
导读
当大语言模型进入真实业务、公共服务和高风险决策场景后,“模型已经训练好”并不意味着“模型行为已经可控”。训练阶段的对齐、RLHF、红队测试和安全微调固然重要,但部署之后仍会遇到持续变化的风险:新的越狱提示、检索内容污染、组织内部策略更新、不同地区的合规要求、用户个性化约束,以及多轮交互中逐渐累积的上下文偏移。对这些问题,重新训练模型往往成本高、周期长,也不一定可行。 这篇综述 Inference-Time Control for Trustworthy Large Language Models 正是围绕这个问题展开:如何在推理阶段,也就是模型已经训练完成、正在生成回答时,对其行为进行可信控制?作者把 2020-2026 年间 230 余篇相关论文整合为一个“推理时控制平面”,并从安全、隐私、公平、事实性四个可信维度出发,梳理七类方法:上下文工程、护栏、解码策略、表示工程、推理时遗忘、结构剪枝和多智能体系统。 本文的价值不只是列方法清单,而是把这些方法放回同一条生成流水线中理解:有些方法在输入和上下文阶段施加约束,有些方法直接改写 token 分布,有些方法干预隐藏状态或模型结构,还有一些方法通过多智能体协作和验证来提升可靠性。换句话说,可信 LLM 不再只是“训练一个更安全的模型”,而是在运行时搭建一套可更新、可组合、可审计的治理机制。 对研究者而言,这篇综述给出了可信 LLM 运行时治理的完整地图;对工程团队而言,它回答了一个非常实际的问题:当模型已经上线,面对不断变化的风险和场景时,我们还有哪些不改参数、少改参数或系统级的控制手段可用。
Paper Information / 论文基本信息
英文题目 Inference-Time Control for Trustworthy Large Language Models 中文题目 面向可信大语言模型的推理时控制 作者 Yuyang Bai, Zheyuan Liu, Han Yan, Zhangchen Xu, Yixin Wan, Canyu Chen, Zehong Wang, Xiangchi Yuan, Yue Huang, Guangyao Dou, Yuji Zhang, Hangxiao Zhu, Zhuofeng Li, Manling Li, Xiangliang Zhang, Mohit Bansal, Sanmi Koyejo, Kai-Wei Chang, Yu Zhang, Meng Jiang 机构 Texas A&M University、University of Notre Dame、University of Washington、UCLA、Northwestern University、Georgia Tech、Johns Hopkins University、UIUC、UNC Chapel Hill、Stanford University 等 预印本信息 Preprints, May 2026 DOI 10.20944/preprints202605.1041.v1 项目页 https://leopoldwhite.github.io/Awesome-Inference-Time-Trustworthiness/ 论文链接 https://www.preprints.org/manuscript/202605.1041/v1
Introduction / 引言
论文的出发点是一个部署现实:训练时对齐无法预见所有运行时风险。一个 LLM 在发布之后,可能面对持续变化的政策约束、不同用户或组织的偏好、带有污染或偏见的检索上下文、恶意构造的越狱提示,以及对隐私与事实性的不同要求。此时,如果每次都依赖重新训练或再次微调,不仅成本高,而且滞后。 推理时控制方法因此成为可信 LLM 的关键补充。它们不一定改变模型参数,而是在生成管线中实时调节输入、上下文、输出检查、token 分布、隐藏表征、结构组件或多智能体交互。作者将这些方法视为同一个控制平面:它们作用位置不同、访问权限不同、风险覆盖不同,但共同目标是在模型运行时提高安全性、隐私保护、公平性和事实性。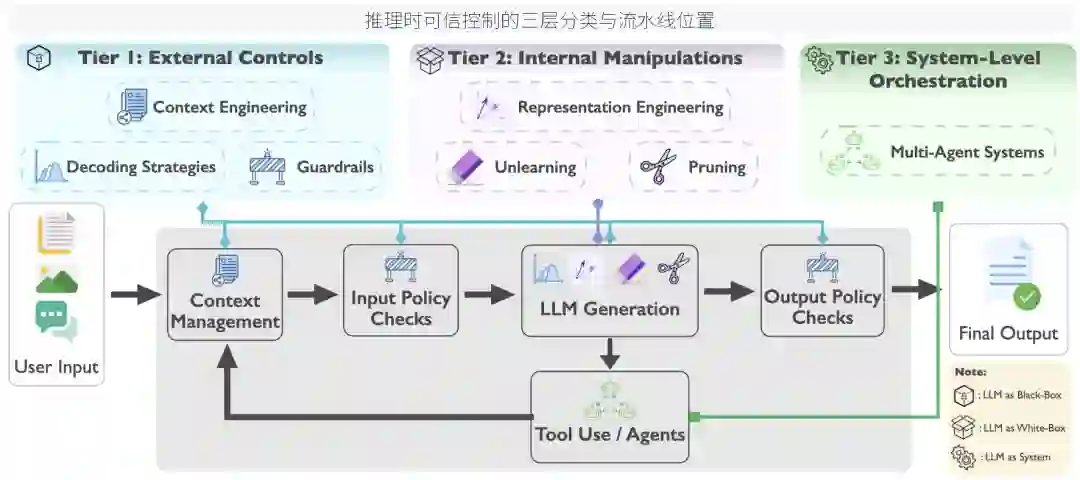
综述的核心问题
这篇论文试图回答三个问题。第一,推理时可信控制到底包括哪些方法,而不仅是通常被单独讨论的 prompt engineering 或 guardrail?第二,不同方法在生成流水线中分别接入哪里,需要黑盒、白盒还是系统级访问?第三,如何在安全、隐私、公平和事实性之间建立统一的评估视角,而不是每个方向各说各话。 作者的贡献可以概括为四点:提出一个跨方法的三层分类法;把七类方法和四个可信维度系统对应起来;给出元轴评估框架;讨论推理时控制在鲁棒性、效用、验证和组合方面的开放挑战。
Tier 1: External Controls / 第一层:外部控制
外部控制把 LLM 当作黑盒来使用。它们不访问模型权重,也不修改隐藏状态,而是通过上下文、输入输出检查和解码过程来影响模型行为。正因为不依赖白盒访问,这一层最容易部署在商业 API 模型上,也是当前工程实践中最常见的可信控制方式。
上下文工程
上下文工程通过提示词、系统指令、示例、检索内容、记忆窗口和上下文排序来约束模型行为。它可以用于安全,例如在系统提示中明确禁止危险操作;也可以用于事实性,例如通过 RAG 给模型提供可引用证据;还可以用于隐私和公平,例如在输入层过滤敏感字段、加入公平性约束或引入不同群体的平衡示例。 这类方法的优势是低成本、可解释、可快速迭代,缺点是容易被上下文污染或对抗提示绕过。特别是在长上下文和多轮交互中,约束可能被稀释、覆盖或被模型忽略,因此上下文工程往往需要与护栏和输出验证结合使用。
护栏机制
护栏是外部控制中最典型的一类。它通过额外模块对输入或输出进行检查,对违规内容进行阻断、重写、脱敏或重新生成。论文将护栏机制分为四类:规则型护栏、小模型分类器、基于 LLM 的评审器,以及混合防御流水线。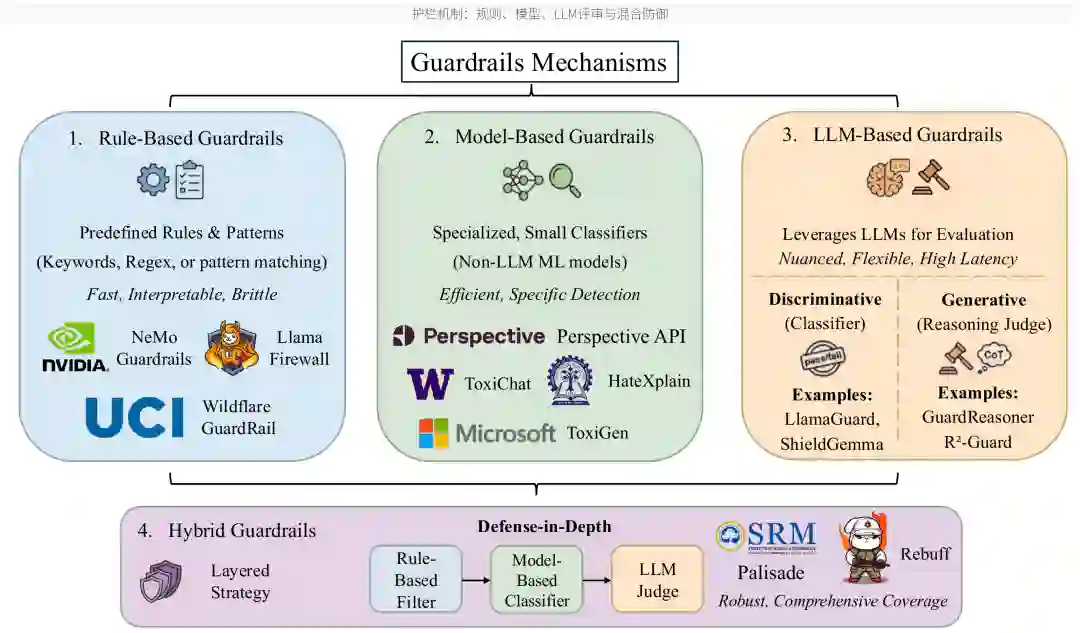
解码策略
解码策略在 token 生成阶段直接操控概率分布。与护栏不同,它不是等模型生成完再检查,而是在生成过程中重加权、抑制或引导候选 token。论文把解码策略放在外部控制层,是因为很多方法只需要访问输出概率或通过 API 近似实现,不一定修改模型参数。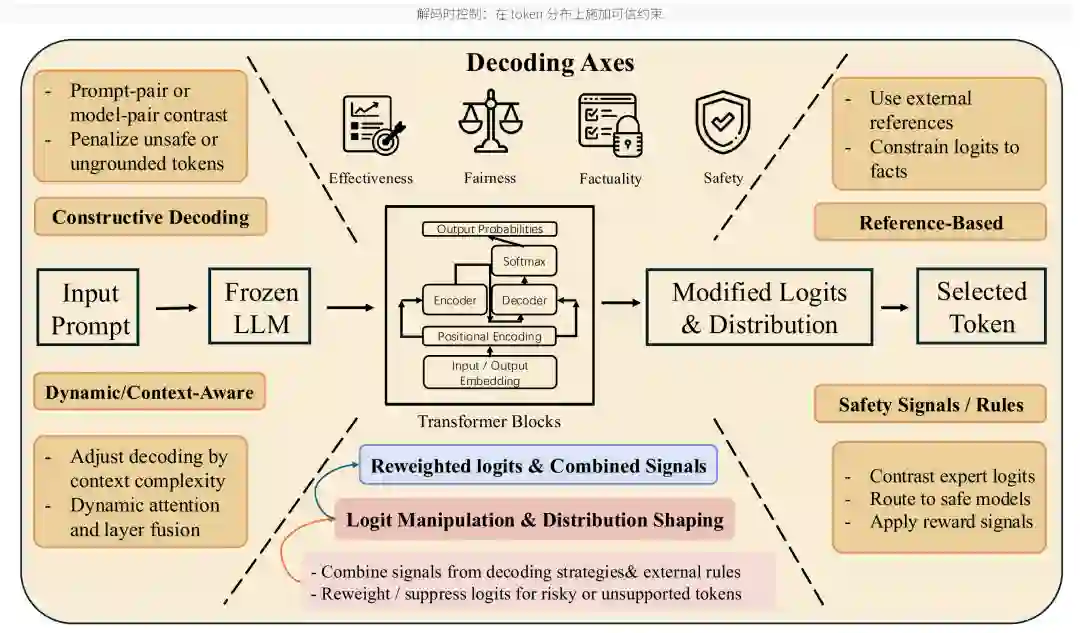
外部控制的部署取舍
从工程角度看,外部控制通常是第一优先级。原因很简单:它不要求模型开源,不需要重新训练,可以快速适配新的政策和业务规则。如果一个企业正在使用 API 模型,最可行的路径往往是先建立上下文模板、输入输出护栏、检索证据校验和解码约束,再逐步引入更复杂的白盒方法。 但外部控制也不应被神化。上下文工程容易受到提示注入影响,护栏容易在边界案例中误判,解码策略可能牺牲自然度和召回率。因此论文把它们称为“最模块化、最可部署,但也最容易被适应性攻击绕过”的层级。实际落地时,外部控制更适合作为前置和后置防线,而不是唯一防线。
Tier 2: Internal Manipulations / 第二层:内部操控
第二层方法需要白盒访问。它们直接干预模型计算过程,例如修改隐藏状态、抑制特定知识或行为、剪除相关神经元或注意力头。与外部控制相比,内部操控更细粒度、更贴近模型内部机制,但部署门槛更高,也更难验证。
表示工程
表示工程把模型隐藏状态看作可控对象。常见做法是先找到某个概念方向,例如“有害性”“诚实性”“拒答倾向”“政治偏见”等,再在推理时沿该方向移动激活向量,从而改变输出行为。这类方法的吸引力在于,它提供了一种不改权重但能改变行为的方式。 在可信性维度上,表示工程可以用于安全控制、降低偏见、增强事实性或减少幻觉。例如,如果某些激活方向与不安全回答相关,可以在生成时压制这些方向;如果某些方向与基于证据回答相关,可以增强它们。但问题也很明显:概念方向是否稳定、是否跨任务泛化、是否会引入副作用,目前仍缺少可靠保证。
推理时遗忘
推理时遗忘关注在生成阶段抑制某些知识、行为或记忆,而不是通过重新训练真正删除它们。方法包括注意力遮蔽、激活门控、上下文拒答触发、检索屏蔽等。它适用于隐私场景,例如防止模型泄露训练数据中的敏感信息;也适用于安全场景,例如拒绝输出特定危险知识。 这类方法的重要挑战是“抑制不等于删除”。模型可能在常规提示下拒答,但在对抗提示、长链推理或间接诱导下重新泄露。因此推理时遗忘必须与验证机制结合,不能仅凭表面拒答判断信息已经被移除。
结构剪枝
结构剪枝通过删除或屏蔽权重、神经元、注意力头等组件来削弱不可信行为。它可以被视为推理时或部署时的结构性控制:不一定重新训练完整模型,而是通过移除局部结构来改变行为。 剪枝的潜在优势是推理效率和安全控制可以同时改善,例如移除与特定有害行为相关的组件;但风险在于模型能力可能被意外损伤,且行为归因并不总是清晰。一个神经元或注意力头可能同时承载多个功能,剪除后既可能降低风险,也可能破坏正常能力。
内部操控的共同难题
内部操控比外部控制更深入,但也带来更强的验证问题。我们如何证明某个激活方向真的对应目标概念?如何保证推理时遗忘不会被恢复?如何测量剪枝造成的隐性能力损失?论文认为,这一层的未来不只在于找到更强干预方法,更在于建立可验证、可审计、可复现的机制分析。
白盒方法的适用边界
内部操控更适合开源模型、私有部署模型或具备深度模型访问权限的研究场景。它的优势在于可以干预更靠近生成机制的变量,不必完全依赖提示或外部过滤。例如,在高敏感场景中,如果某些风险模式频繁绕过输出护栏,表示工程或推理时遗忘可以作为更深一层的控制手段。 不过,白盒方法对组织能力要求更高。团队需要理解模型结构、激活接口、推理框架和评估协议,还需要承担维护不同模型版本的成本。一旦模型升级,原来的方向向量、剪枝位置或遗忘触发机制可能失效。因此白盒控制并不是“更高级就一定更好”,它适合风险足够高、模型可控性要求足够强、并且团队有能力持续验证的场景。
Tier 3: System-Level Orchestration / 第三层:系统级编排
第三层把可信性视为系统交互的结果,而不是单一模型的内在属性。多智能体系统通过角色分工、辩论、交叉验证、红队攻击、自我反思和工具调用,把一个模型的输出放入更大的工作流中进行检查和改进。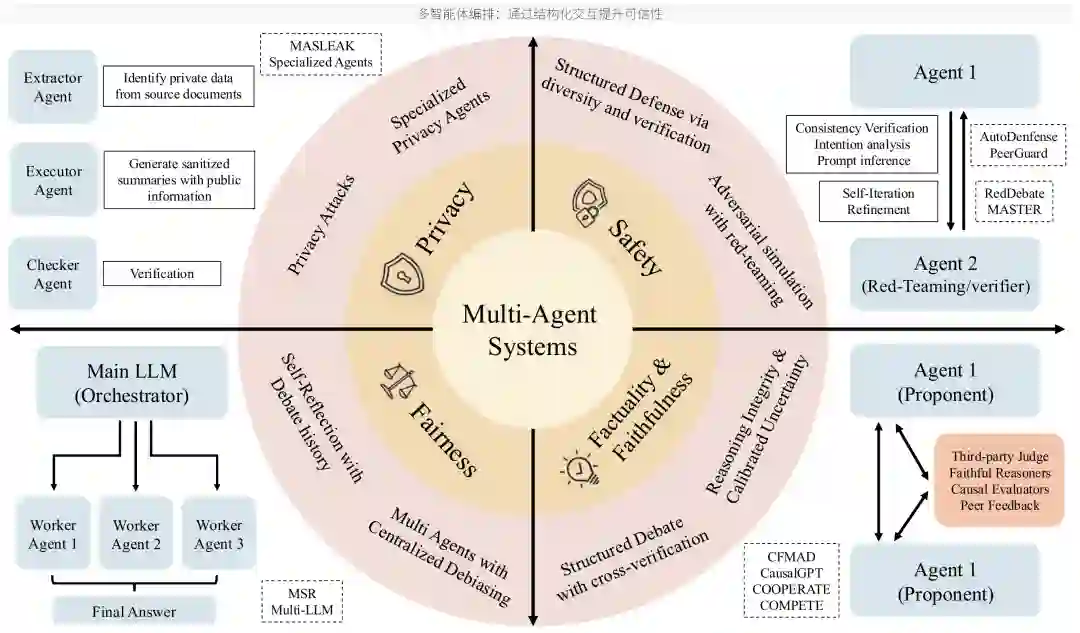
面向安全的多智能体
安全场景中,多智能体系统常把攻击者、防御者、验证者和裁判分开。红队智能体负责生成对抗提示,防御智能体负责拒绝或重写,验证者负责检查是否违反策略。通过角色多样性,系统可以发现单一模型难以识别的隐性风险。 这种方法的优势是动态、可迭代,并能模拟对抗过程;缺点是系统复杂度高,且智能体之间可能出现串联错误。如果红队提示被其他智能体误采纳,或者裁判模型被同样的攻击模式误导,系统反而可能放大风险。
面向事实性和公平性的协作
在事实性任务中,多智能体常用于交叉验证、证据检查、观点竞争和不确定性校准。一个智能体提出答案,另一个智能体检索证据或寻找反例,第三个智能体进行裁判。这种结构可以降低单模型幻觉,但前提是不同智能体具有足够独立性。 在公平性任务中,多智能体可以模拟不同群体视角或让专门的审查智能体检查偏见。系统还可以把输出交给多个角色进行一致性评估,避免单一评审模型把自身偏差当作标准。
面向隐私的角色分工
隐私保护中,多智能体可以把“提取”“执行”“检查”分离。例如一个智能体识别敏感字段,另一个智能体生成脱敏摘要,第三个智能体验证输出中是否仍包含私人信息。这种分工能提高可审计性,但也增加了中间状态泄露和权限边界管理的复杂度。
系统级编排的价值
系统级编排最适合复杂任务,而不是简单问答。只要任务涉及多步检索、多源证据、合规审查、外部工具、长期记忆或多人协作,单次模型调用就很难保证可信性。把不同角色拆开,可以让每个智能体承担相对清晰的职责,也方便记录中间证据和审查链路。 但系统级方案也有新的风险。多个智能体并不天然带来正确性;如果它们使用相同模型、相同偏差和相同上下文,所谓“辩论”可能只是重复同一种错误。更糟的是,攻击者可以利用智能体之间的通信通道传播恶意指令。因此,多智能体可信系统需要明确权限边界、消息过滤、独立证据源和最终裁决机制。
Evaluation / 评估框架
推理时控制方法非常异质:有的改 prompt,有的改 logits,有的改激活,有的加过滤器,有的组织多个智能体。因此,单一 benchmark 或单一指标无法覆盖所有方法。论文提出一个元轴评估框架,将四个可信维度与五个评估轴组合起来。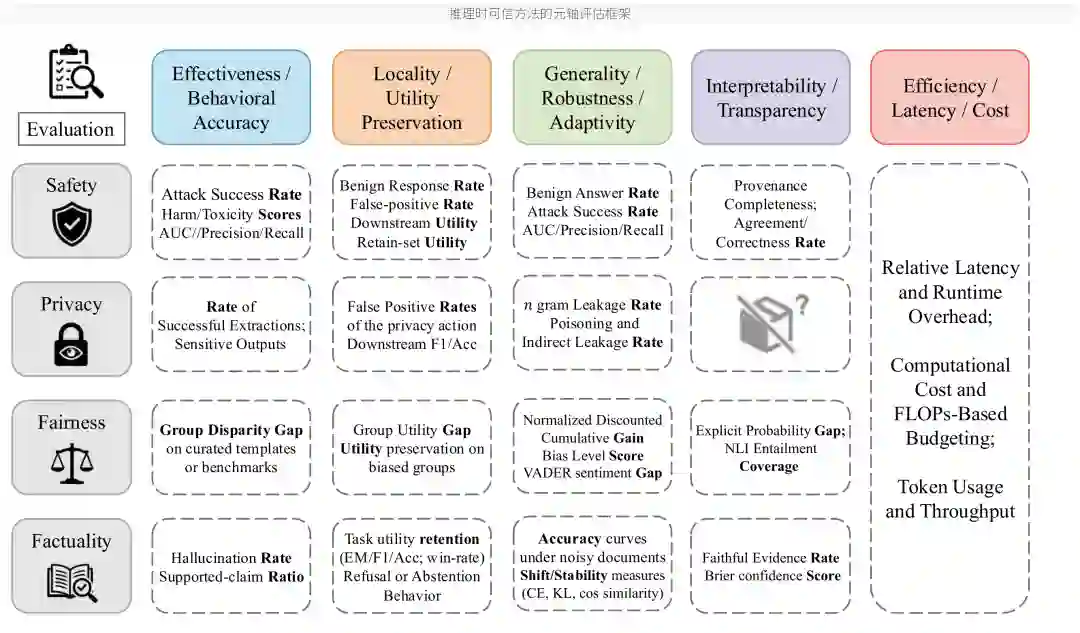
四个可信维度
安全关注模型是否减少有害、毒性、越狱或危险内容。常见指标包括攻击成功率、有害分数、毒性分数、AUC、Precision、Recall 等。隐私关注模型是否泄露敏感信息,指标包括成功提取率、敏感输出率、n-gram 泄露率、间接泄露率等。 公平关注不同群体上的输出差异,例如群体差距、偏见水平、情感差距或模板化测试中的不平等表现。事实性关注幻觉率、支持声明比例、证据一致性、置信校准和嘈杂文档下的稳定性。
五个评估轴
有效性衡量控制是否真的降低风险或提高目标行为。局部性衡量控制是否只影响目标行为,而不破坏正常任务能力。泛化性衡量方法能否应对新攻击、新场景和分布转移。可解释性衡量决策依据是否可追踪、是否能提供出处和一致性说明。效率衡量延迟、计算成本、token 使用量和吞吐。 这套框架的重要性在于,它提醒我们不能只报告“风险下降”。一个护栏如果让攻击成功率下降,但误伤大量正常请求,仍然不可用;一个解码策略如果降低幻觉,却使生成延迟翻倍,也需要在部署场景中重新权衡。
为什么需要元轴评估
可信性评估最容易出现的误区,是把一个方向上的改善误认为整体可靠。例如,一个安全护栏可以显著降低越狱成功率,但如果它频繁拦截正常医学、法律或教育问题,用户体验和任务效用会迅速下降。又比如,一个事实性增强方法可以降低幻觉,但如果只在单一检索数据集上有效,面对噪声文档或对抗证据时仍可能失败。 元轴评估的好处是把这些问题显式化。每个方法都要回答五个问题:它是否有效?是否只影响目标风险?是否能泛化到新场景?是否能解释自己的判断?成本是否可接受?这比单一 leaderboard 更接近真实部署需求,也能帮助团队选择适合自身场景的控制组合。
Related Work / 相关工作
已有综述通常按可信风险类型、单一方法家族或效率问题来组织文献。例如,有些综述专注安全和越狱,有些专注隐私泄露,有些专注模型遗忘、剪枝或推理效率。本文的不同之处在于,它把“推理时”作为统一视角,把黑盒、白盒和系统级方法放在一个控制平面中比较。 论文还强调,推理时控制不是训练时对齐的替代品,而是部署后的补充层。训练时对齐提供基础行为边界,推理时控制则提供动态更新、场景适配和风险响应能力。在高风险应用中,两者需要组合,而不是二选一。
Open Challenges / 开放挑战
自适应对手下的脆弱性
静态护栏和固定解码约束容易被自适应攻击绕过。攻击者可以通过重写、分步诱导、角色扮演、工具调用或多轮上下文污染来绕开规则。表示工程和推理时遗忘也可能被对抗探测逆转。因此,未来需要动态评估、持续红队和会随威胁模型更新的防御机制。
控制与效用的权衡
更严格的控制通常会降低有用性、流畅性或任务准确率。一个真正可部署的可信系统,需要显式展示信任-效用 Pareto 曲线,而不是只报告某个单点结果。特别是在医疗、法律、教育、金融等场景中,拒答过度与风险放行同样会造成问题。
移除验证仍然困难
对于遗忘、剪枝和编辑类方法,最难的问题是证明目标信息真的不可恢复。模型可能只是学会在常规提示下不说,而不是从内部表示中删除相关信息。缺少形式化或强经验保证,会阻碍隐私敏感和监管场景中的部署。
组合风险尚未被理解
实际系统往往会同时使用提示约束、RAG、护栏、解码控制、输出审核和多智能体验证。不同控制层之间可能互相增强,也可能互相干扰。例如,一个护栏的重写可能破坏检索证据,多个智能体辩论可能放大幻觉或形成群体一致性错误。如何组合、排序、验证这些控制,是下一阶段的重要问题。
评估标准需要统一
当前各方向指标分散,安全、隐私、公平和事实性往往在不同 benchmark 上评估,难以比较。论文提出的元轴框架是重要一步,但未来仍需要跨场景、跨风险、跨成本的统一评估协议,并且要覆盖真实部署中的多轮交互和动态攻击。
Takeaways / 核心启发
这篇综述带来的第一点启发是:可信 LLM 的治理重心正在从“只训练一个更安全的模型”转向“训练时对齐 + 推理时控制 + 系统级监控”的组合范式。模型参数只是可信性的基础,运行时控制才是面对变化环境的现实接口。 第二点启发是:不同控制方法对应不同访问权限。黑盒 API 场景更依赖上下文工程、护栏和解码策略;开源模型场景可以进一步使用表示工程、遗忘和剪枝;复杂业务系统则需要多智能体和工具链编排。因此,选择方法时首先要明确部署约束,而不是只看论文指标。 第三点启发是:可信性必须与效用、成本和可解释性一起评估。一个控制方法如果安全但不可用、有效但不可解释、强大但延迟过高,都难以进入真实系统。未来可信 LLM 的关键不只是“更强防御”,而是可验证、可组合、可稳定运行的控制体系。
对工程团队的落地建议
如果把论文中的分类法转化为工程路线,可以采用由浅入深的三步策略。第一步,先建立黑盒层控制:统一系统提示、上下文来源管理、输入输出护栏、日志记录和失败回退机制。这一步成本最低,却能覆盖大量常见风险。 第二步,在可访问模型内部的场景中引入白盒控制:对高风险能力做表示探针,测试激活 steering 是否有效,评估推理时遗忘和剪枝是否真的降低泄露或不安全行为。此时最重要的不是单点效果,而是副作用分析和恢复攻击测试。 第三步,为复杂任务建立系统级工作流:让检索、生成、审查、事实核验和合规裁决分别由不同模块或智能体承担,并设计清晰的权限与审计链路。最终目标不是堆叠尽可能多的控制模块,而是让每一层控制都有明确作用、可测指标和失效处理方案。
对研究者的启发
对研究者来说,这篇综述也指出了若干值得深入的问题。推理时控制究竟能在多大程度上替代训练时对齐?不同控制层之间是否存在可形式化的组合规律?表示工程、遗忘和剪枝能否获得可验证保证?多智能体系统中的“独立性”如何定义和衡量?这些问题的答案,将决定可信 LLM 是停留在经验工程,还是逐步走向可证明、可审计的系统科学。
Original Information / 原文信息
本文精读基于以下原文与项目页:
- 论文题目:Inference-Time Control for Trustworthy Large Language Models
- 预印本:Preprints, May 2026
- DOI:10.20944/preprints202605.1041.v1
- 项目页:https://leopoldwhite.github.io/Awesome-Inference-Time-Trustworthiness/
- 论文链接:https://www.preprints.org/manuscript/202605.1041/v1
- 代码与论文列表:https://github.com/leopoldwhite/Awesome-Inference-Time-Trustworthiness
