
具身智能正在从看见并执行的视觉-语言-动作模型,迈向能够预测世界变化并据此规划动作的下一代基础模型。本文综述的 World Action Models(WAMs)正是这一转向的代表:它不只学习从观测到动作的反应式映射,而是把未来状态预测和动作生成放到同一个建模框架中,让智能体具备更强的前瞻性、可规划性和物理一致性。
这篇综述首次系统梳理了 WAMs 的概念边界、形式化定义、架构路线、训练数据生态和评估协议。文章将现有方法划分为级联式和联合式两类:前者先预测未来世界状态,再由动作模型解码控制命令;后者则在统一模型中同时生成未来状态与动作。二者分别代表了可复用强世界模型和紧耦合策略学习两条技术路线。 对于关注机器人基础模型、世界模型、VLA/VAM、具身多模态智能的研究者来说,这篇综述提供了一份清晰的领域地图:哪些数据最关键、哪些评估仍不完善、架构设计的核心权衡在哪里,以及 WAMs 距离真正开放世界部署还面临哪些瓶颈。
Abstract / 摘要
视觉-语言-动作(VLA)模型在具身策略学习上取得了强大的语义泛化能力,但它们仅学习反应性的观测-动作映射,未显式建模物理世界在干预下如何演变。近期研究工作通过将世界模型(环境动态预测模型)集成到动作生成流程中,从而形成一个新兴范式——我们称之为World Action Models (WAMs)。WAMs是统一预测状态建模与动作生成的具身基础模型,其目标是对未来状态和动作的联合分布 p(o', a | o, l) 进行建模,而不仅仅是动作本身。然而,该领域的文献在架构、学习目标和应用场景上仍然碎片化,缺乏统一的概念框架。本文正式定义WAMs并与相关概念进行消歧,追溯VLA和世界模型研究融合的基础与早期整合。我们将现有方法组织为级联(Cascaded)和联合(Joint)WAMs的结构化分类法,并进一步按生成模态、条件机制和动作解码策略进行细分。我们系统分析了支撑WAMs发展的数据生态,涵盖机器人遥操作、便携式人类演示、仿真数据和互联网规模的自我中心视频,并综合了围绕视觉保真度、物理常识和动作合理性组织的新兴评估协议。总而言之,本综述首次系统性地梳理了WAMs全景,阐明了关键架构范式及其权衡,并识别了该快速发展领域中的开放挑战和未来机遇。
1 Introduction / 引言
构建能在非结构化物理环境中感知、推理和行动的机器人,长期以来一直是具身AI研究的目标。近年来,该领域汇聚成一个强大范式:视觉-语言-动作(VLA)模型将预训练的视觉-语言骨干重新用作通用机器人策略。通过将动作生成表述为条件化令牌预测,VLA模型展示了显著的泛化能力。然而,标准VLA模型不显式建模世界动态——它们学习直接的观测-动作映射,而不预测环境在干预下如何变化。这种预测性物理推理的缺失限制了其在需要预判未来状态的情境中的泛化能力。因此,为具身策略模型配备世界建模能力成为一个自然的发展方向。
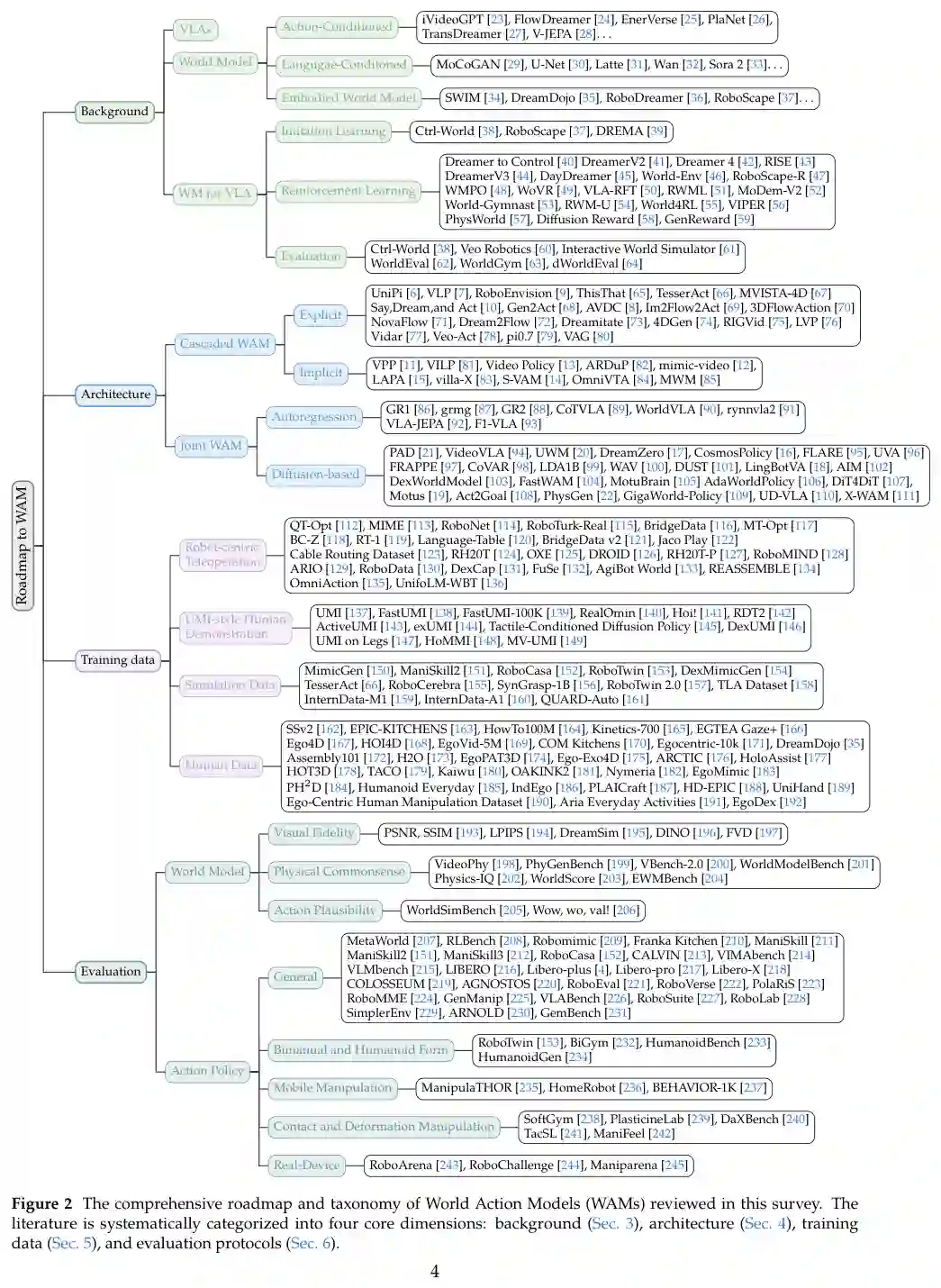
我们正式将这类方法统称为World Action Models (WAMs):统一预测状态建模与动作生成的具身基础模型,其目标是对未来状态和动作的联合分布进行建模。现有WAM方法可分为两种架构类别:(1) 级联WAM显式分解目标,先合成预测未来状态的表征,再从中推导出动作;(2) 联合WAM直接建模联合分布 ,状态预测和动作生成在共享表征空间中协同优化。配图说明: 图1展示了WAMs代表性作品的时间演进与分类。左侧分支展示联合WAM架构的进展(分为自回归和基于扩散的表示方案,连续方法进一步分为统一流和多流主干);右侧分支总结级联WAM流水线的发展(沿显式和隐式表示对齐轨迹演进)。这些结构策略代表了该领域在架构耦合方面的主要探索方向,而非严格的时序替代。(对应原论文第2页,图1)
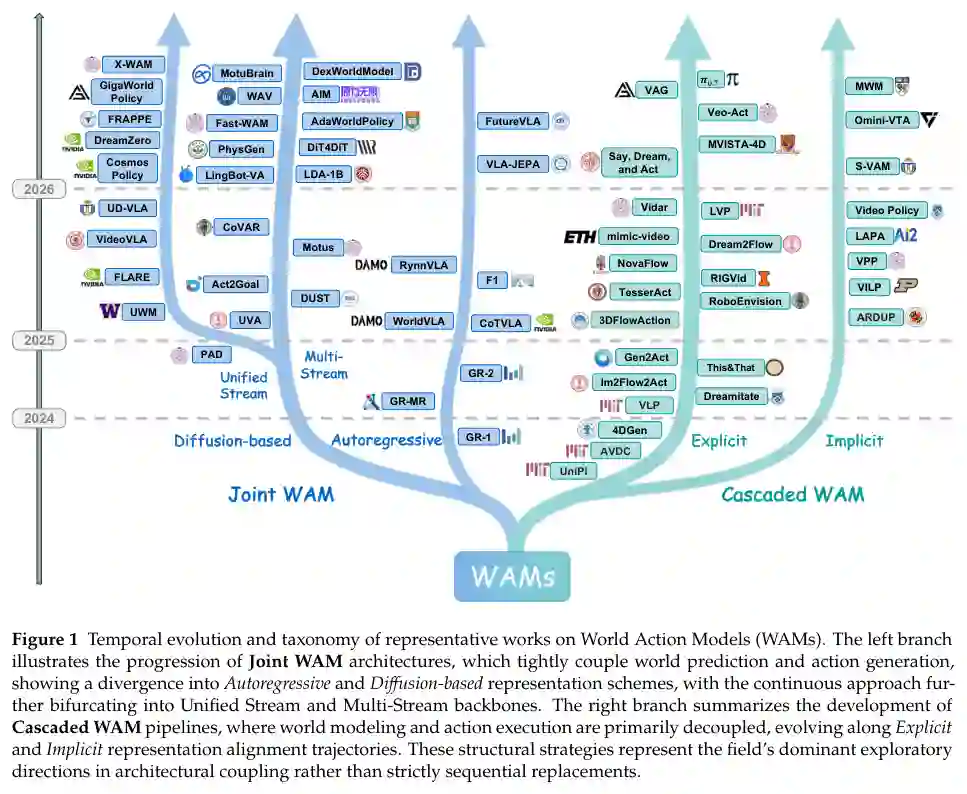
图 1:世界行动模型(WAMs)代表性作品的时间演进与分类。左侧分支展示了联合 WAM 架构的进展,这类架构紧密耦合世界预测与行动生成,分为自回归和基于扩散的表示方案,其中连续方法进一步分为统一流和多流主干。右侧分支总结了级联 WAM 流水线的发展,其中世界建模和行动执行主要解耦,沿着显式和隐式表示对齐轨迹演进。这些结构策略代表了该领域在架构耦合方面的主流探索方向,而非严格的时序替代。来源:原论文 PDF 第 2 页。
2 Definitions and Formalism / 定义与形式化
图 2:本文综述的世界行动模型(WAMs)综合路线图与分类。文献被系统地划分为四个核心维度:背景(第 3 节)、架构(第 4 节)、训练数据(第 5 节)和评估协议(第 6 节)。来源:原论文 PDF 第 4 页。
图 3:世界行动模型(WAMs)的概念定义与比较。左图对比了视觉-语言-行动(VLA)模型、WAMs 和标准世界模型(WMs)的输入-输出公式,突出了 WAM 同时预测行动和未来观测的能力。右图展示了 WAM 相对于视频行动模型(VAMs)和视频策略等其他范式的概念范围。来源:原论文 PDF 第 5 页。
2.1 Foundational Paradigms / 基础范式
视觉-语言-动作(VLA)模型是一类将机器人控制视为多模态序列建模任务的具身基础模型。代理处理当前观测 o 和语言指令 l,生成动作序列 a。VLA目标由给定多模态上下文中动作的条件概率定义:
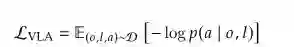
世界模型(WM) 定义为预测性的转移函数,内化了物理环境的因果动态。其功能角色是建模世界的前向动态,预测环境观测状态在假设干预下的演变:
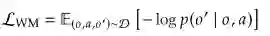
世界行动模型(WAM) 统一环境动态建模(世界建模)与电机控制(动作生成),必须满足两个核心条件:(1) 前向预测建模:模型必须通过生成或利用未来状态 o' 的可量化表征来预测环境的物理演变;(2) 耦合动作生成:模型必须通过将电机命令 o' 严格对齐预测的未来状态来推导动作。其目标为联合分布:` 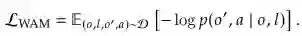
2.2 Disambiguation: WAM vs. Related Concepts / 消歧:WAM与相关概念的区分
- 视频行动模型(VAMs):VAMs特指将动作与视频帧合成对齐的模型。WAMs是模态无关的更广泛超集,“World”强调模型内化底层物理规律和因果动态,而非局限于像素级视频格式。
- 视频策略(Video Policies):视频策略通过继承视频生成骨干的时空表征将观测映射到动作(p(a|o)
)。WAMs要求主动预测承诺——下一状态o'` 的合成必须是模型推理和输出的显式组成部分。 - 行动世界模型(AWM):AWM的“World Model”作为名词,将系统定位为增强模拟器。WAM重新定位系统为代理的主要类别,其中“World”(预测物理)和“Action”(运动控制)是平等组件,作为VLA谱系的直接概念继承者。
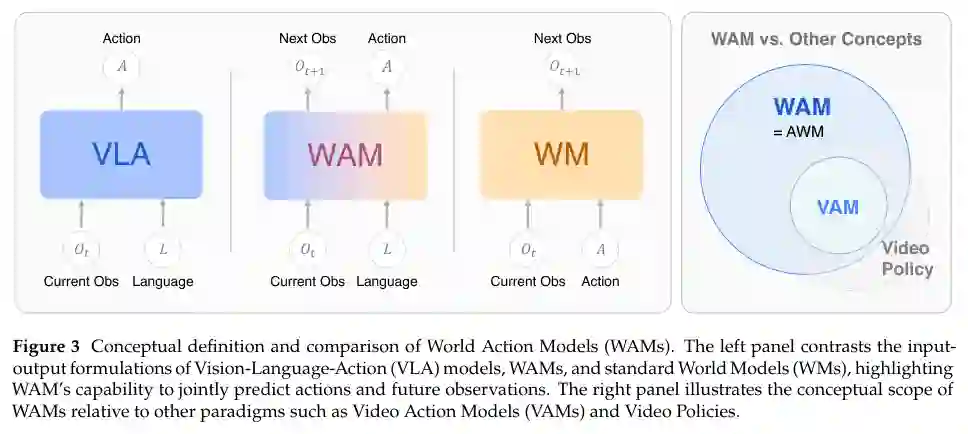
配图说明: 图3对比了VLA模型、WAMs和标准世界模型的输入-输出公式,突出了WAM同时预测动作和未来观测的能力;右图展示了WAM相对于视频行动模型和视频策略的概念范围。(对应原论文第5页,图3)
3 VLAs and World Models: Foundations and Early Integration / VLA与世界模型:基础与早期整合
3.1 Vision-Language-Action Models / 视觉-语言-动作模型
传统模仿学习受限于窄任务设计。为克服此问题,该领域转向语言条件化策略。早期VLA架构探索了三种融合视觉和语言输入的范式:(1) 特征调制(FiLM层);(2) 交叉注意力机制;(3) 简单拼接。大语言模型(LLM)的成功推动了VLA研究的第二波浪潮,强调知识先验和大规模缩放。通过继承预训练视觉-语言模型的权重,这些代理利用互联网级数据实现复杂推理和语义理解。该方法论上呈现两个并行动作生成分支:自回归标记化(将动作视为离散语言令牌)和扩散合成(附加生成动作专家以产生连续、多模态动作分布)。VLA的定义最近扩展到包含更丰富的具身体观测(如3D几何、深度感知、力或触觉反馈),但核心仍局限于反应式映射,未捕获底层世界动态。
3.2 World Models / 世界模型
世界模型的核心共识是:它是建模环境动态和动作效果的内部表征,能预测动作后果从而实现仿真、决策和规划。根据条件模式的不同,可分为动作条件化世界模型和语言条件化世界模型。 3.2.1 Action-conditioned World Models / 动作条件化世界模型:描述环境如何在代理动作控制下演变。基于建模和预测环境动态的空间,可分为显式和隐式两类。显式像素级预测模型(如ACVP、CDNA)在像素空间操作;随着生成模型发展,自动回归视频世界模型和扩散视频世界模型成为主流。隐式潜在空间动态模型(如RSSM、TSSM)则学习紧凑潜在空间中的转移函数,通过预测性表征学习(如JEPA范式)进一步提升效率和泛化能力。 3.2.2 Language-conditioned World Models / 语言条件化世界模型:使用语言作为更抽象的条件信号,建模目标为 P(o' | o, l)。语言条件化视频基础模型是最突出的实现,从大规模视频-文本对中学习丰富的对象、场景和物理交互先验。技术从早期GAN基础模型(如MoCoGAN)演进到扩散模型(基于U-Net、ViT/DiT),再到闭源高性能模型(如Sora 2、Veo 3)。 3.2.3 Embodied World Model / 具身世界模型:专门针对具身环境进行建模。许多工作致力于从互联网未标记视频中学习物理动态,或通过架构设计和数据驱动方法提升零样本生成、视频-指令对齐、多视角一致性和物理感知能力。
3.3 World Model for VLA / 用于VLA的世界模型
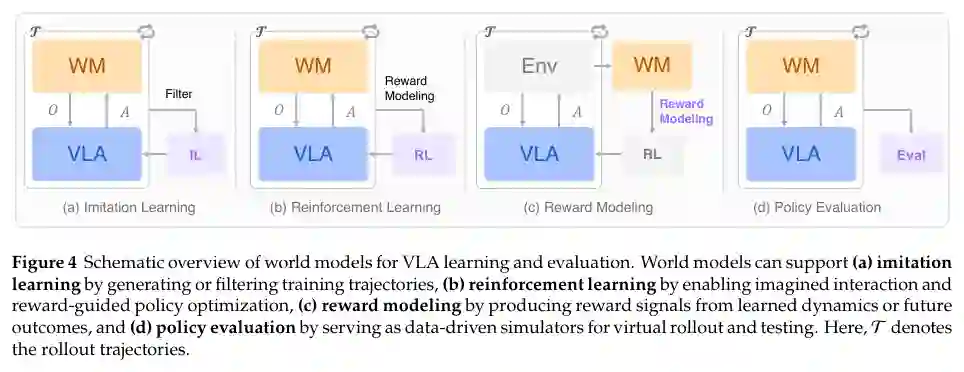
世界模型从两个互补视角增强VLA:学习和评估。 3.3.1 World Models for Learning / 用于学习的世界模型:在模仿学习中,世界模型生成多样化训练数据;在强化学习中,世界模型可充当替代环境或用于奖励建模,直接基于生成表征推导奖励信号。 3.3.2 World Models for Evaluation / 用于评估的世界模型:通过从数据中学习环境动态,世界模型构建数据驱动的模拟环境,减少对昂贵物理评估的依赖,弥合sim-to-real差距,并支持大规模、可重复的策略测试。
4 Architecture / 架构
基于结构流程和训练范式,WAMs可分为两大架构类别。
4.1 Cascaded World-Action-Model / 级联世界行动模型
级联WAM通过顺序的两阶段流水线实现世界-动作映射:世界模型先合成预测未来的视觉规划(如像素、潜在或流空间),再由独立动作模型解码可执行命令。 4.1.1 Explicit Planning via Pixel-Space Representations / 通过像素空间表征的显式规划:使用原始像素帧作为中间表征。动作提取方式分为两类:学习型动作提取(如UniPi使用逆动力学模型IDM)和几何动作提取(如AVDC通过光流计算SE(3)变换)。 4.1.2 Implicit Planning via Latent Representations / 通过潜在表征的隐式规划:采用紧凑潜在序列代替显式未来帧作为中间规划载体,降低像素级生成的巨大计算开销。
4.2 Joint World-Action-Model / 联合世界行动模型
联合WAM将预测状态建模和动作生成统一到单个连贯模型中,同时产生未来状态和动作。世界建模和动作生成在统一目标下进行联合训练,迫使模型内化环境动态与运动控制信号之间的因果相互依赖关系。 4.2.1 Joint Prediction via Autoregressive Generation / 通过自回归生成的联合预测:如GR1、WorldVLA等模型,在单一架构中同时预测下一个观测和动作,通过统一的序列建模目标进行训练。 4.2.2 Joint Prediction via Diffusion-based Generation / 通过扩散生成的联合预测:如PAD、CosmosPolicy等模型,利用扩散模型强大的分布建模能力,在去噪过程中联合推理未来观测和动作。
5 Training data / 训练数据
5.1 Robot-Centric Teleoperation Data / 机器人中心遥操作数据
这是WAMs最直接的训练数据源,包含真实机器人动作和对应观测。关键研究重点包括通过多形态装备、多样化环境和自动数据增强来规模化数据;以及通过多模态感知和接触丰富信息深化感知能力。代表性数据集包括OXE、DROID、AgiBot World等。
5.2 Portable Human Demonstration Data (UMI-style) / 便携式人类演示数据(UMI风格)
UMI系统使用手持式夹具进行人类演示数据采集,无需机器人硬件即可大规模获取。这种数据源具有高度的可移植性和可扩展性,但对配准和动作标注精度有较高要求。
5.3 Simulation Data / 仿真数据
仿真数据提供低成本、可重复、自动标注的大规模训练数据。研究方向包括通过程序化生成和环境复杂性提升来规模化;时空动态方面,3D和4D具身建模使得更复杂的物理交互成为可能;接触丰富物理方面,高保真触觉监督(如DexMimicGen)进一步提升仿真数据的真实感。
5.4 Human and Ego-Centric Data / 人类和第一人称数据
从互联网规模的第一人称视频中学习被动世界建模,获取丰富的动作语义和视觉动态。为弥合与机器人动作之间的鸿沟,采用姿态估计和本体感觉接地技术。这类数据来源是WAMs实现通用预训练混合的关键组成部分。
6 Evaluation / 评估
6.1 How to Evaluate World Modeling Capability? / 如何评估世界建模能力?
评估围绕三个维度组织:
- 视觉保真度 使用PSNR、SSIM、LPIPS、FVD等指标评估生成预测的视觉质量。
- 物理常识 通过VideoPhy、PhyGenBench等基准评估模型对物理规律的理解(如重力、刚性、交互合理性)。
- 动作合理性 通过WorldSimBench等基准评估生成的动作序列是否符合实际环境和任务要求。
6.2 How to evaluate Action Policy? / 如何评估动作策略?
评估策略性能的基准包括:
- 通用操作基准 MetaWorld、RLBench、LIBERO等。
- 双臂和人形基准 RoboMimic、HumanoidBench等。
- 移动操作基准 ManipulaTHOR、HomeRobot等。
- 接触和变形操作基准 SoftGym、PlasticineLab等。
- 真实机器人基准 RoboArena、Maniparena等。
7 Open challenges and Opportunities / 开放挑战与机遇
尽管WAMs取得了显著进展,但领域仍然面临多方面关键挑战:
- 数据稀缺与多样性:高质量、全覆盖的具身动作标注数据仍显不足,不同数据源间的迁移和融合仍是难题。
- 物理一致性与可泛化性:模型在长距离预测中容易出现语义漂移和累积误差,对复杂物理交互的建模还不够鲁棒。
- 计算效率:特别是基于显式规划的像素级生成和扩散模型,推理时计算开销极大,限制了实时部署能力。
- 统一评估框架:目前的评估协议碎片化,缺乏统一全面的WAMs能力评估标准,尤其在物理常识和动作合理性方面。
- 安全与可靠性:在开放世界中,如何确保模型在面对分布外情景时保持稳定、安全的操作行为,是部署前必须解决的关键问题。
8 Conclusions / 结论
本文作为首篇系统综述,对World Action Models领域进行了全面梳理。我们提供了正式定义、架构分类、数据生态分析和评估协议综述,阐明了关键架构范式及其权衡。级联WAM通过解耦世界建模和动作执行来利用强大的预训练模型,但可能面临累积误差和行动规划不协调的挑战;联合WAM通过紧密耦合实现更好的物理推理,但在计算效率和可扩展性方面提出更高要求。我们识别了开放挑战和未来方向,为进入该领域的研究者提供了概念框架和实践指南。随着数据源的不断丰富、架构范式的持续演进以及评估协议的日趋完善,WAMs有望成为具身AI领域一个强大而统一的解决方案。
