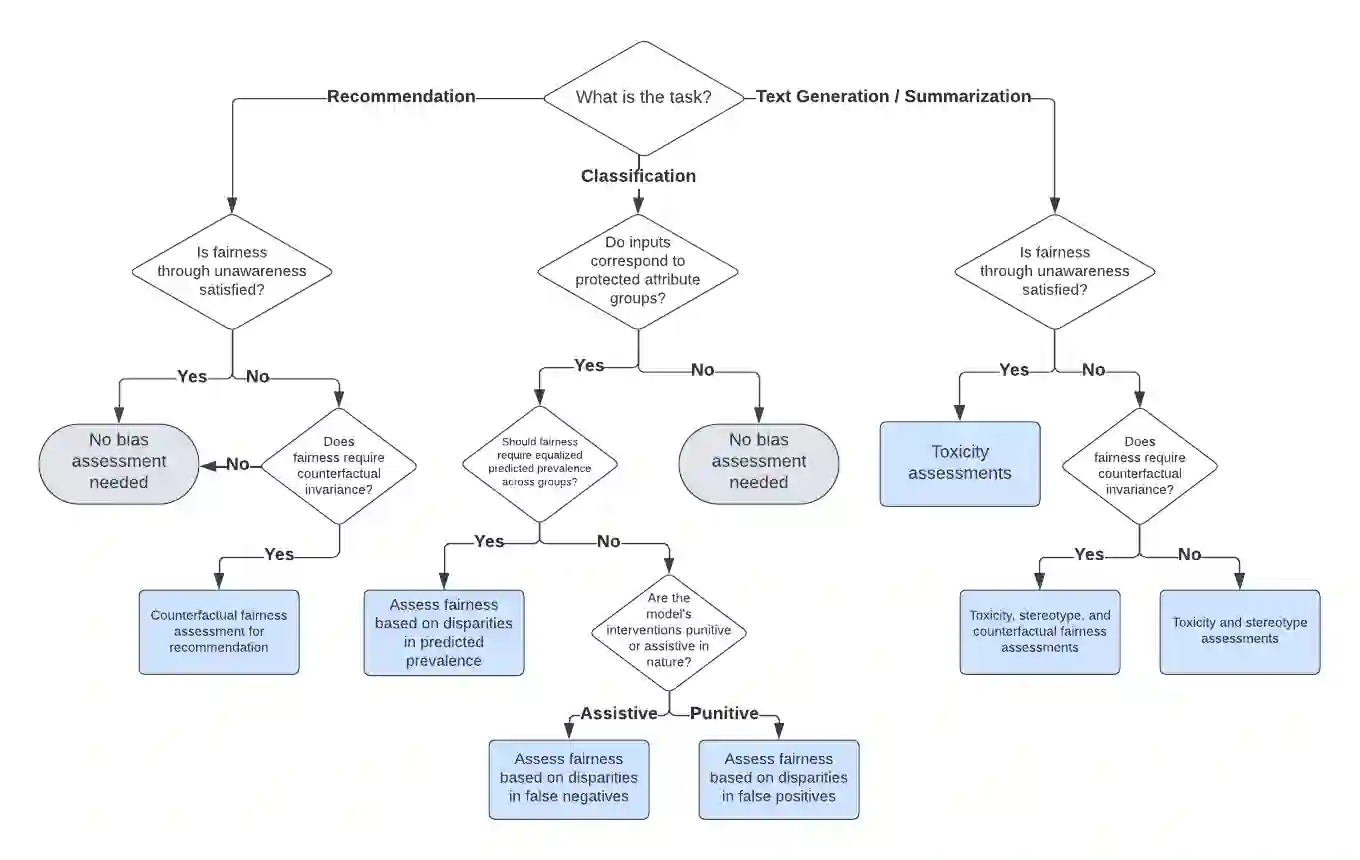
Large language models (LLMs) can exhibit bias in a variety of ways. Such biases can create or exacerbate unfair outcomes for certain groups within a protected attribute, including, but not limited to sex, race, sexual orientation, or age. This paper aims to provide a technical guide for practitioners to assess bias and fairness risks in LLM use cases. The main contribution of this work is a decision framework that allows practitioners to determine which metrics to use for a specific LLM use case. To achieve this, this study categorizes LLM bias and fairness risks, maps those risks to a taxonomy of LLM use cases, and then formally defines various metrics to assess each type of risk. As part of this work, several new bias and fairness metrics are introduced, including innovative counterfactual metrics as well as metrics based on stereotype classifiers. Instead of focusing solely on the model itself, the sensitivity of both prompt-risk and model-risk are taken into account by defining evaluations at the level of an LLM use case, characterized by a model and a population of prompts. Furthermore, because all of the evaluation metrics are calculated solely using the LLM output, the proposed framework is highly practical and easily actionable for practitioners.
翻译:大语言模型(LLMs)可能以多种方式表现出偏见。此类偏见可能对受保护属性(包括但不限于性别、种族、性取向或年龄)内的特定群体造成或加剧不公平结果。本文旨在为从业者提供评估LLM应用场景中偏见与公平性风险的技术指南。本工作的主要贡献在于提出一个决策框架,使从业者能够针对特定LLM应用场景确定应使用的评估指标。为实现这一目标,本研究对LLM偏见与公平性风险进行分类,将这些风险映射到LLM应用场景的分类体系,随后正式定义用于评估各类风险的多样化指标。作为本工作的一部分,我们引入了若干新的偏见与公平性度量指标,包括创新的反事实指标以及基于刻板印象分类器的指标。通过将评估定义在LLM应用场景层面(以模型和提示种群为特征),本框架不仅关注模型本身,同时兼顾提示风险与模型风险的敏感性分析。此外,由于所有评估指标仅通过LLM输出结果进行计算,所提出的框架具有高度实用性,便于从业者直接实施。