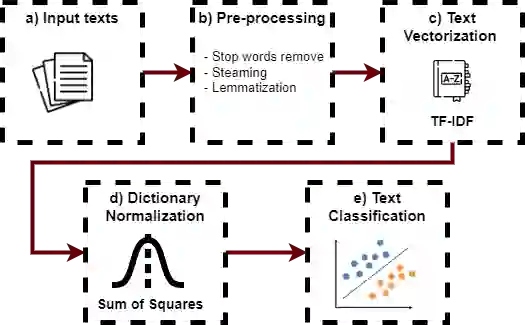
With the popularization of the internet, smartphones and social media, information is being spread quickly and easily way, which implies bigger traffic of information in the world, but there is a problem that is harming society with the dissemination of fake news. With a bigger flow of information, some people are trying to disseminate deceptive information and fake news. The automatic detection of fake news is a challenging task because to obtain a good result is necessary to deal with linguistics problems, especially when we are dealing with languages that not have been comprehensively studied yet, besides that, some techniques can help to reach a good result when we are dealing with text data, although, the motivation of detecting this deceptive information it is in the fact that the people need to know which information is true and trustful and which one is not. In this work, we present the effect the pre-processing methods such as lemmatization and stemming have on fake news classification, for that we designed some classifier models applying different pre-processing techniques. The results show that the pre-processing step is important to obtain betters results, the stemming and lemmatization techniques are interesting methods and need to be more studied to develop techniques focused on the Portuguese language so we can reach better results.
翻译:随着互联网、智能手机和社交媒体的普及,信息得以快速便捷地传播,这导致了全球信息流量的增加,但同时也存在一个危害社会的问题——假新闻的传播。在信息流更大的背景下,一些人试图传播具有欺骗性的信息和假新闻。自动检测假新闻是一项具有挑战性的任务,因为要获得良好的结果,必须处理语言学问题,尤其是当我们处理尚未被全面研究的语言时。此外,一些技术在处理文本数据时有助于取得良好结果,尽管如此,检测这种欺骗性信息的动机在于人们需要知道哪些信息是真实可信的,哪些不是。在本研究中,我们展示了词形还原和词干提取等预处理方法对假新闻分类的影响,为此我们设计了一些分类器模型,并应用了不同的预处理技术。结果表明,预处理步骤对于获得更好的结果至关重要,词干提取和词形还原技术是有趣的方法,需要进一步研究以开发针对葡萄牙语的技术,从而取得更优的结果。