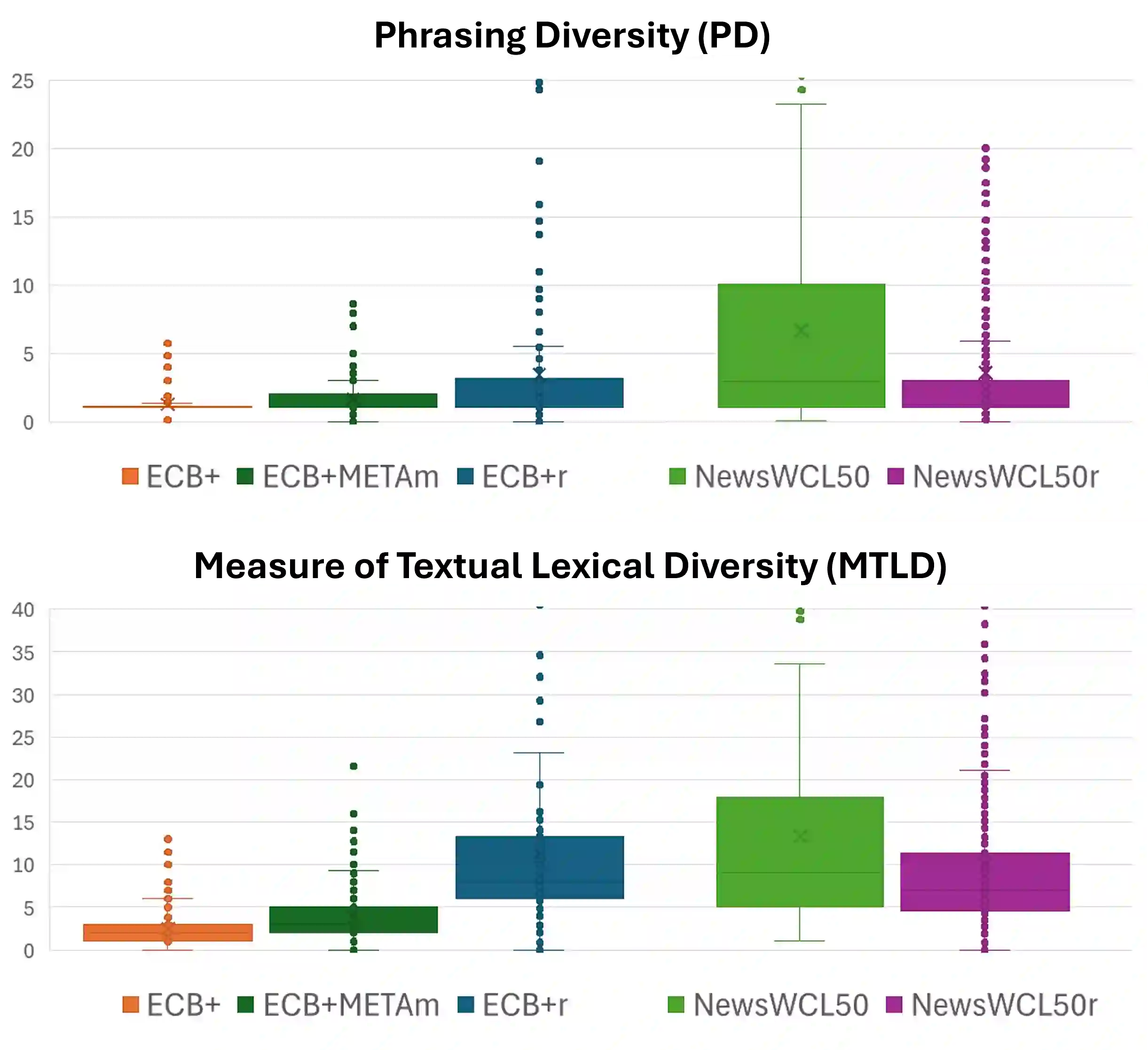
Cross-document coreference resolution (CDCR) identifies and links mentions of the same entities and events across related documents, enabling content analysis that aggregates information at the level of discourse participants. However, existing datasets primarily focus on event resolution and employ a narrow definition of coreference, which limits their effectiveness in analyzing diverse and polarized news coverage where wording varies widely. This paper proposes a revised CDCR annotation scheme of the NewsWCL50 dataset, treating coreference chains as discourse elements (DEs) and conceptual units of analysis. The approach accommodates both identity and near-identity relations, e.g., by linking "the caravan" - "asylum seekers" - "those contemplating illegal entry", allowing models to capture lexical diversity and framing variation in media discourse, while maintaining the fine-grained annotation of DEs. We reannotate the NewsWCL50 and a subset of ECB+ using a unified codebook and evaluate the new datasets through lexical diversity metrics and a same-head-lemma baseline. The results show that the reannotated datasets align closely, falling between the original ECB+ and NewsWCL50, thereby supporting balanced and discourse-aware CDCR research in the news domain.
翻译:跨文档共指消解(CDCR)旨在识别并关联相关文档中同一实体与事件的提及项,从而在话语参与者层面实现信息聚合的内容分析。然而,现有数据集主要聚焦于事件消解,且采用较为狭窄的共指定义,这限制了其在分析用词差异显著、观点多元化的新闻报道时的有效性。本文提出对NewsWCL50数据集的修订版CDCR标注方案,将共指链视为话语元素(DEs)与分析的概念单元。该方法兼容同一性及近同一性关系,例如通过关联“移民车队”-“寻求庇护者”-“考虑非法入境者”,使模型能够捕捉媒体话语中的词汇多样性与框架差异,同时保持对话语元素的细粒度标注。我们使用统一标注手册对NewsWCL50及ECB+的子集进行重新标注,并通过词汇多样性指标及同词干词元基线对新数据集进行评估。结果表明,重新标注的数据集具有高度一致性,其特性介于原始ECB+与NewsWCL50之间,从而为新闻领域均衡且具备话语感知能力的CDCR研究提供支持。