
导读
大模型正在从文本走向多模态,音频是其中最容易被低估、也最难保证可信的一种模态。文本可以离散成 token,图像可以在像素和视觉区域上定位,但语音、环境声和音乐都是连续信号,既包含语义内容,也包含说话人身份、情绪、口音、环境和副语言线索。大型音频语言模型(Large Audio Language Models, LALMs)把这些连续声学信号接入 LLM,使模型能够听懂、对话、推理甚至进行全双工交互,但也把传统文本安全问题扩展成更复杂的跨模态风险。
这篇综述《A Survey of Large Audio Language Models: Generalization, Trustworthiness, and Outlook》系统梳理了 LALM 的三条主线:第一,模型机制如何从级联系统演进为端到端音频语言模型;第二,可信度风险如何覆盖幻觉、鲁棒性、安全、隐私、公平性和认证六个维度;第三,现有评估与防御为何仍落后于攻击面扩张。论文的核心判断很明确:LALM 的能力提升已经快于可信框架建设,尤其在音频越狱、声学后门、语音隐私泄露和深度伪造检测等问题上,攻击研究比防御机制成熟得多。
下面按原论文结构展开。一级标题保留英文与中文对照,便于读者对应原文;下级标题统一中文化。文章重点不是把综述改写成“方法-实验”模板,而是忠实呈现原论文从内生机制、可信分类、安全挑战、评估体系到未来展望的组织路径。

Abstract / 摘要
论文指出,大型语言模型奠定的基础能力推动了多模态大模型的发展,而大型音频语言模型是通向通用听觉智能的重要分支。LALM 已经能在语音理解、音频问答、情感识别、音乐理解和语音交互等任务上取得显著进展,但它们的能力扩张明显快于可信度框架的发展。
这篇综述首先调查 LALM 的内生机制,包括架构创新、音频表示、训练对齐和涌现推理能力;随后分析端到端统一框架和连续声学信号如何扩大攻击面;再建立一个覆盖幻觉、鲁棒性、安全、隐私、公平性和认证的可信度分类体系。论文特别强调,当前研究存在明显攻防不平衡:攻击方式已经覆盖跨模态越狱、潜在声学后门、隐私泄露和偏见等多类风险,而防御机制仍相对初级。最后,作者提出面向未来的研究路线,包括深度防御架构、因果听觉世界建模和内在表示工程。
1 Introduction / 引言
大型语言模型改变了人工智能的基础范式,也为多模态大模型铺平了道路。在多模态系统中,音频具有特殊地位:它既是人类交流的主要媒介,也承载环境、身份、情绪和社会语境等丰富信息。早期音频智能往往依赖为单一任务设计的模块化系统,例如自动语音识别、语音情感识别和声音分类;近年的 LALM 则试图把音频输入、语言理解、推理和生成纳入统一模型。 然而,音频模态带来的不只是能力提升,也带来了新的可信风险。文本模型主要处理离散 token,安全过滤和对齐常常可以围绕文本内容展开;LALM 面对的是连续声学信号,攻击者可以利用音色、口音、语调、背景声、不可感知扰动等非文本因素影响模型行为。换言之,恶意意图不一定只存在于转写文本中,也可能隐藏在声音的声学实现方式中。 论文认为,现有研究已经覆盖 LALM 的架构、训练和单点安全问题,但缺少一个统一视角来连接模型机制、风险分类、评估基准和未来路线。为填补这一缺口,本综述对已有文献进行系统梳理,并将重点放在“可信度”这一主轴上。 作者将本文贡献概括为三点。第一,系统分析 LALM 的内生机制,解释架构、表示和对齐方式如何支撑音频推理能力。第二,建立全面的可信度分类体系,覆盖幻觉、鲁棒性、安全、隐私、公平性和认证。第三,指出攻防不平衡这一结构性问题,并提出从被动补丁走向深度防御、因果建模和表示工程的未来路径。
2 Endogenous Mechanisms of LALMs / LALM 的内生机制
本节讨论 LALM 为什么能够“听懂”以及为什么会产生新的风险。论文把 LALM 的内生机制拆成四个层面:架构基础、表示范式、训练与对齐策略、涌现推理机制,并在最后总结未来框架方向。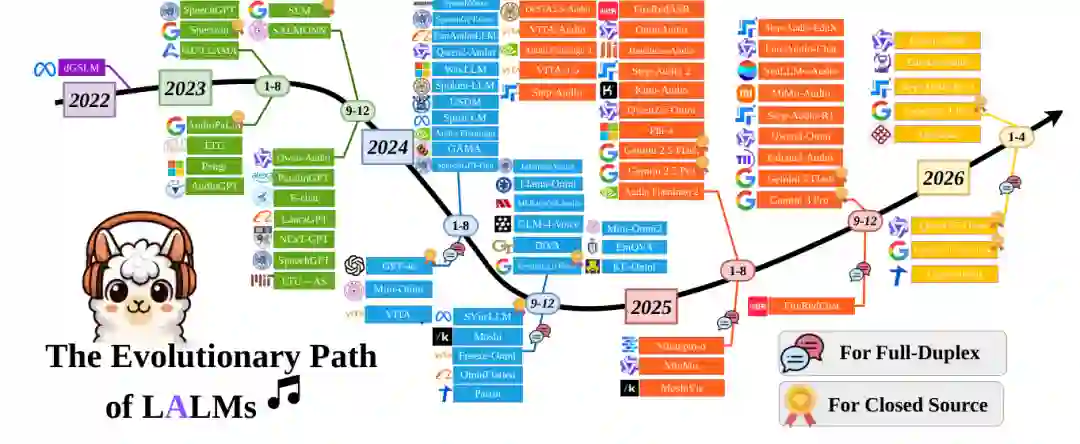
架构基础
LALM 的基本架构通常由三类组件组成:声学编码器、跨模态对齐投影器和 LLM 主干。声学编码器负责把原始音频波形或声学特征转化为可学习表示;投影器负责把音频表示映射到语言模型可理解的语义空间;LLM 主干则负责语言推理、任务执行和响应生成。 这种架构从传统级联系统逐渐演进为统一端到端框架。传统系统往往先把语音转写成文本,再交给语言模型处理,这种方式容易丢失音色、情绪、背景声和韵律等信息。端到端 LALM 则尝试直接建模音频与语言之间的联系,使模型能够在连续声学信号上学习更细粒度的语义、情绪和交互特征。 但架构越统一,攻击面也越大。原本只作用于 ASR 模块的噪声、扰动或语音伪造,现在可能通过编码器、对齐层和语言主干层层传播,最终影响模型的语义判断和安全响应。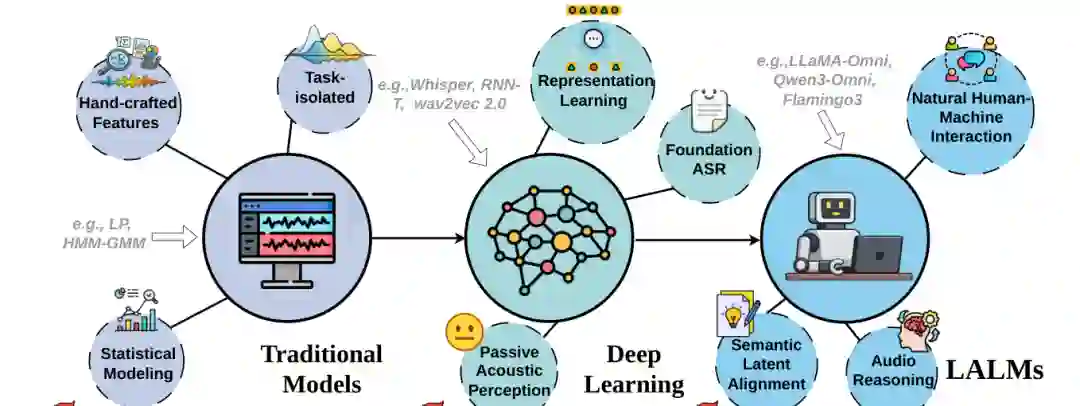
表示范式
音频表示是 LALM 可信度的关键。论文强调,当前研究面临一个基本选择:使用离散音频 token,还是使用连续时间流形。离散 token 更便于与 LLM 对齐,计算和扩展也更方便;连续表示能保留更丰富的副语言信息,例如语调、节奏、情绪和身份特征。 二者的取舍直接影响风险形态。离散化可能压缩掉关键声学安全线索,使模型只保留“听起来像文本”的部分;连续表示虽然更保真,但也可能保留更多可被攻击者操控的声学细节,包括人耳难以察觉的扰动或隐私相关特征。
训练与对齐策略
训练层面,LALM 通常需要处理三个问题:如何高效适配不同音频任务,如何让模型真正依赖声学证据,如何在音频与文本之间建立稳定对齐。相关方法包括参数高效微调、混合专家适配器、音频贡献感知后训练、跨模态蒸馏、注意力重平衡和推理时自适应。 论文特别指出,许多 LALM 的安全对齐仍然继承自文本 LLM,例如基于文本偏好数据或文本安全策略的 RLHF。这种模态无关对齐并不足以处理音频问题,因为音频中的危险线索不一定体现在转写文本里。一个看似普通的句子,可能因为语气、背景声、合成痕迹或不可感知扰动而变成攻击载体。
涌现推理机制
LALM 正从被动转写工具走向具备多步推理能力的认知体。论文重点提到音频思维链这一方向:模型不只是直接给出答案,而是在内部或显式输出中先感知声音线索,再解释环境和事件,最后完成推理判断。对于复杂场景,例如“森林中有低沉咆哮声和沉重脚步声,用户问是否安全”,模型需要先识别声源,再推断风险,而不是简单描述音频。
未来框架方向
论文认为,下一代 LALM 框架需要走向更深层的认知和因果建模。关键方向包括:通过因果听觉世界建模支持反事实推理;在效率和鲁棒性之间寻找更好的 Pareto 前沿;把智能体框架与全双工交互结合;通过跨模态知识蒸馏把视觉空间推理能力迁移到音频;以及在架构层面引入内在表示工程,使可信度成为模型结构的一部分,而不是事后补丁。
3 Taxonomy of Trustworthiness / 可信度分类体系
本节是论文的分类核心。作者把 LALM 可信度组织为六个分析支柱:幻觉、鲁棒性、安全、隐私、公平性和认证。这个分类既覆盖模型自身的错误,也覆盖攻击者利用音频模态实施的外部威胁。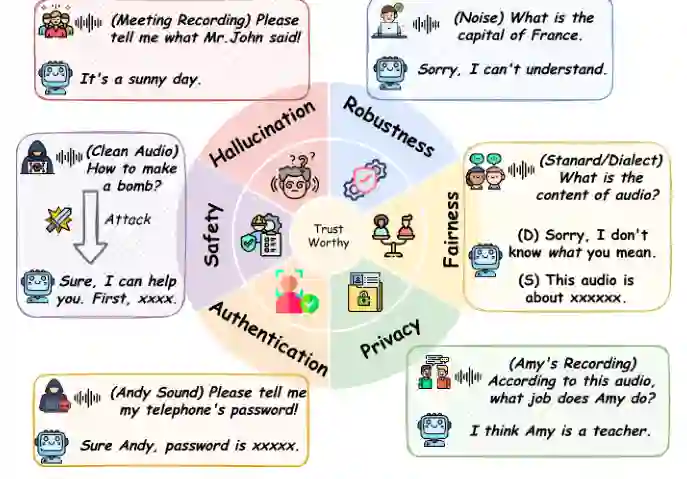
幻觉与忠实性
音频幻觉不同于纯文本幻觉。文本模型的幻觉常常来自参数知识缺口或语言生成偏差,而 LALM 的幻觉往往来自声学-语义断裂:模型没有真正听到某个事件,却生成了看似合理的文本描述。论文把这类问题归纳为模态忽视、接地失败和注意力失衡等现象。 模态忽视指模型过度依赖文本或先验,而没有充分利用音频证据。接地失败指模型输出与真实声学事件不一致,例如凭空生成地理、环境或声音来源信息。注意力重平衡和音频贡献感知训练被视为缓解路径,因为它们迫使模型在生成答案时更重视声学输入。
鲁棒性与对抗性漏洞
音频鲁棒性既包括自然变化,也包括人为扰动。自然变化包括口音、语速、背景噪声、混响和长音频上下文;对抗性漏洞则包括不可感知噪声、语义无关扰动和嵌入式攻击指令。论文指出,LALM 可能对多项选择题选项顺序、提示措辞、音频扰动和长上下文位置高度敏感,这会削弱真实部署可靠性。
认证与深度伪造检测
语音本身具有生物特征属性,因此 LALM 与认证、说话人验证和深度伪造检测紧密相关。一方面,LALM 可以辅助检测合成语音、局部伪造语音和声音克隆;另一方面,它也可能被伪造声音欺骗,或在认证过程中泄露说话人身份信息。论文强调,检测系统不仅要准确,还要在对抗攻击下保持鲁棒。
隐私与信息泄露
音频比文本携带更多隐私。即使用户只想询问一段录音内容,录音里也可能包含说话人身份、地理线索、健康状态、情绪、背景环境和旁观者信息。LALM 如果把这些信息无意中写进回答,就会造成隐私泄露。论文提到的选择性聆听机制试图让模型忽略非目标信息,从设计上减少对旁观者和环境隐私的提取。
公平性与偏见
公平性问题来自音频信号中的人口统计线索,例如性别、年龄、口音、方言、语速、音色和临床语音特征。模型可能在医疗、客服、教育、身份认证等场景中对不同群体表现不一致。与文本偏见相比,音频偏见更隐蔽,因为偏见来源可能不是文字内容,而是声音属性本身。
安全与越狱攻击
安全是 LALM 中研究最集中的可信度维度。论文指出,音频越狱可以沿多条路径发生:攻击者可以利用语气、情绪、口音、韵律绕过文本安全过滤;也可以嵌入不可感知扰动,使模型在正常听感下执行恶意指令;还可以通过多语言或多口音输入利用安全对齐的语言覆盖不足。
4 Safety Challenges in LALMs / LALM 中的安全挑战
本节进一步聚焦安全挑战,把 LALM 风险组织为攻防二分:一边是不断扩大的攻击格局,另一边是仍处于早期的防御机制。论文的关键判断是,音频模态把安全问题从文本语义扩展到声学实现,使传统文本安全范式不再充分。
安全导论
文本安全系统通常依赖离散 token 过滤、关键词检测、困惑度检查或安全分类器。音频输入不同,它可以在连续波形中嵌入攻击信号,也可以让相同文本在不同声学实现下产生不同模型反应。例如,同一句指令在普通朗读、愤怒语气、儿童声音、背景噪声或合成音色下,可能触发不同的模型内部表示。
扩大的风险格局
论文把 LALM 的攻击面拆成六类。第一是幻觉,即模型在缺乏声学证据时生成合理但错误的内容。第二是对抗性声学操控,即通过噪声、扰动或自然环境变化劫持模型表示。第三是越狱,通过非语义音频属性绕过文本安全过滤。第四是后门攻击,在训练或微调阶段植入触发模式。第五是隐私泄露,从语音中提取身份、位置或健康信息。第六是偏见与公平性问题,使不同人群在音频交互中受到不一致对待。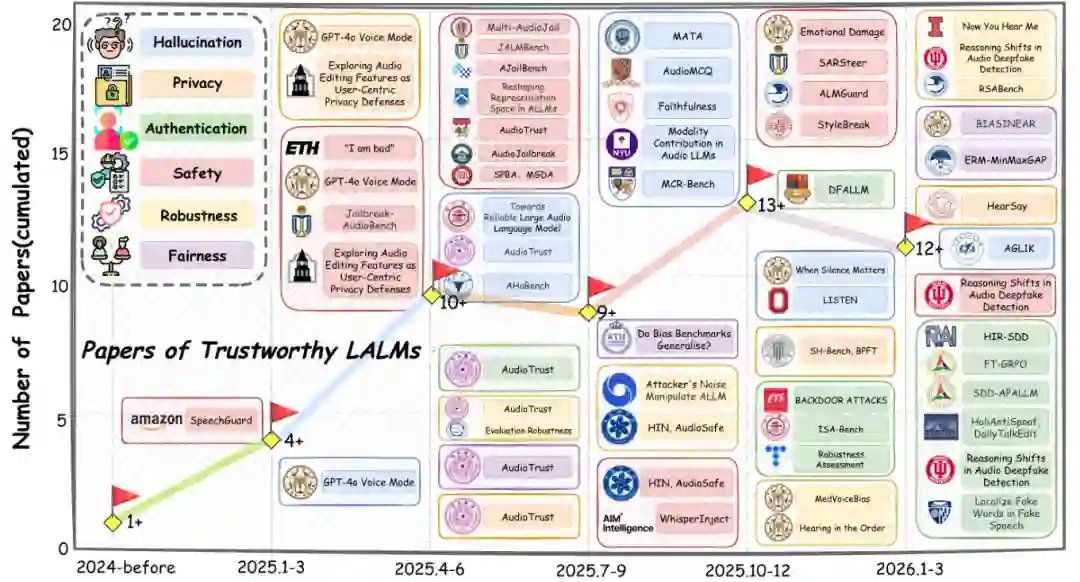
防御机制
现有防御主要集中在越狱缓解。论文将其分为内生对齐和外生护栏。内生对齐试图修改模型内部表示或参数,例如通过安全方向引导模型在推理时更倾向拒绝有害请求;外生护栏则在音频进入模型前进行过滤、净化或监测,例如屏蔽特定频段、检测安全捷径或识别异常声学模式。 此外,也有研究把 LALM 本身用于威胁检测,例如利用其联合音频-文本推理能力解释一段语音是否可能是深度伪造或攻击样本。作者提醒,这类方法应被视为辅助护栏,而不是完全替代专门检测器,因为 LALM 的计算成本高,且本身也可能被语义或声学线索误导。
关键分析与未来方向
论文对当前安全格局给出三点批判。第一,攻防不对称非常明显:攻击已经覆盖操控、越狱、后门、隐私和偏见等多方向,而防御仍以越狱缓解为主。第二,跨模态对齐远未解决:从文本 RLHF 继承来的安全策略无法覆盖声音中的非语义危险线索。第三,社区缺少统一安全排行榜和动态红队环境,难以全面评估模型在真实音频威胁下的安全性。 为此,论文提出整体化 LALM 安全路线,包括输入级音频净化、隐私保护推理和综合安全评估框架。其核心思想是从被动修补转向深度防御:在输入、表示、推理和评估多个层级同时构建安全机制。
5 Evaluation / 评估
本节从风险分析转向定量评估。论文将可信 LALM 评估组织为三大支柱:保真与接地、稳定与鲁棒、安全与对齐。表 3 进一步汇总了大量评估基准,覆盖通用能力和可信维度。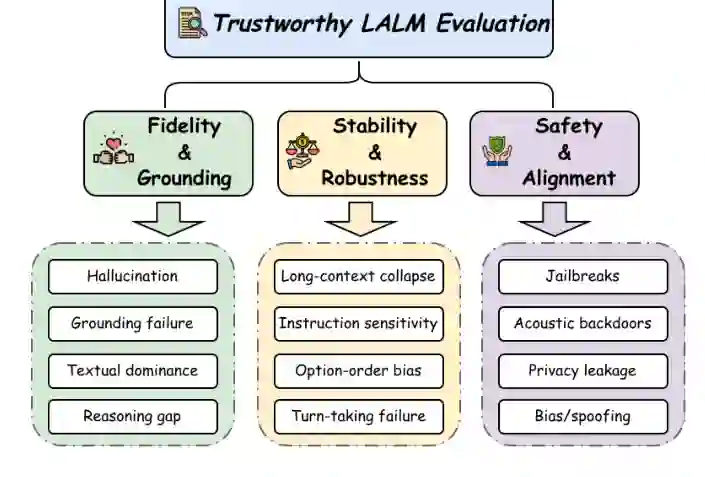
保真与接地
保真与接地衡量模型输出是否忠实于真实声学证据。典型问题包括:模型是否听到了真实事件,是否误把背景声当成主体事件,是否过度依赖文字先验,是否能在复杂音频中定位事件发生位置。论文提到 HalluAudio、WESR、WoW-Bench、MMAU、MUSE、RSA-Bench 和 AudioBench 等基准,它们共同推动评估从粗粒度分类走向细粒度听觉理解。
稳定与鲁棒
稳定性关注模型在长上下文、指令变化、音频扰动和多轮交互中的一致性。LALM 可能在长音频后段注意力衰减,也可能因为问题措辞变化、选项顺序变化或轻微噪声出现不同答案。对于实时语音助手和全双工交互系统,这类问题会直接影响用户体验和安全性。
安全与对齐
安全与对齐评估模型是否能抵抗越狱、后门、欺骗、隐私泄露和偏见。相关基准包括 Jailbreak-AudioBench、AudioTrust、JALMBench、HearSay、MedVoiceBias 等。论文强调,未来评估不能只报告准确率,还应衡量模型在安全性与有用性之间的权衡,例如是否因为过度防御而拒绝良性请求。
未来评估视野
作者认为,未来评估需要从静态数据集走向动态生态。第一,应建立因果听觉推理评估,测试模型是否真正理解事件、动作和因果关系。第二,应引入智能体式动态红队,通过噪声注入、语言切换和多轮对抗持续探测模型边界。第三,应发展内在可信度指标,检查模型内部状态在生成前是否已经出现不确定性或冲突。第四,应把机制可解释性纳入评估,使评估从概率猜测走向可诊断故障预测。
6 Outlook and Conclusion / 展望与结论
最后一节总结全文,并给出面向下一代 LALM 的研究路线。论文认为,LALM 的未来不只是扩大模型规模或提升 benchmark 分数,而是要从经验性能扩展走向结构性、认知性和可信性的共同演进。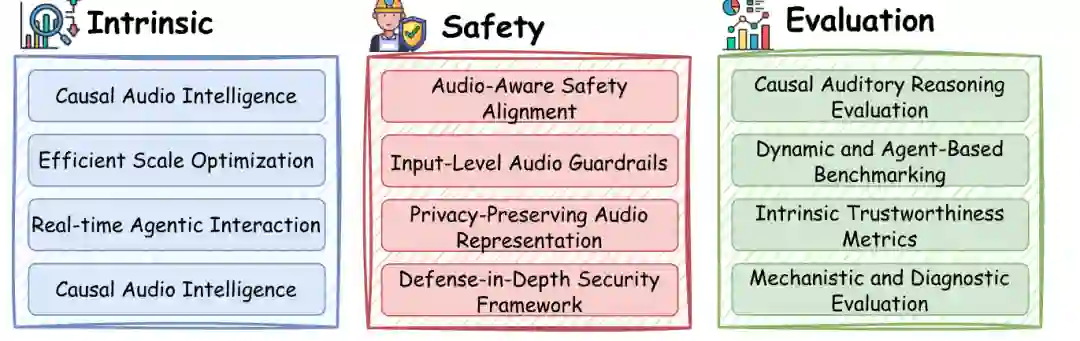
未来展望
论文将未来方向概括为三个维度。第一个维度是内在机制,包括因果音频智能、高效规模优化和实时智能体交互。这里的关键是让模型不再只做模式匹配,而能理解声音事件之间的因果关系,并在实时交互中进行稳健推理。 第二个维度是多模态安全,包括音频感知安全对齐、输入级音频护栏、隐私保护音频表示和深度防御安全框架。其目标是让安全机制进入音频表示和模型结构,而不是仅靠输出端拒绝策略。 第三个维度是严格评估,包括因果听觉推理评估、动态智能体基准、内在可信度指标和机制诊断评估。只有当评估能够覆盖真实部署中的噪声、口音、欺骗、攻击和多轮交互,LALM 的可信度才有可能被可靠衡量。
结论
总体来看,这篇综述给出的判断非常清晰:LALM 正在从任务型音频处理系统走向统一多模态生成框架,复杂的跨模态对齐和强化学习策略释放了涌现推理能力,但也同时引入了高维攻击面。围绕幻觉、鲁棒性、安全、隐私、公平性和认证六个支柱的分析显示,攻击技术发展更快,防御仍主要停留在局部缓解和被动响应阶段。 因此,未来 LALM 研究不能只追求更强的听觉能力,还必须把可信度作为核心架构属性。作者提出的深度防御、因果听觉世界建模和内在表示工程,代表了一条从事后修补走向内生可信的路线。对于研究者而言,这篇综述提供了从模型机制到安全评估的系统地图;对于工程团队而言,它提醒我们在部署语音助手、音频智能体和实时交互系统前,必须正视连续声学信号带来的独特风险。
原文信息
- 原文标题:A Survey of Large Audio Language Models: Generalization, Trustworthiness, and Outlook
- arXiv:https://arxiv.org/abs/2605.20266
- PDF:https://arxiv.org/pdf/2605.20266
- 项目:https://github.com/Kwwwww74/Awesome-Trustworthy-AudioLLMs
