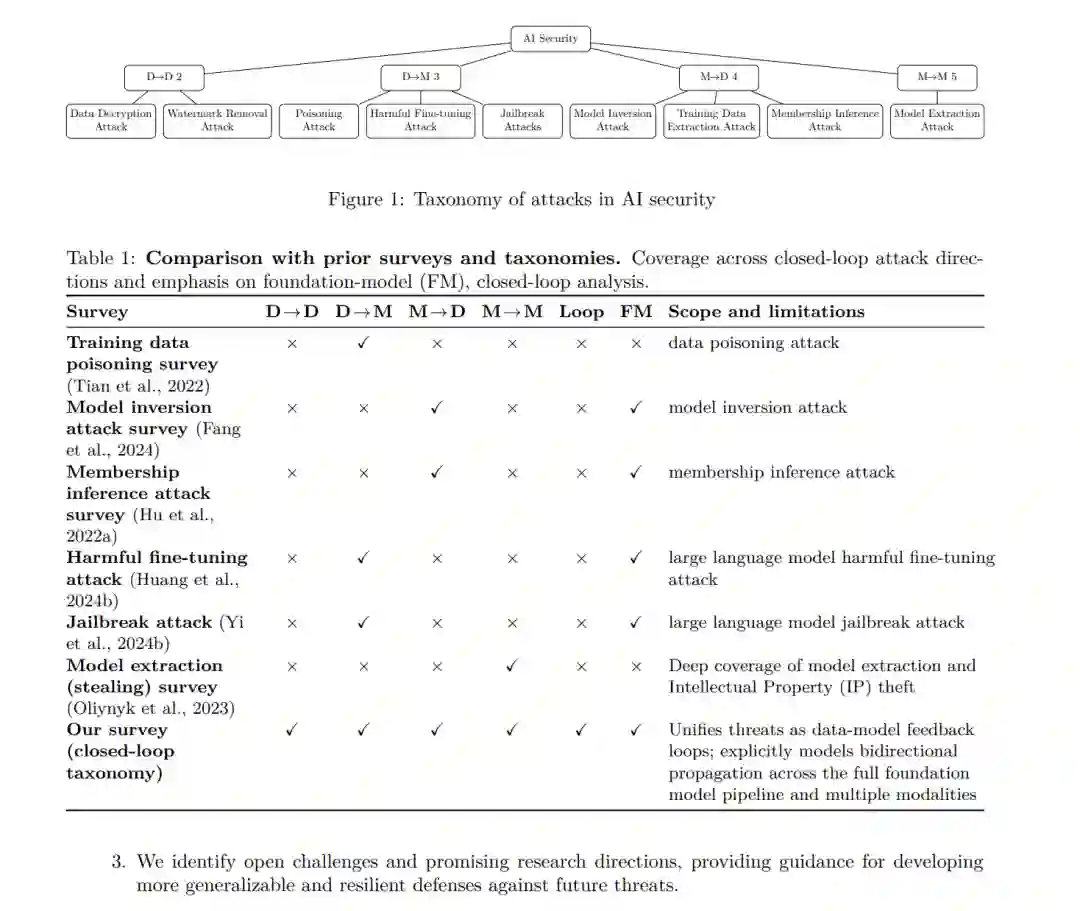
摘要: 随着机器学习(ML)系统在规模与功能维度的持续扩张,安全格局愈发复杂,攻击手段与防御机制均呈现激增态势。然而,现有研究多将此类威胁视为孤立事件,缺乏一套连贯的框架以揭示其内在共性与相互依赖关系。这种碎片化的视角不仅阻碍了对安全问题的系统性认知,亦限制了综合性防御方案的设计。关键在于,ML 的两大核心资产——数据与模型——已不再彼此独立,其一存在的脆弱性将直接威胁另一方的安全。由于缺乏全局性视角,双向风险如何在 ML 流水线中演化传播仍是亟待解决的课题。 为填补这一空白,本文提出了一个统一的闭环威胁分类体系(Unified Closed-loop Threat Taxonomy),通过四个定向维度明确构建了模型与数据的交互逻辑。该框架为基座模型的安全性分析与防御提供了严谨的理论视角。基于此,我们将安全威胁划分为四个既互有区别又紧密关联的类别: 1. 数据→数据 (D→D): 包括数据解密攻击与水印去除攻击; 1. 数据→模型 (D→M): 包括中毒攻击(Poisoning)、有害微调攻击及越狱攻击; 1. 模型→数据 (M→D): 包括模型逆向攻击、成员推理攻击及训练数据提取攻击; 1. 模型→模型 (M→M): 包括模型提取攻击。
本文进行了系统性的综述,深入分析了上述威胁的数学形式化表达、攻防策略,以及在视觉、语言、音频和图领域的研究现状。这一统一框架阐明了各类安全威胁间的底层联系,为开发可扩展、可迁移且跨模态的安全策略奠定了基础,尤其在基座模型研究背景下具有重要意义。
1 引言
机器学习(ML)的发展不仅带来了功能更强、用途更广的系统,也演化出日益复杂的安全格局。从中毒攻击、规避攻击到提取和推理攻击,各种威胁层出不穷,与之对应的防御策略也大量涌现。尽管这些研究推动了领域进步,但它们通常被孤立地审视,侧重于特定场景下的技术细节,而非揭示其背后的底层共性。这种“烟囱式”的处理方式分散了我们对对抗行为的系统性认知,增加了推导各项攻击间关联性的难度,并阻碍了开发能够跨多元攻击面持续有效的防御机制。在实践中,面对加速扩张的机器学习漏洞,研究人员和从业者都缺乏一个连贯的框架来指引方向。 这种复杂性的根源在于机器学习的两大核心基石——数据与模型——之间存在深度的相互依赖。数据完整性受损可能导致模型失稳或崩溃,而模型本身的脆弱性则可能泄露隐私数据或将错误向下游传播。然而,现有的综述研究鲜有捕捉到这种相互影响,也未能阐明风险如何在端到端的机器学习流水线中循环。在基座模型(Foundation Models)背景下,这一缺口尤为迫切,因为基座模型支撑着广泛的应用,任何安全违规行为的后果都会被放大。为应对这一挑战,本文提出了一个统一的闭环威胁分类体系,沿数据(D)与模型(M)之间的四个定向流向刻画安全动态:数据→数据(D→D)、数据→模型(D→M)、模型→数据(M→D)以及模型→模型(M→M),如图 1 所示。 上述四类安全威胁代表了既有区别又相互关联的攻击范畴: 1. D→D: 涵盖直接操纵或恢复数据内容的攻击。数据解密攻击试图在无私钥的情况下恢复明文信息;水印去除攻击旨在消除嵌入的出处或所有权标识。 1. D→M: 中毒攻击与有害微调攻击通过向训练流水线注入恶意样本,诱导模型产生特定的异常行为;越狱攻击则通过构造对抗性输入绕过安全机制,使模型无视策略约束并执行非预期行为。 1. M→D: 模型逆向、成员推理及训练数据提取攻击通过模型输出或表征重建敏感训练内容,或推断特定数据是否属于训练集。 1. M→M: 模型提取攻击通过有限的模型查询来复制受产权保护的模型。
这些相互依赖关系并非偶然,而是构成了一个动态影响链。其中,单一组件(数据或模型)的受损可以递归地将漏洞传播至整个机器学习流水线。本研究对现有文献进行了全面综述,详细阐述了其数学形式化表达、攻防方法论,以及在视觉、语言、音频和图结构数据中的应用。它们共同构成了数据与模型交互的闭环。 尽管每种威胁类别对应一类特定的攻击,但这些攻击之间深度互联,且往往以非平凡(non-trivial)的方式相互影响。一方面,某些攻击会放大其他攻击的效果。例如,数据中毒(D→M)能显著提升模型对成员推理(M→D)的脆弱性(Chen et al., 2022; Wen et al., 2024b)。同样,Carlini et al. (2021) 表明训练数据提取可以简化为成员推理问题,进一步强化了这些威胁类别间的实际联系。成功的模型提取(M→M)不仅能辅助下游的训练数据恢复和模型逆向(M→D)(Tramèr et al., 2016),还可用于合成对抗样本(D→D)(Papernot et al., 2017)。另一方面,攻击之间也可能产生干扰或削弱。例如,Wang et al. (2025) 证明引入后门攻击(D→M)会降低后续模型提取(M→M)的有效性,这表明跨阶段的攻击交互并不总是累加的。这些实例共同说明,安全威胁不应被孤立分析,而应被视为紧密耦合且动态变化的闭环系统中的组成部分。 由于这些威胁具有级联效应,将每种攻击视为独立事件已不足以应对挑战。相反,这促使我们建立一个能捕捉数据与模型全反馈回路的全局框架。这种闭环视角对于设计鲁棒、可扩展且跨模态的防御方案至关重要,尤其是在基座模型时代,数据与模型的界限已深度交织且日益模糊。 为了突出本研究在现有文献中未涵盖的独特范围与视角,我们在表 1 中提供了与过往综述的详尽对比。现有综述通常孤立地关注单一攻击类别,缺乏全局或闭环视角,因此未能系统地刻画不同安全威胁间的相互依赖性,或漏洞在学习流水线各阶段间的传播方式。相比之下,本综述覆盖了数据与模型交互攻击的所有四个类别,提供了一个统一的全局视角,揭示了基座模型中不同攻击面如何互联并相互影响。 本文的主要贡献总结如下:
提供了一项全面的综述,统一了所有四种数据-模型攻击方向,为跨攻击面的内在联系提供了全局视角。 1. 在一个闭环框架内对代表性攻防手段进行了系统分类与分析,突出了其共同原理、差异及新兴模式。
论文结构安排: 第 2 节介绍 D→D 威胁及防御;第 3 节综述 D→M(中毒、有害微调及越狱)攻防;第 4 节探讨 M→D 威胁(模型逆向、成员推理、数据提取);第 5 节评述 M→M 攻击(无数据、基于数据、功能及架构克隆);第 6 节对比攻击与防御的交互及依赖关系;第 7 节讨论 AI 安全的其他正交视角;第 8 节探讨开放挑战与未来方向;第 9 节进行实证评估;第 10 节总结全文。