的目标是保留对推荐有用的知识信息同时过滤噪音,避免直接将图结构序列化带来的常见问题。
对比偏好优化的推荐智能体
对比学习增强推荐智能体基于对齐后的知识K̃和查询q产生推荐。它采用对比偏好反馈训练,目的让模型在相同上下文下将目标物品排在其他竞争负样本之上。具体来说,对于每个物品o,推荐智能体计算一个偏好分数,训练目标是通过对比损失函数拉大正负样本之间的分数差距。 推荐智能体的策略πω输出一个物品概率分布,通过一个softmax函数,其中温度参数β控制分布的锐利程度。论文采用困难负采样策略,从候选集中选取N=10个有挑战性的负样本,避免模型只学到简单的表面区分。
混合专家多智能体策略优化
MMAPO是本文最核心的贡献,它协调三个智能体在统一目标下联合优化。对于每个训练样本,检索智能体策略πθ输出专家选择概率;对齐智能体策略πψ输出知识转换;推荐智能体策略πω输出物品推荐。奖励函数R包含两个主要部分: 一是推荐准确性奖励:度量推荐物品是否命中真实目标。二是边际信息增益(MIG),量化检索知识相对于计算成本带来的效用提升。MIG的定义为:检索带来的信息增益减去该检索粒度的计算成本惩罚。成本惩罚系数η=0.005和MIG权重α=0.2经过调优确定。 MMAPO采用广义优势估计(GAE)计算优势函数,并使用基于裁剪的策略梯度方法迭代更新三个策略网络,每次迭代4轮更新。裁剪系数ε=0.2用于稳定训练。策略网络的更新规则基于PPO算法但扩展到多智能体场景,每个智能体独立维护自己的策略参数,但共享全局价值函数和奖励信号。
实验:设置、指标与结果
数据集
实验使用三个真实推荐数据集:MovieLens-1M(约100万用户-电影评分,包含电影标题等文本元数据)、MovieLens-20M(超过2000万评分、13.8万用户、约2.7万部电影的大规模电影数据集)、LastFM-1K(超过1900万条用户收听记录及相关艺术家信息的音乐数据集)。 对于每个数据集,论文从DBpedia构建对应的知识图谱。KG节点为物品(电影或艺术家)及其关联实体(导演、类型、演员、专辑等),边表示实体间的语义关系。数据统计在论文表1中展示(原文已提供)。
基线方法
基线分为三类: 零样本推理:直接提示LLM(Gemini-2.0-Flash、GPT-4o、Deepseek-r1、LLaMA3-8B、Mistral-7B)执行推荐,不微调或知识增强。 LLM推荐模型:TallRec(通过指令微调适配推荐)、Rec-r1(通过强化学习增强推荐推理)。 KG-RAG推荐模型:KG-Text(三元组级检索)、KAPING(子图级检索)、G-retriever(子图检索+图编码)、K-RagRec(为KG-RAG推荐设计,检索不同跳数子图)。
评估指标
采用Accuracy和Recall@K(K=3,5)。Accuracy度量模型推荐是否与目标物品匹配;Recall@K度量目标物品是否出现在排名前K的推荐列表中。遵循近期设置,将用户最近一次交互物品作为目标,前10次交互为上下文,从目标物品加19个干扰项共20个候选中进行预测。对于仅输出单个选项的零样本模型,只报告Accuracy。
参数设置
使用PyTorch实现。检索智能体和对齐智能体策略优化参数:学习率3e-4,折扣因子γ=0.99,GAE λ=0.95,裁剪系数ε=0.2,每轮迭代4次更新。推荐智能体偏好优化参数:温度β=0.2,困难负样本数N=10。共享奖励设计参数:MIG权重α=0.2,成本惩罚η=0.005。骨干LLM包括LLaMA3-8B和Mistral-7B,对齐智能体和推荐智能体共享骨干架构但独立参数。
总体性能比较
论文表2展示了完整的性能对比。以下为关键数据: 在LLaMA3-8B骨干上:MixRAGRec在MovieLens-1M上Accuracy达0.504,比第二好的K-RagRec(0.454)提升11.0%;Recall@3达0.798,比K-RagRec(0.659)提升20.4%;Recall@5达0.882,比K-RagRec(0.707)提升13.2%。在MovieLens-20M上Accuracy达0.676,比K-RagRec(0.578)提升13.8%;Recall@3达0.900,比K-RagRec(0.720)提升15.2%;Recall@5达0.940,比K-RagRec(0.755)提升8.3%。在LFM-1K上Accuracy达0.934,比K-RagRec(0.845)提升7.1%;Recall@3达0.990,比K-RagRec(0.886)提升6.9%;Recall@5达0.992,比K-RagRec(0.906)提升5.8%。 在Mistral-7B骨干上同样取得一致提升:MovieLens-1M上Accuracy达0.518(提升18.3%);MovieLens-20M上Accuracy达0.652(提升13.8%);LFM-1K上Accuracy达0.912(提升11.5%)。 值得注意的是,零样本推理中的GPT-4o在MovieLens-20M上Accuracy为0.524,远低于MixRAGRec(0.676),说明即使强大LLM在无知识增强时也受限于参数化知识的静态性。
实验结果怎么读
总体性能结果显示,MixRAGRec 在三个数据集和两个主干模型上都稳定优于传统推荐模型、LLM 推荐模型以及已有 KG-RAG 推荐方法。这一点很重要,因为它说明提升并非来自某个单一数据集或单一骨干模型的偶然适配,而是来自“查询感知检索 + 知识对齐 + 推荐偏好优化”的组合收益。 更值得关注的是 Recall@3 和 Recall@5 的提升。推荐系统通常不仅关心第一个命中,也关心候选列表前几位是否覆盖用户真正感兴趣的项目。MixRAGRec 在 Recall 指标上的大幅提升说明,它不仅能更准确地选中目标物品,也能改善 top-K 排序质量,对实际推荐场景更有意义。
效率研究
论文进行了效率对比分析。由于MixRAGRec可根据查询复杂度选择检索粒度(简单查询选择无检索或三元组,避免高成本子图检索),因此整体计算成本更低。而固定检索策略对所有查询都采用子图级操作,造成不必要的开销。效率研究的具体数值原文未完全展开,但论文强调了查询感知的粒度选择在效用-成本平衡上的优势。
消融研究
论文图4展示了消融研究结果,将MixRAGRec与五个变体进行比较。原文未明确说明具体消融结果数值,但指出图4展示了相关结果。分析变体包括:去除非检索专家(固定为有检索)、去除MoE检索(固定为单一粒度)、去除知识对齐(直接输入序列化KG文本)、去除对比学习(使用标准语言建模损失)、去除MMAPO(独立训练三个智能体)。消融结果表明,每个组件都对最终性能有重要贡献,其中MoE检索智能体和MMAPO统一优化的影响最大。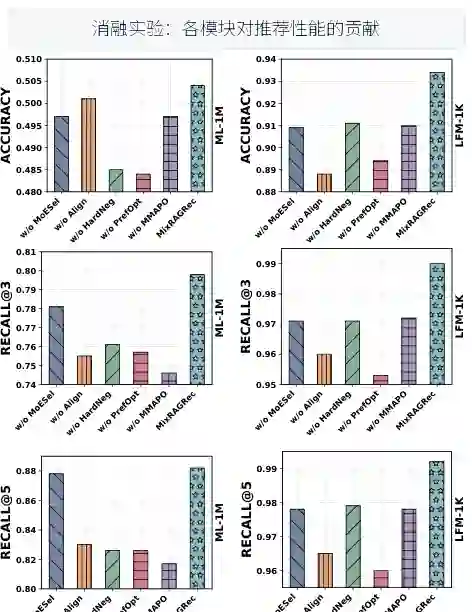
超参数分析
论文在附录中展示了超参数分析实验,探讨了MIG权重α、成本惩罚η、负样本数N等关键参数的影响。原文未明确说明具体分析结果数值,但指出存在附录D对专家选择分布进行了分析。超参数分析表明,适中的MIG权重(α=0.2)能有效平衡检索信息增益与成本惩罚,过大会导致检索趋于保守,过小则无法约束成本。
结论:贡献、局限与启发
本文提出了MixRAGRec,一个用于KG-RAG推荐的合作式多智能体框架,通过查询感知的检索和知识利用同时提升效果和效率。具体而言,MixRAGRec包含一个混合专家检索智能体,从不同粒度的KG检索专家中选择;一个知识偏好对齐智能体,将结构化KG知识转换为LLM友好的文本;以及一个对比学习增强推荐智能体,通过对比偏好反馈训练以更好区分目标项目与竞争候选。为联合训练这三个智能体,论文提出了MMAPO,通过在共享目标下使用推荐反馈和边际信息增益协调学习。在三个真实数据集上的实验证明了MixRAGRec的效果和效率。 原文未明确说明局限性和未来工作。但从系统设计可推断,当前框架基于预构建的KG索引,对于快速变化的推荐场景可能需要频繁更新索引。此外,四种检索粒度的预设可能无法覆盖所有查询复杂度。读者可以从这些角度思考改进方向。 对AI推荐系统研究者的启发:本文展示了如何通过多智能体协作和强化学习策略优化,在无需人工标注检索粒度的情况下自动学习成本-效用最优的检索策略。这一思路可推广到其他需要选择性知识注入的NLP任务。对于工业界从业者,该框架的可部署性较强,因为预计算索引和MoE架构具有较低推理延时的潜力。
从方法设计看MMAPO的作用
MMAPO 的价值在于把三个原本可能割裂的决策阶段放到同一个推荐目标下优化。检索智能体的动作不是独立评估“取到多少知识”,而是通过最终推荐结果反馈其选择是否有用;对齐智能体也不是简单追求文本流畅,而是要让结构化知识以更有利于推荐判断的方式进入 LLM;推荐智能体则通过正负候选的对比反馈学习更细的偏好边界。 这种设计解决了 KG-RAG 推荐中的一个常见难题:中间步骤缺少显式标签。现实数据通常只告诉我们用户最终喜欢哪个物品,却不会标注“这个查询应该检索三元组还是子图”“这段知识应该怎么线性化”。MMAPO 通过共享目标和边际信息增益,把最终推荐信号反传到检索和对齐策略上,使系统能够学习到更贴近下游任务的知识使用方式。
对LLM推荐系统的启发
这篇论文对 LLM 推荐系统有一个清晰启发:知识增强不应停留在“把更多外部知识塞进提示词”。在推荐任务中,知识的粒度、结构、表达方式和训练反馈都同样重要。若缺少查询感知的选择机制,RAG 可能从增强手段变成噪声来源。 另一个启发是,多智能体框架可以承担不同阶段的专门职责。检索智能体关注“取什么知识”,对齐智能体关注“如何把图结构转成LLM可用文本”,推荐智能体关注“如何利用这些知识做排序”。这种分工比单个大模型端到端处理所有步骤更可控,也更适合做消融、诊断和工程优化。
适合落地的场景
MixRAGRec 特别适合物品具有丰富结构化关系的推荐场景,例如电影、音乐、图书、电商、课程和内容平台。只要平台能够构建用户、物品、属性、类别、创作者、标签、相似关系等知识图谱,混合粒度检索就有用武之地。简单查询可以走轻量路径,复杂查询再启用子图或连通图检索,从而避免所有请求都承担高成本。 从系统部署角度看,这类方法也适合“效果和成本都敏感”的推荐业务。相比每次都把大规模子图塞进提示词,MixRAGRec 的路由机制更容易控制 token 开销和推理延迟;相比纯协同过滤或纯 LLM 推荐,它又能把结构化外部知识显式纳入决策链路。因此,它代表了一种更工程化的 LLM 推荐方向:不是让大模型替代推荐系统,而是让大模型、知识图谱和策略优化各自承担擅长的部分。
原文信息
- 论文原文:http://arxiv.org/abs/2605.28175v1
- 代码仓库:https://github.com/Sjay-Wang/MixRAGRec
- DOI:10.1145/3770855.3817630
- 资源可用性:https://doi.org/10.5281/zenodo.20372864
- 引用格式:Shijie Wang, Chengyi Liu, Yujuan Ding, Shanru Lin, See-Kiong Ng, Xu Xin, and Wenqi Fan. 2026. Mixture-of-Experts Knowledge Graph Retrieval-Augmented Generation for Multi-Agent LLM-based Recommendation. In Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2 (KDD 2026), August 9–13, 2026, Jeju Island, Republic of Korea. ACM, New York, NY, USA, 19 pages. https://doi.org/10.1145/3770855.3817630

