摘要 (Abstract) — 激光雷达 (LiDAR) 传感器通常被认为是自动驾驶中不可或缺的核心组件。然而,高分辨率传感器依然造价昂贵,而成本较低的低分辨率传感器产生的点云数据往往过于稀疏,从而缺失关键细节。激光雷达超分辨率技术通过深度学习增强稀疏点云,缩小了不同类型传感器之间的性能差距,并为实际部署中的跨传感器兼容性提供了可能。 本文对自动驾驶领域中的激光雷达超分辨率方法进行了首次全面综述。尽管实际应用部署极具重要性,但目前尚未有系统性的评述。我们将现有的方法归纳为四类:基于 CNN 的架构、基于模型的深度展开、隐式表示方法,以及基于 Transformer 和 Mamba 的方法。此外,我们确立了基本概念体系,包括数据表示、问题定义、基准数据集及评价指标。当前的研究趋势包括采用高效的距离图像 (Range Image) 表示形式、极端模型压缩以及可变分辨率架构的开发。近期的研究重点倾向于面向实际部署的实时推理与跨传感器泛化能力。最后,我们指出了推动激光雷达超分辨率技术发展的现有挑战与未来研究方向。 索引词 (Index Terms) — 激光雷达超分辨率,自动驾驶,跨传感器差距
I. 引言 (INTRODUCTION)
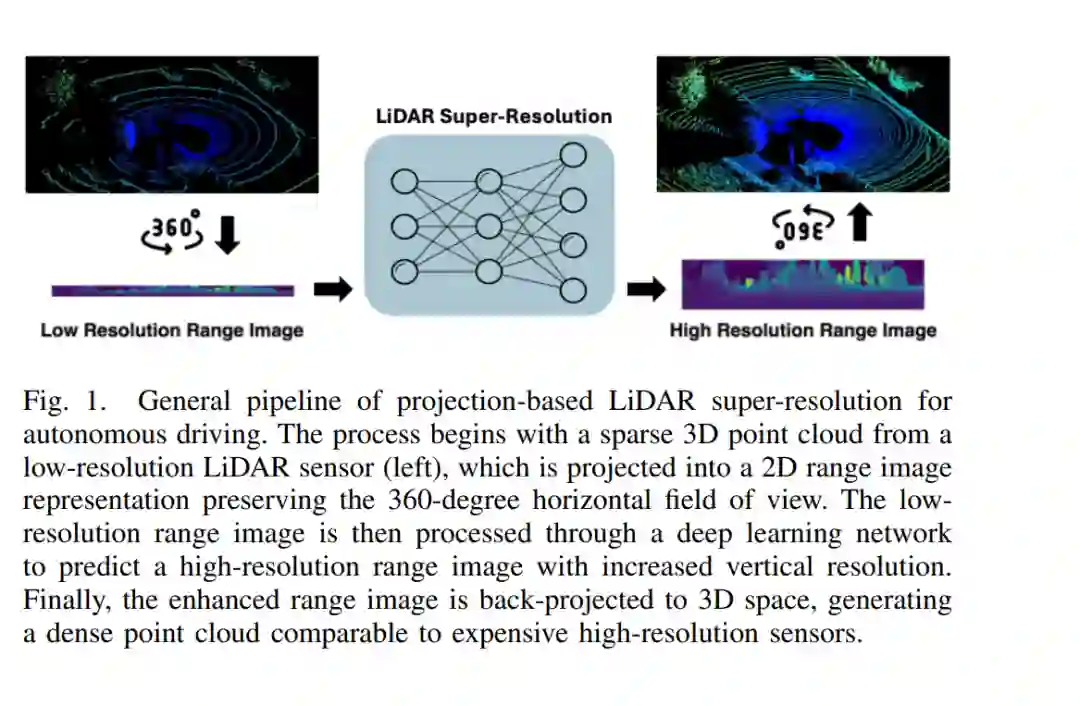
激光雷达 (LiDAR) 传感器是自动驾驶系统中不可或缺的组件,能够提供精确的环境 3D 信息。本文的讨论仅限于最常见的车载激光雷达类别,即利用多线旋转激光束进行定位,以最大化水平视场角 (FoV),从而实现避障与导航。然而,具有 64 线或 128 线的红外高分辨率激光雷达传感器的成本显著高于低分辨率传感器 [1]。由于价格因素限制了其在消费级车辆中的普及,大多数制造商转而选择更经济的 16 线或 32 线传感器 [2]。这些低分辨率传感器生成的点云较为稀疏,在涉及安全导航的关键细节上提供的回波数据较少。 激光雷达超分辨率 (SR) 技术为这一问题提供了解决方案。该技术利用深度学习提高稀疏点云的密度,旨在使低成本传感器达到高价传感器的性能表现。通过在降低传感器成本的同时维持安全标准,该技术有望推动自动驾驶汽车的广泛部署 [3]。图 1 展示了这一能力,说明了现代超分辨率方法如何将稀疏(低分辨率 LiDAR)点云转换为高密度(高分辨率 LiDAR)质量的点云。 与图像超分辨率相比,激光雷达超分辨率面临着特有的挑战。首先,大多数方法将任务明确设定为在保持水平分辨率的同时增强纵向分辨率。其次,车载激光雷达通常具备 360 度的水平视场角。第三,激光雷达在物体边界处表现出剧烈的深度变化,汽车、建筑和行人会导致深度值出现突变。第四,自动驾驶要求实时处理能力,模型运行速度必须至少达到 25 fps,以匹配传感器的帧率 [4]。第五,点云具有稀疏性和不规则性。与具有均匀像素网格的图像不同,激光雷达点在 3D 空间中分布不均。第六,基于激光雷达模型的下游任务受困于严重的“分辨率依赖型领域鸿沟 (Resolution-dependent domain gaps)”。虽然在图像领域 [5] 高分辨率数据上训练的模型通常能在低分辨率下保持合理的性能,但 3D 物体检测模型在面对分辨率变化时表现出显著的性能退化 [6]。 早期的激光雷达超分辨率方法多借鉴 2D 图像超分辨率技术,将 LiDAR 数据视为深度图(即距离图像)进行处理。虽然这种方法较为简便,但往往忽略了 3D 点云的几何特性 [7]。传统的几何方法 [8] 通过插值和几何分析来增加点云密度,而无需进行数据训练。本综述重点关注基于深度学习的超分辨率方法,即通过学习从低分辨率输入中重建高分辨率模式。 近期的研究开始引入激光雷达传感器的领域知识。例如,采用循环填充 (Circular Padding) 处理 360 度全景视图 [9, 10],利用极坐标系减少误差 [11],以及保持 3D 结构特征 [12, 13]。基于模型的方法利用物理传感器模型来引导学习过程 [14, 15];隐式表示方法学习可在任意分辨率下工作的连续函数 [16];Transformer 架构用于捕捉距离图像中的长距离依赖关系 [3, 9];而 Mamba 架构则利用选择性状态空间建模 (Selective State-space Modeling) 来高效提取局部与全局上下文信息 [13, 17]。 本文提供了关于自动驾驶领域中基于深度学习的激光雷达超分辨率技术的首次全面综述。我们将现有方法分为以下四类: * 基于 CNN 的架构:涵盖从早期到先进的设计(第三节) * 基于模型的深度展开与联邦学习方法(第四节) * 隐式表示方法(第五节) * 基于 Transformer 与 Mamba 的方法(第六节)
此外,第二节介绍了基本概念、基准数据集和评价指标;第七节则进行了对比分析,并指出了当前的局限性与未来的研究方向。