
多模态情感识别(Multimodal Emotion Recognition, MER)试图让模型从图像、视频、语音、文本乃至会话上下文中识别和解释人的情绪。相比一般视觉问答或语音识别,MER 更接近真实人类交互:情绪并不只写在文字里,也可能藏在表情、语调、动作、场景和多轮对话中。随着大语言模型和多模态大模型快速发展,MER 正在从“小规模、任务特定模型”转向“以 LLM 为中心的统一情感理解范式”,论文称之为 MER-with-LLMs。
这篇综述《Multimodal Emotion Recognition with Large Language Models》聚焦的正是这个新范式。作者认为,LLM 带来了统一输入输出、指令跟随、自然语言解释和开放词汇情绪推理等机会,但也暴露出三类核心挑战:情感标注数据稀缺、多模态情感鸿沟、情感解释不透明。围绕这三类挑战,论文把已有研究组织成三条主线:情感数据增强、多模态情感表示、多模态情感推理。
下面严格按照原论文的组织结构展开。一级标题保留英文与中文对照,便于读者回到原文定位;三级及以下标题统一使用中文,不再保留英文斜杠。配图选择总览图、taxonomy 图、方法示意图和性能汇总表,均配中文图注并放在对应章节附近。
论文基本信息

Abstract / 摘要
论文指出,多模态情感识别关注从复合模态输入中识别和解释情绪,这一任务与真实环境中的人类认知过程高度相似,因此同时受到学术界和产业界关注。过去 MER 主要依赖小规模、任务特定模型;近期,一个新范式正在出现:借助大语言模型和多模态大模型来完成情绪理解。作者将其称为 MER-with-LLMs。 这一范式的优势在于通用性。LLM 可以把 MER 建模为以文本为中心的自回归过程,从多种模态输入中提取情感信息,并生成分类、解释、开放词汇描述或多轮对话响应。但新范式也带来新挑战:高质量情感标注数据难以获得;同一模态内部和不同模态之间存在情感鸿沟;模型给出的情感判断往往缺少透明解释。 为系统梳理已有研究并指导后续探索,论文根据现有工作主要应对的挑战,将方法分为三类:情感数据增强、多模态情感表示、多模态情感推理。综述进一步追踪各方向的发展趋势、代表方法和剩余问题,目标是为 MER-with-LLMs 提供清晰的学术地图。
1 Background and Challenges / 背景与挑战
情绪是人类日常体验的核心组成部分,会影响沟通、决策和行为。在现实环境中,情绪通常通过多种模态共同表达,例如语言内容、语音语调、面部表情、身体姿态和场景上下文。因此,MER 的目标并不是简单识别一个标签,而是让模型理解多模态输入中共同构成的情感状态。 传统 MER 方法多依赖小规模、任务特定模型。这类方法在固定数据集上可以取得不错表现,但通常绑定预定义输入域和输出空间,难以应对实际应用中的动态性和灵活性。例如,一个系统可能只处理面部表情,另一个系统只处理语音情绪;一旦输入模态、场景或标签体系变化,模型就需要重新设计或微调。 LLM 和 MLLM 为这一问题提供了新路径。通过指令跟随和生成式建模,MER 可以被转化为统一的语言生成过程:模型接收图像、视频、音频、文本和任务指令,然后生成情绪类别、解释、置信度或开放式描述。这不仅扩展了 MER 的输入输出形式,也把任务从“预测情绪标签”推进到“解释情绪判断”。
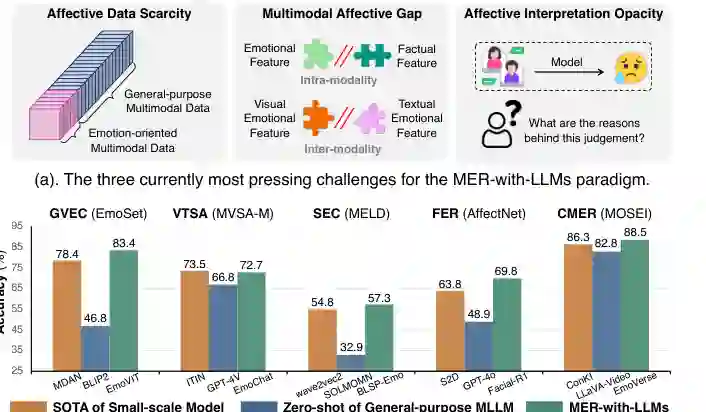
情感数据稀缺
现代大模型高度依赖数据,但情感数据很难大规模高质量标注。情绪具有主观性,同一个样本可能被不同标注者理解为不同情绪;可靠标注往往需要多人协作、冲突仲裁和情绪理论约定。不同数据集还可能采用不兼容的标签体系,例如离散情绪类别、情感维度、开放描述或复合标签,这进一步造成数据碎片化。
多模态情感鸿沟
情感鸿沟包括两个层面。其一是模态内鸿沟,即同一模态中的事实特征和情感特征并不完全一致。例如图像中的对象、场景和颜色不一定直接等价于情绪。其二是跨模态鸿沟,即不同模态的信息密度、表达方式和情绪线索并不一致。文本更紧凑抽象,图像更分散具象,语音还包含语调和节奏。模型需要理解这些异质线索,并处理它们之间可能存在的冲突。
情感解释不透明
传统 MER 主要输出情绪类别,缺少解释。用户可能想知道“为什么模型认为这个人是开心而不是尴尬”,研究者也需要通过解释发现模型是否依赖错误线索。LLM 的自然语言生成能力让可解释 MER 成为可能,但也带来新的可靠性问题:解释可能与预测不一致,甚至出现情感幻觉。
2 Problem Formulation and Taxonomy / 问题形式化与分类体系
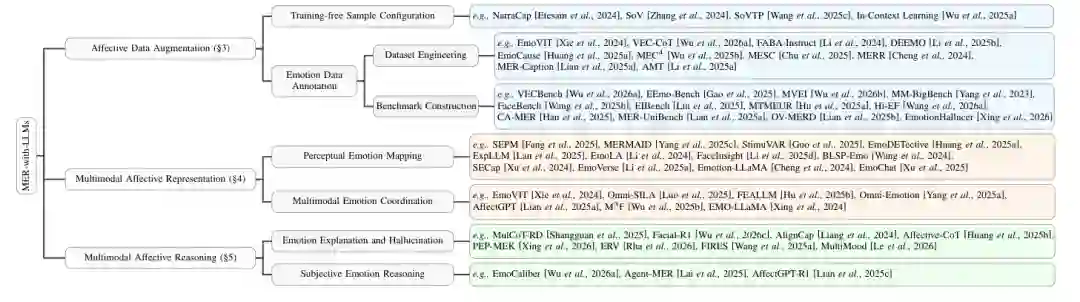
论文将 MER-with-LLMs 扩展为一个更广义的任务范式。在该范式中,LLM 扮演文本中心的编排器,处理来自多模态输入的情感信息。一个样本可以包含图像、视频、音频、文本,甚至脑电等生理信号;本文主要聚焦图像、视频、音频和文本,因为它们在现有研究中更常见。 从任务形式上看,模型接收多模态输入和文本指令,生成文本响应。响应可以是情绪类别,也可以是解释、开放词汇情绪描述、置信度表达或面向用户的支持性对话。论文进一步把 MER 子任务划分为五类:通用视觉情感理解、图文情感分析、语音情感理解、面部表情识别、会话式多模态情感识别。
五类主流子任务
通用视觉情感理解关注图像或视频对观察者激发的情绪反应,输入可能来自艺术作品、风景、电影或用户分享内容。图文情感分析主要处理社交媒体中的图像-文本组合。语音情感理解关注语音片段传递的情绪。面部表情识别关注人脸静态图像或动态视频中的表情线索。会话式多模态情感识别则进一步引入多轮对话、说话人状态和音视频上下文。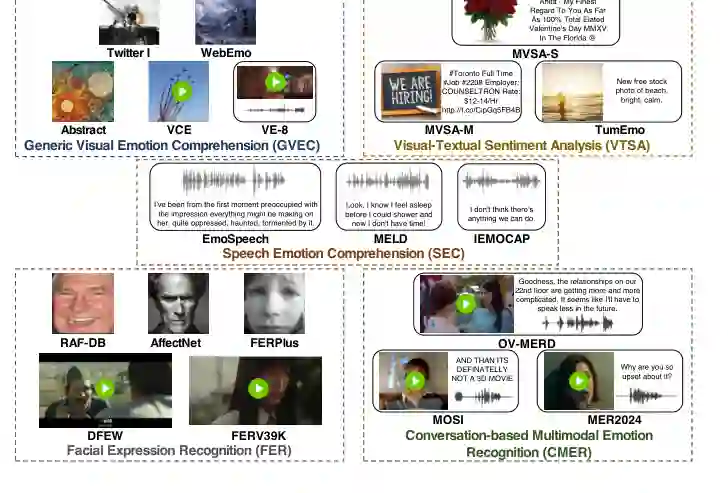
三条方法主线
围绕三大挑战,论文提出三条主线。情感数据增强用于缓解数据稀缺,既包括不改模型参数的样本配置,也包括面向训练和评估的数据构建。多模态情感表示用于缩小情感鸿沟,重点是让模型捕捉模态内部情感线索,并有效融合跨模态情绪信息。多模态情感推理用于提高解释透明度,推动模型从直接预测走向可解释、可校准和能够接纳主观性的推理。
3 Affective Data Augmentation / 情感数据增强
情感数据增强对应第一个挑战:高质量情感数据稀缺。论文将这一方向分为两类:免训练样本配置和情感数据标注。前者在不更新模型参数的情况下,最大化利用已有样本;后者通过构建训练数据集或评估基准,直接扩充可用情感数据资源。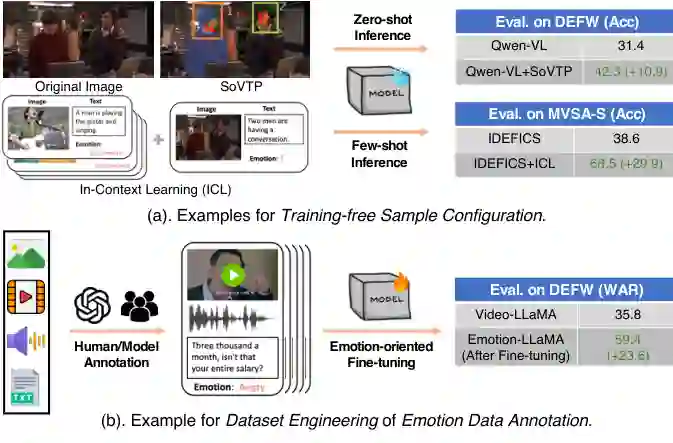
免训练样本配置
免训练样本配置强调在模型冻结的前提下,通过更好的输入组织来提升性能。例如,一些方法使用边界框、显著区域或上下文提示,帮助 MLLM 聚焦与情绪相关的局部区域;也有方法通过少样本上下文学习,把情绪感知相关示例放入提示中,降低模型对通用先验的依赖。这类方法成本低、部署灵活,尤其适用于没有额外标注数据或不能微调模型的场景。
情感数据标注
当允许引入额外数据时,更直接的路线是构建情感导向数据集。论文将其再分为数据集工程和基准构建。数据集工程服务于训练,例如为图像、视频、语音或会话构造情感指令微调数据,使 MLLM 在微调阶段学习更细粒度的情感线索。基准构建服务于评估,例如统一不同子任务的数据、设计更开放的情绪描述任务、引入情感冲突或幻觉诊断。
数据集工程
数据集工程覆盖多个子任务。对于通用视觉情感理解,EmoVIT、VEC-CoT 等方法构建情感中心的视觉指令数据或结构化情感推理数据。对于面部表情识别,FABA-Instruct、AMT 等方法引入动作单元、多任务场景和更细粒度标注。对于会话式 MER,DEEMO、EmoCause、MEC4、MESC、MERR、MER-Caption 等工作分别关注身份隐私、情绪原因、多语言、多属性和情感支持等方向。
基准构建
基准构建同样重要。没有统一基准,方法改进很容易只在单一数据集上成立。论文提到 VECBench、EEmo-Bench、MVEI、MM-BigBench、FaceBench、EIBench、Hi-EF、CA-MER、MER-UniBench、OV-MERD、EmotionHallucer 等评估资源。它们把评估从简单分类推进到情绪描述、开放词汇、冲突识别、未来情绪预测和幻觉诊断。
4 Multimodal Affective Representation / 多模态情感表示
多模态情感表示对应第二个挑战:情感鸿沟。论文认为,现有方法大体分为两类:感知情感映射和多模态情感协调。前者主要处理模态内部问题,让编码器更擅长捕捉情感线索;后者主要处理模态之间的问题,让不同来源的情感信息能够充分交互。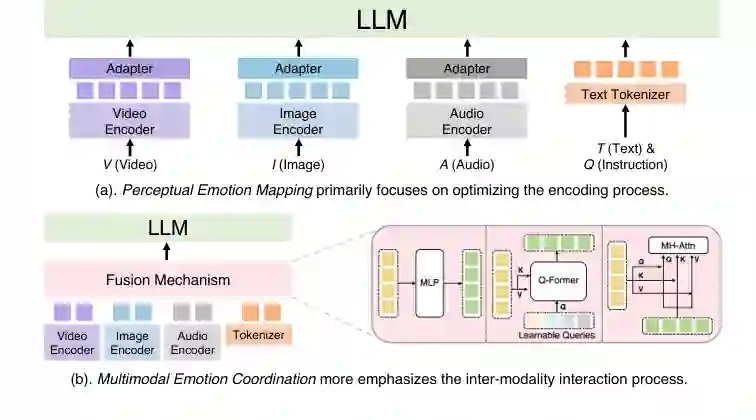
感知情感映射
通用多模态编码器通常在通用数据上预训练,不一定擅长捕捉情绪。感知情感映射的目标,是让编码过程更“情感敏感”。一种常见方式是通过情感数据和训练日程调整编码器或适配器,使其从事实识别逐步过渡到情感判断。例如,某些方法先学习人脸、动作、语音或场景事实,再学习它们与情绪之间的联系。 另一类方法直接修改或增强编码后的嵌入。比如通过特征锐化过滤掉与情感无关的冗余信息,或引入事件驱动采样、情感知识、专家编码器和一致性约束,使模型更关注真正影响情绪判断的区域、帧或声学线索。
多模态情感协调
多模态情感协调关注跨模态交互。情绪往往不是单个模态能独立决定的:一句话的字面含义可能是积极的,但语气、表情或上下文可能表达讽刺;一张面孔可能显示平静,但对话背景可能揭示紧张。模型需要协调视频、图像、音频和文本之间的关系。 现有方法通常采用拼接、Q-former、注意力或混合专家等机制来融合模态。论文提到,视频级拼接在一些场景中优于帧级交互;层级注意力可以整合不同尺度线索;Q-former 可以通过可学习查询提取指令相关信息;混合专家则能更好地处理多源信息。整体看,这一方向仍有较大潜力,因为跨模态情绪冲突是 MER 的核心难点之一。
5 Multimodal Affective Reasoning / 多模态情感推理
多模态情感推理对应第三个挑战:情感解释不透明。直接给出“开心”“悲伤”“愤怒”等标签,常常不足以建立用户信任,也不利于发现模型是否依赖了错误证据。因此,MER-with-LLMs 自然推动任务从单步分类走向多步解释和推理。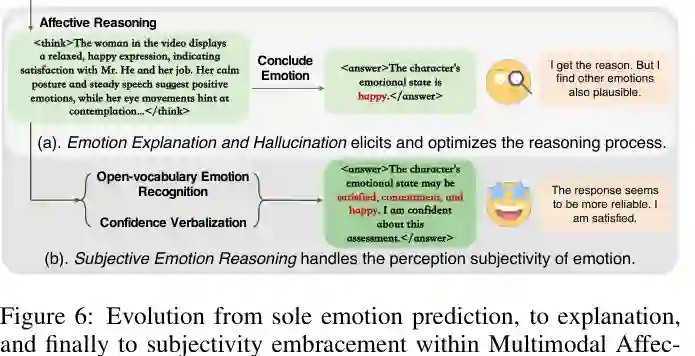
情感解释与幻觉
情感解释方法关注解释的可用性和可靠性。一个核心问题是解释与预测不一致:模型可能预测“开心”,但解释中描述的却是紧张或悲伤线索。Facial-R1 等工作通过数据和强化学习奖励鼓励模型输出更符合事实观察的解释;ERV 训练辅助验证模型检查答案是否忠实于推理;PEP-MEK 引入预测-解释-预测流程,并加入模态特定和情绪相关知识来缓解幻觉。 这一分支的重要性在于,情绪理解不仅是分类问题,也是证据组织问题。模型需要说清楚自己依据的是表情、语气、动作、语义内容还是场景线索,并避免用看似合理但不存在的情感证据支撑结论。
主观情感推理
情绪具有主观性,不同观察者可能对同一内容产生不同感受。这给 MER 带来长期挑战:如果只有一个标准答案,模型可能被迫忽略合理的多解性。论文提到,一些方法开始从固定情绪集合转向开放词汇和多标签表达,让模型识别更细腻的情感状态。 另一个方向是置信度表达和校准。模型不应总是给出确定判断,而应在情绪线索模糊或存在多种解释时表达不确定性。EmoCaliber 等工作尝试让模型学习输出和校准置信度,为主观情绪理解建立更稳健的基线。
6 Model Performance Quantification / 模型性能量化
在定性综述之后,论文进一步汇总代表方法的量化性能。表 5 覆盖 GVEC、VTSA、SEC、FER、CMER 等子任务,列出方法的 taxonomy、技术路线、数据集、评价指标和结果。作者从中观察到几个趋势。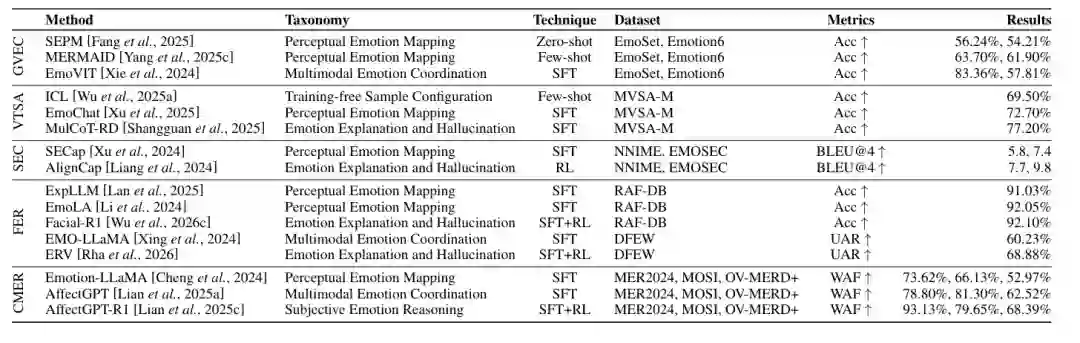
7 Conclusion and Future Directions / 结论与未来方向
最后一节总结全文,并给出未来研究方向。论文认为,MER-with-LLMs 已成为一个快速发展的新范式,但仍处于结构化整理和机制深化的早期阶段。未来需要同时推进任务统一、机制解释、主观性建模、智能体交互和安全公平。
统一与泛化
现有 MER 研究分散在多个子任务中,不同数据集、标签空间和模态组合之间缺少统一框架。未来需要更通用的 MER 模型和评估体系,能够跨图像、视频、音频、文本和会话场景迁移,并处理不同情绪理论和标签体系之间的差异。
机制级探索
论文指出,知道“什么方法有效”还不够,理解“为什么有效”同样关键。未来研究需要探究哪些模型参数、模块和表示真正影响情感感知,模型如何从事实线索过渡到情绪判断,以及情感推理在内部机制上如何形成。
接纳主观性的框架
情绪不是完全客观的标签。未来 MER 系统需要支持开放词汇、多标签、多解释和置信度表达,同时设计能够评估主观性的 benchmark。更进一步,模型应学习在不同文化、个体背景和交互情境下给出更合适的情感理解。
智能体情感理解
直接与真实世界交互将是未来 MER 的重要方向。智能体需要观察、规划、推理、调用工具并接收实时反馈。情感理解不再只是离线识别,而会成为人机协作、陪伴、教育、医疗和客服系统中的动态能力。
安全、公平与文化适应
情感识别高度敏感,涉及偏见、文化差异和个人隐私。论文强调,当前相关研究多停留在数据集构建和经验分析阶段,对具体解决方案探索有限。未来需要更有原则的模型设计和训练策略,让 MER 系统具备文化适应性、偏见意识和个性化理解能力。
总结
整体来看,这篇综述的价值在于把 MER-with-LLMs 从零散论文集合整理成清晰地图:为什么 LLM 会改变多模态情感识别,现有方法如何应对三大挑战,各条路线的代表工作和性能趋势是什么,以及未来还需要补齐哪些能力。对于情感计算和多模态大模型研究者来说,它提供了一个系统入口;对于工程团队来说,它提醒我们,情感识别不只是模型准确率问题,还涉及解释、主观性、安全、公平和真实交互。
原文信息
- 原文标题:Multimodal Emotion Recognition with Large Language Models
- arXiv:https://arxiv.org/abs/2605.21239
- PDF:https://arxiv.org/pdf/2605.21239

