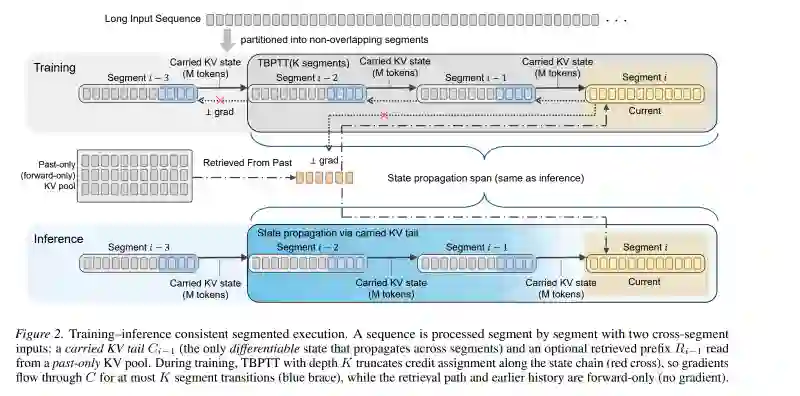
基于Transformer的大语言模型在长上下文生成中,由于全上下文注意力的计算和内存开销,面临严重的可扩展性挑战。在实际计算与内存约束下,许多面向推理效率的长上下文方法仅在推理阶段采用有界上下文或分段级执行来提升效率,而模型训练仍采用全上下文注意力,导致训练与推理的执行方式及状态转移语义之间出现错配。基于这一观察,我们提出了一种训练–推理一致的分段级生成框架,使训练和推理遵循相同的分段级前向执行语义。在训练过程中,通过将梯度传播限制在由紧前一段传递过来的KV状态上,强制保持与推理的一致性;同时允许在前向过程中各注意力头按需访问过去的KV状态,但不将其纳入梯度传播。在多个长上下文基准上,本方法取得了与全上下文注意力相当的性能,同时在延迟与内存的权衡上优于具有竞争力的推理高效基线,并且在极长上下文长度下显著提升了可扩展性(例如,在128K上下文长度下,与采用FlashAttention的全上下文注意力相比,峰值预填充内存降低约6倍)。长上下文建模对于大语言模型日益重要(Achiam 等,2023;Team 等,2024;Anthropic,2024),支撑着文档理解、持续对话和复杂推理等实际应用(Bai 等,2024)。然而,全上下文自注意力机制的二次计算复杂度从根本上限制了 Transformer 模型在长上下文场景下的可扩展性(Vaswani 等,2017;Keles 等,2023)。因此,长上下文推理通常采用受限执行方式,如有界上下文或分块注意力,以降低计算开销(Xiao 等,2024;Liu 等,2025)。近期工作通过保持注意力语义的执行层面优化,大幅提升了长上下文推理效率,在不改变模型输出的前提下降低内存消耗和实际推理成本(Dao,2024;Agrawal 等,2023)。然而,随着上下文长度不断扩展,仅靠这些保持语义的执行优化所带来的资源节省在实践中往往仍显不足(图1),因此通常采用更为受限的执行策略,如窗口化或稀疏注意力机制。 尽管这些方法在推理时有效,但现有大多数做法仅在推理阶段施加此类受限执行,而训练时仍依赖全上下文注意力。这导致训练与推理之间在执行方式和跨段状态演化上出现错配。其结果是,模型可能依赖训练时可获取但在受限推理条件下缺失的信息,从而损害长上下文场景下的稳定性和泛化能力。 为解决这一局限,我们提出一种训练–推理一致的分段级生成框架,将分段执行视为共享的建模假设,而不仅仅是推理阶段的优化手段。我们将序列划分为多个分段,仅携带一个固定大小的 KV 尾部作为唯一可微的跨段接口状态,该状态在训练和推理中原样使用。训练通过截断的时间反向传播(TBPTT)将跨段信用分配限制在最近的 K 次状态转移中;在这种严格有界的递归下,TBPTT 计算出推理一致目标的精确梯度,防止模型依赖推理时不可用的信息。为访问超出携带 KV 视界之外的证据,模型额外以纯前向方式(无梯度)消费检索到的 KV 前缀,该前缀不参与状态递归。在架构上,我们通过按头与层稀疏的长程注意力头来实现这一设计,而大多数注意力头则支持局部的、携带状态的计算,从而产生训练与推理严格对齐的执行语义。 本文贡献如下: • 我们提出一种面向长上下文建模的分段级建模框架,通过设计强制训练–推理一致性,将跨段信息流分解为局部连续性通道和提供长程条件的独立纯前向机制。 • 我们证明,通过将跨段学习限制在受控接口状态上,即可在理论上保证训练–推理对齐,且无需引入持久记忆变量。在此受限形式下,截断反向传播计算出的是推理一致目标的精确梯度,而非近似梯度。 • 我们在多个长上下文基准和不同上下文长度上对所提出的训练–推理一致性框架进行了实证验证,结果表明在受限执行条件下具有强大性能;消融实验表明 K=1 的 TBPTT 已足够且最优;同时在可扩展性上大幅提升(例如,在 128K 上下文预填充下,内存消耗仅为全注意力的约 1/6)。