
导读
检索增强生成(RAG)在多跳问答中面临一个典型的“先有鸡还是先有蛋”问题:为了检索第二跳证据,模型需要先知道桥接实体;但桥接实体往往并没有出现在原始问题中,而是在推理过程中才逐渐浮现。传统静态 RAG 只用问题检索一次,容易漏掉后续证据;自回归模型虽然可以边生成边检索,却只能利用已经从左到右提交的前缀,查询信号出现得较晚,并且错误可能沿前缀累积。 ICML 2026 论文 Self-Augmenting Retrieval for Diffusion Language Models 提出 SARDI,一种面向离散扩散语言模型的动态检索框架。它利用扩散模型每轮去噪时对整个答案所有位置给出的暂定预测,把尚未稳定、甚至低置信度的“未来 token”提前用作检索线索,再用新证据继续去噪。其关键设计是把检索查询阈值与生成提交阈值分开:一个 token 可以先参与检索,却不必立即写入答案。 这项工作的意义不止是给扩散语言模型外挂一个 RAG 模块。作者揭示了扩散解码与检索之间的双向协同:一方面,中间去噪轨迹提供自回归模型难以获得的全局前瞻信号;另一方面,检索证据又显著降低相邻 token 之间的条件依赖,使并行解码更容易。五个多跳问答基准显示,SARDI 在训练免费检索方法中建立了更优的质量-延迟前沿,吞吐量最高可提升 8 倍。
论文基本信息
论文题目:Self-Augmenting Retrieval for Diffusion Language Models
中文题目:面向扩散语言模型的自增强检索
作者:Paul Jünger、Justin Lovelace、Linxi Zhao、Dongyoung Go、Kilian Q. Weinberger 作者单位:Cornell University 会议信息:ICML 2026,第 43 届国际机器学习大会,PMLR 306 研究方向:扩散语言模型、检索增强生成、多跳问答、并行解码、动态检索 代码地址:https://github.com/pauljngr/SARDI
摘要
离散扩散语言模型通过反复去噪整个响应来并行生成文本。每一步中,模型都会为所有被遮蔽位置预测暂定 token,只把高置信度预测提交到输出,而丢弃低置信度预测。本文发现,这些通常被丢弃的 token 实际上是检索增强生成中很有价值的前瞻信号:即使置信度不高,它们也常常会在去噪早期暴露关键实体,从而帮助系统在答案最终确定之前检索到更强的证据。 作者据此提出 SARDI,即扩散语言模型的自增强检索框架。SARDI 在去噪过程中动态使用这些前瞻 token 构造查询,并持续刷新外部证据。该检索机制不需要专门训练检索控制器,对稀疏或稠密检索器均适用,也可以接入任何能够产生推理轨迹的离散扩散语言模型。 在五个多跳问答基准上,SARDI 超过当前训练免费的扩散与自回归检索基线,同时实现最高 8 倍吞吐提升。分析进一步表明,中间扩散状态能够更早发现桥接实体,而高质量检索证据会显著降低 token 间依赖,使 RAG 成为特别适合并行扩散解码的应用场景。
引言:多跳 RAG 的桥接实体难题
静态检索为什么不够
经典 RAG 通常在生成开始前,用用户问题执行一次检索,然后在整个回答过程中固定使用这批文档。对于单跳事实问题,这种方式往往足够;但多跳问答所需的后续证据经常依赖中间推理结果,而原始问题没有直接给出关键桥接实体。 例如,问题“陈列《蒙娜丽莎》的博物馆位于哪个城市?”首先需要找到“《蒙娜丽莎》陈列于卢浮宫”,再以“卢浮宫”为桥接实体检索“卢浮宫位于巴黎”。只用原始问题进行静态检索,第一跳证据容易找到,第二跳证据却缺乏明确查询词。
自回归动态检索的局限
已有自回归动态 RAG 会在生成期间反复检索。IRCoT 等方法利用已生成的推理前缀继续查询;FLARE 先暂时生成下一段文本,再用其中的低置信度跨度触发检索;ReAct、AdaptiveRAG 和 Search-R1 则通过显式搜索动作、路由器或强化学习生成查询。 这些方法缓解了静态检索问题,但仍受自回归结构限制。模型只能从左到右看到已提交前缀,未来位置的信息尚不存在。即使 FLARE 暂时向前生成一句话,其候选跨度仍按自回归顺序产生,一个早期错误可能继续污染后面的 token,最终形成幻觉查询。代理式检索还能引入额外规划、训练和推理开销。
扩散模型提供了新的检索接口
离散扩散语言模型不是一次生成一个 token,而是从全遮蔽序列开始,在每轮去噪中同时预测多个位置。即使某些位置尚未达到提交要求,模型也已经对答案后部的实体、日期和关系形成暂定判断。 这意味着扩散模型可以“偷看”自己的未来答案。中间状态不必作为最终文本可信,却可以作为具有噪声容忍度的检索查询。错误 token 一旦直接提交会损坏答案,但把少量错误词放进检索查询通常不会造成同等严重后果,因为检索器可以依赖问题本身及其他正确实体维持鲁棒性。这种不对称性是 SARDI 的出发点。
背景:自回归与离散扩散解码
自回归语言模型
自回归模型把答案概率分解为从左到右的条件概率,每个位置依赖此前已经生成的前缀。检索系统因此也只能使用问题与已提交文本构造查询。它的优点是生成顺序清晰、局部一致性强,缺点是延迟随输出长度线性增长,而且第二跳线索只有在前缀真正生成后才能使用。
离散扩散语言模型
离散扩散语言模型定义从全 [MASK] 状态到完整答案的一系列去噪状态。每一步,去噪器对所有仍被遮蔽的位置给出词表分布,并选择一部分位置解除遮蔽。多个位置可以并行提交,因此测试时延由去噪轮数而非答案 token 数直接决定。 并行预测也会带来一致性挑战。如果相邻位置强依赖,独立选择各自最高概率 token 可能拼出不一致的实体,例如一处预测“Albert”,另一处预测“Curie”。作者提出,RAG 恰好能缓解这一问题:当实体和事实已经出现在检索文档中,多个输出位置可以分别从证据复制或改写,彼此之间不再需要进行强协调。
方法:SARDI 自增强检索
总体流程
SARDI 把去噪与检索交错执行。系统从全遮蔽答案和问题的初始检索结果开始。每轮去噪时,模型为所有遮蔽位置预测 token 及其置信度,然后基于两个不同阈值执行两种操作:
- 用于检索:置信度达到查询阈值 τq 的候选 token 被加入查询。
- 提交生成:只有置信度达到提交阈值 τc 的 token 才真正解除遮蔽,写入下一状态。
核心约束是 τq ≤ τc。于是,一个暂定预测可以在还不足以成为答案时,先成为检索器的前瞻信号。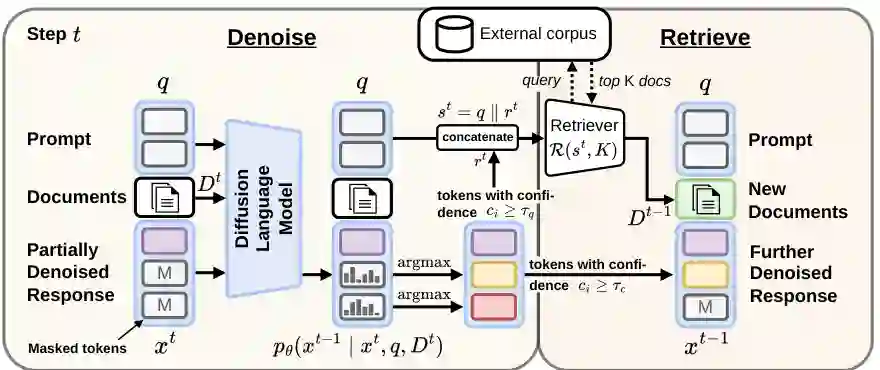
查询构造
设当前去噪状态为 x_t。模型对每个遮蔽位置 i 计算最高 token 概率 c_i。构造代理序列时,已经提交的 token 原样保留;尚未提交但 c_i ≥ τq 的位置填入当前 argmax 预测;其余位置继续保持遮蔽。去掉剩余 [MASK] 后,得到中间响应 r_t,再与原始问题 q 拼接成查询 s_t。 原始问题始终保留在查询中,起到稳定锚点作用。当早期预测包含噪声时,检索仍然知道用户究竟在问什么;随着去噪推进,中间响应逐步加入桥接实体和关系,让查询越来越具体。 论文默认使用 τq=0,即让每个位置的当前最佳预测都参与查询,获得最大前瞻范围。这个设定乍看激进,却与检索和生成对错误的不同容忍度相符,后续阈值实验也验证了它的有效性。
证据刷新
每轮根据 s_t 从外部语料库检索 K 篇新文档,并完整替换上一轮上下文。下一轮去噪由问题、当前答案状态和新文档共同条件化。论文主实验采用 BM25,每轮取 K=7,但方法本身不依赖特定检索器;换成 E5-base-v2 稠密检索器后仍保持优势。 每轮完全刷新看似昂贵,但附录分析发现,相邻检索轮之间平均有 83% 至 90% 文档保持不变。这个现象意味着实际系统可通过文档编码缓存、增量更新或降低刷新频率摊薄成本。
基于置信度的解除遮蔽
提交阶段采用阈值式解除遮蔽:所有 c_i ≥ τc 的位置在同一轮并行写入;如果没有位置达到阈值,则强制提交当前最有把握的位置,保证算法持续推进。 这一机制形成自然课程。已经有充分证据支持的高置信度片段先被固定,并参与下一轮查询;不确定片段等待更强证据后再提交。τc 同时控制两个因素:每轮并行生成多少 token,以及检索被细化多少轮。 较高 τc 意味着更谨慎地提交,去噪与检索轮数更多,通常准确率更高但速度较慢;较低 τc 则一次提交更多位置,吞吐量更高但准确率下降。一个参数即可连续调节质量-速度折中。
完整算法
SARDI 的执行过程可以概括为:
- 将答案初始化为全
[MASK]序列。 - 只用问题执行初始检索。
- 对所有遮蔽位置并行预测 token 与置信度。
- 提交超过 τc 的位置;若没有,则提交置信度最高的位置。
- 用超过 τq 的暂定 token 构造代理响应,并与问题拼接。
- 使用新查询刷新 K 篇证据。
- 重复去噪和检索,直到答案完全解除遮蔽。
与需要学习查询策略的搜索代理不同,SARDI 没有额外检索控制器、奖励设计或策略优化。只要离散扩散模型能够输出有意义的推理轨迹,就可直接接入。
实验设置
数据集与指标
作者在五个多跳问答基准上评估:
- 2WikiMultihopQA:基于维基百科的组合与桥接型多跳问题。
- HotpotQA:提供细粒度维基百科语料和多文档推理问题。
- MuSiQue:强调可组合、多步骤推理。
- CofCA:使用反事实、虚构事实语料,降低预训练数据泄漏影响。
- SynthWorlds-RM:同样使用合成事实测试检索与推理能力。
主要准确率指标是 Exact Match(EM),延迟以单张 NVIDIA B200 上每个样本的平均墙钟时间计算。主实验使用 BM25 和 K=7,并补充稠密检索器实验。
模型与公平比较
扩散主干采用 DREAM-7B,自回归对照采用 Qwen2.5-7B。一个容易误读的细节是,SARDI 的检索机制是 training-free,但当前基础 DREAM-7B 无法仅靠提示稳定输出结构化推理轨迹。作者因此从 GPT-4o-mini 合成的思维链轨迹中进行轻量监督微调,并对 DREAM-7B 与 Qwen2.5-7B 使用完全相同的微调数据。 微调后,两种模型在静态 K=7 RAG 下的能力接近:DREAM-7B 达到 43.7 EM,Qwen2.5-7B 达到 44.5 EM。这样,动态检索阶段的差异更能归因于检索机制,而不是基础模型能力或训练数据不同。
比较基线
训练免费自回归基线包括静态检索、每 10 个 token 检索、每个 token 检索、FLARE 式自适应检索、AdaptiveRAG 和 ReAct;扩散基线是 DREAM-7B 的静态检索。论文还列出经过强化学习训练的 Search-R1 作为强参考,但明确指出它与 SARDI 处于不同设计点:前者投入额外训练换取查询策略,后者追求即插即用和低延迟。
实验结果
五个基准的主结果
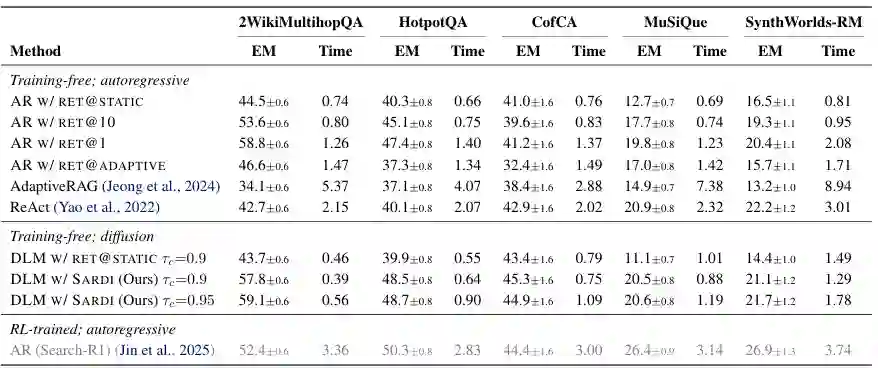
- 2WikiMultihopQA 从 43.7 提升至最高 59.1 EM。
- HotpotQA 从 39.9 提升至最高 48.7 EM。
- CofCA 从 43.4 提升至约 45 EM。
- MuSiQue 从 11.1 提升至约 20.6 EM。
- SynthWorlds-RM 从 14.4 提升至最高 21.7 EM。
在 τc=0.9 时,SARDI 在 2Wiki 上达到 57.8 EM,单样本仅需 0.39 秒;自回归每 token 检索虽然有 58.8 EM,却需要 1.26 秒。HotpotQA 上 SARDI 达到 48.5 EM、0.64 秒,也优于多数训练免费基线。 Search-R1 在 MuSiQue 和 SynthWorlds-RM 上凭借强化学习查询策略获得更高准确率,但推理时间约为 3 秒以上。对于 2Wiki、HotpotQA 和 CofCA,SARDI 在相近准确率下比 Search-R1 快约 3 至 8 倍。论文并未把两者描述为互斥方案,而是指出扩散前瞻轨迹未来也可以结合轻量查询监督。
质量与吞吐量前沿
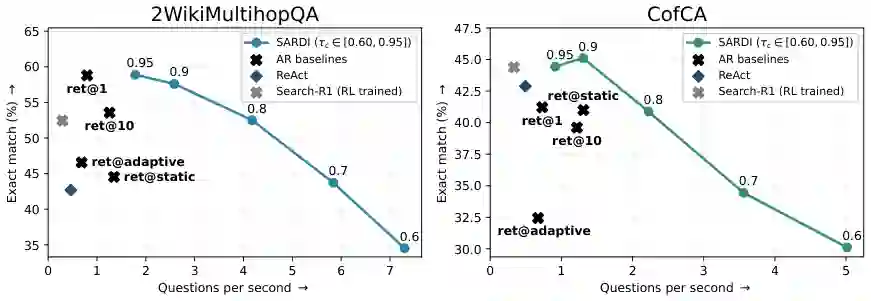
低置信度前瞻 token 确实有用
查询阈值 τq 决定候选 token 多可靠时才能进入检索查询。若 τq=τc,查询几乎只看到即将提交的 token,前瞻能力有限;若 τq 接近 0,所有位置的当前最佳预测都可提供检索线索。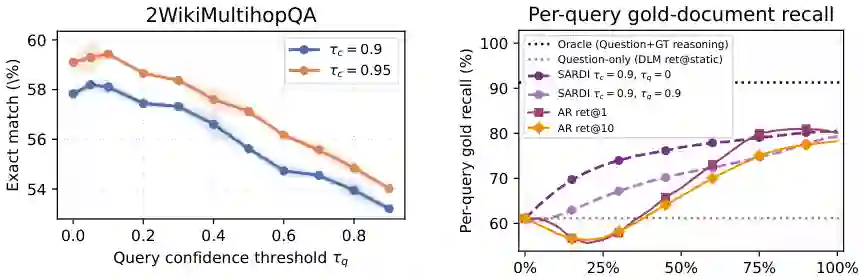
RAG 为什么促进并行解码
作者使用条件互信息(CMI)衡量推理轨迹中相邻 token 的依赖。实体名是最典型的强耦合跨度:如果模型不知道正在生成 Albert Einstein 还是 Isaac Newton,相邻 token 必须协调;一处选择变化会显著改变另一处的分布。
检索器与刷新频率消融
将 BM25 替换为 E5-base-v2 稠密检索器后,SARDI 在五个数据集上仍超过最强训练免费自回归基线,并与 Search-R1 保持竞争力,说明方法不依赖词法检索器的特殊性质。 每轮刷新检索并非绝对必要。改为每 2 个去噪步骤刷新一次,2Wiki 和 HotpotQA 只损失 1 至 2 EM,CofCA 与 MuSiQue 基本不变;每 4 步刷新时下降更明显。结合相邻轮次 83% 至 90% 文档保持不变的观察,部署时可以通过稀疏刷新与缓存减少文档编码开销。 附录还比较固定 50 步解码与阈值式解除遮蔽。τc=0.9 或 0.95 在相近甚至更高 EM 下实现约 2 至 3 倍速度提升,证明阈值策略比固定步数更能适应样本难度。
局限性
第一,检索机制虽然无需专门训练,但当前被测试的扩散模型还不能可靠地仅靠提示生成推理轨迹。论文实验需要轻量监督微调,这限制了“即插即用”在现阶段基础模型上的直接程度。作者预期随着 DLM 能力成熟,这一步会像早期自回归模型的思维链能力一样逐渐不再必要。 第二,SARDI 默认每个去噪步骤都刷新检索。若使用大型语料库、昂贵重排序器或复杂稠密编码器,朴素实现会产生额外文档编码成本。论文的文档持久性与刷新消融表明缓存和增量检索很有潜力,但尚未形成完整工程方案。 第三,本文聚焦能够显式生成推理轨迹的离散扩散语言模型。如何推广到潜空间扩散语言模型,以及如何在没有可读中间 token 的情况下构造检索前瞻信号,仍是开放问题。 第四,主任务是开放域多跳问答。代码生成、长文事实写作、工具调用和多模态知识检索是否同样受益,需要后续验证。这些任务的查询粒度、证据持久性和错误成本可能与问答不同。
结论与启发
SARDI 的核心创新可以概括为一句话:不要丢掉扩散模型尚未提交的预测,把它们当作寻找证据的草稿。
这项工作利用了检索与生成对错误的不同敏感度。低置信度 token 不适合直接写进答案,却可以作为容错查询的一部分;新证据反过来提高后续 token 的置信度,并降低实体跨度之间的依赖。检索与去噪由此形成自增强闭环。 从更广的角度看,SARDI 展示了非自回归语言模型不只是“更快地生成相同文本”。其全局中间状态本身是一种新的系统接口,可用于检索、验证、规划和工具选择。未来若扩散语言模型进一步成熟,这类基于生成轨迹的动态外部交互,可能成为它们区别于自回归模型的真正结构优势。
原文信息
论文题目:Self-Augmenting Retrieval for Diffusion Language Models 作者:Paul Jünger、Justin Lovelace、Linxi Zhao、Dongyoung Go、Kilian Q. Weinberger 论文链接:https://arxiv.org/abs/2606.06474 PDF:https://arxiv.org/pdf/2606.06474 代码:https://github.com/pauljngr/SARDI