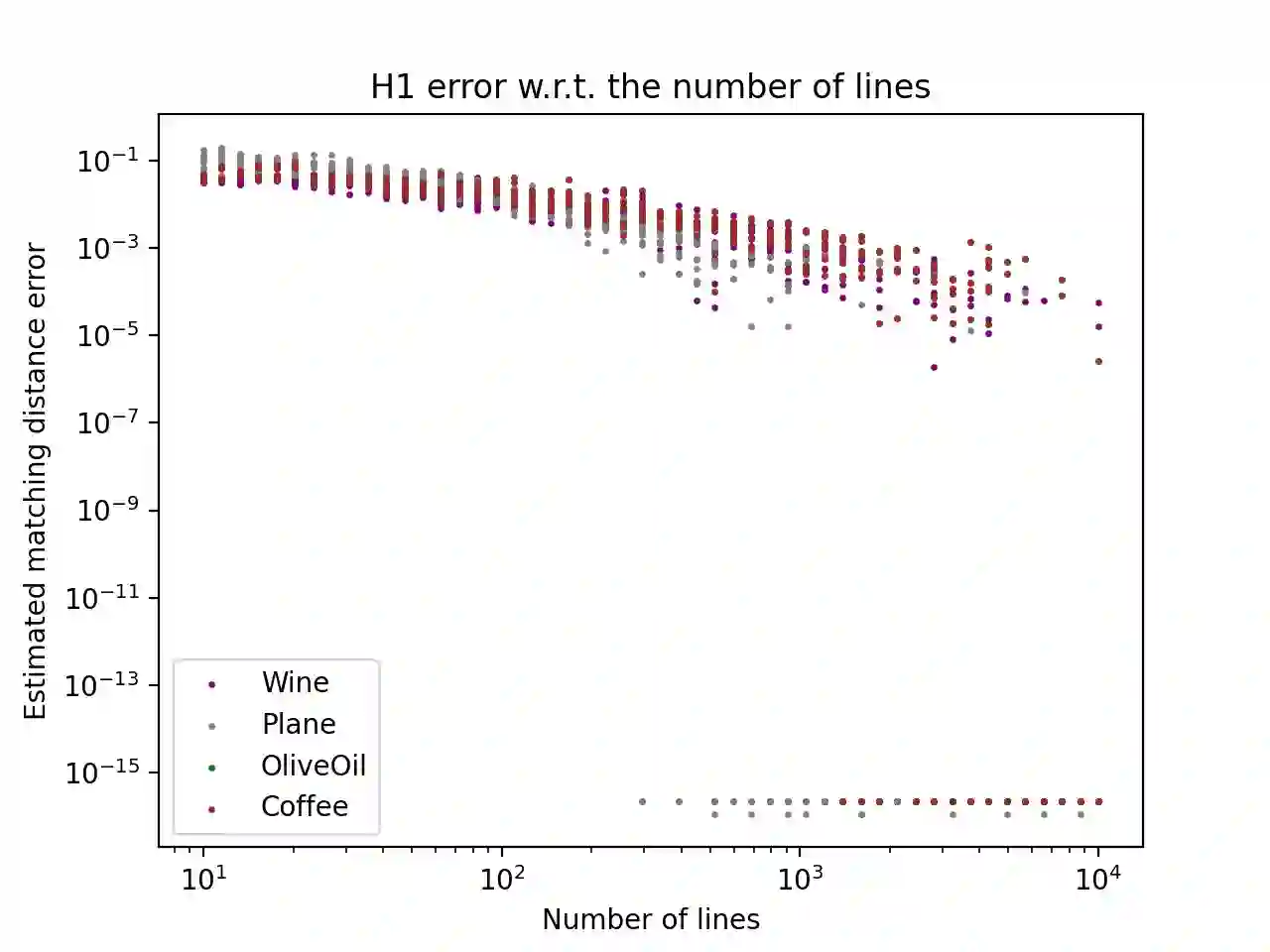
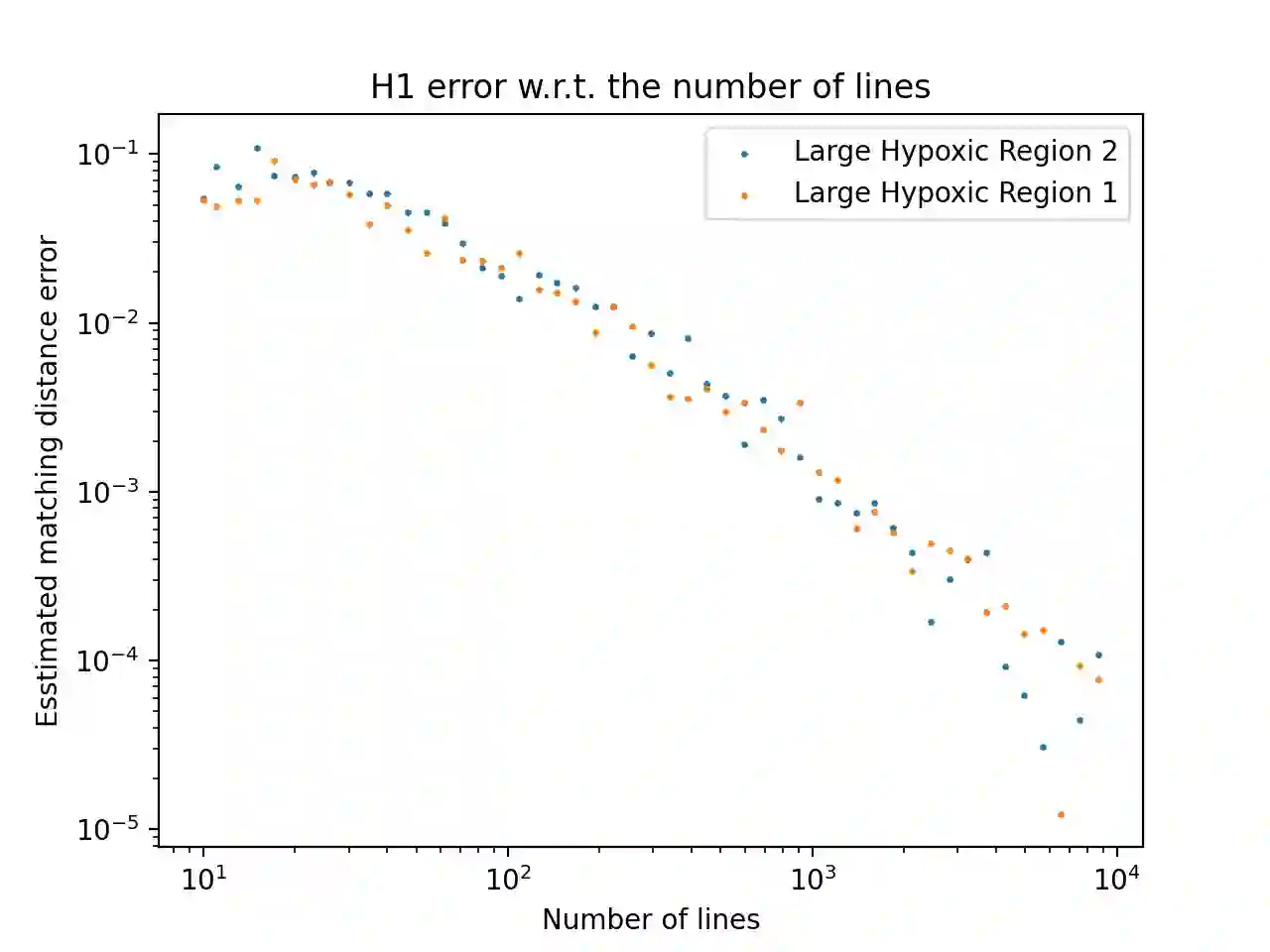
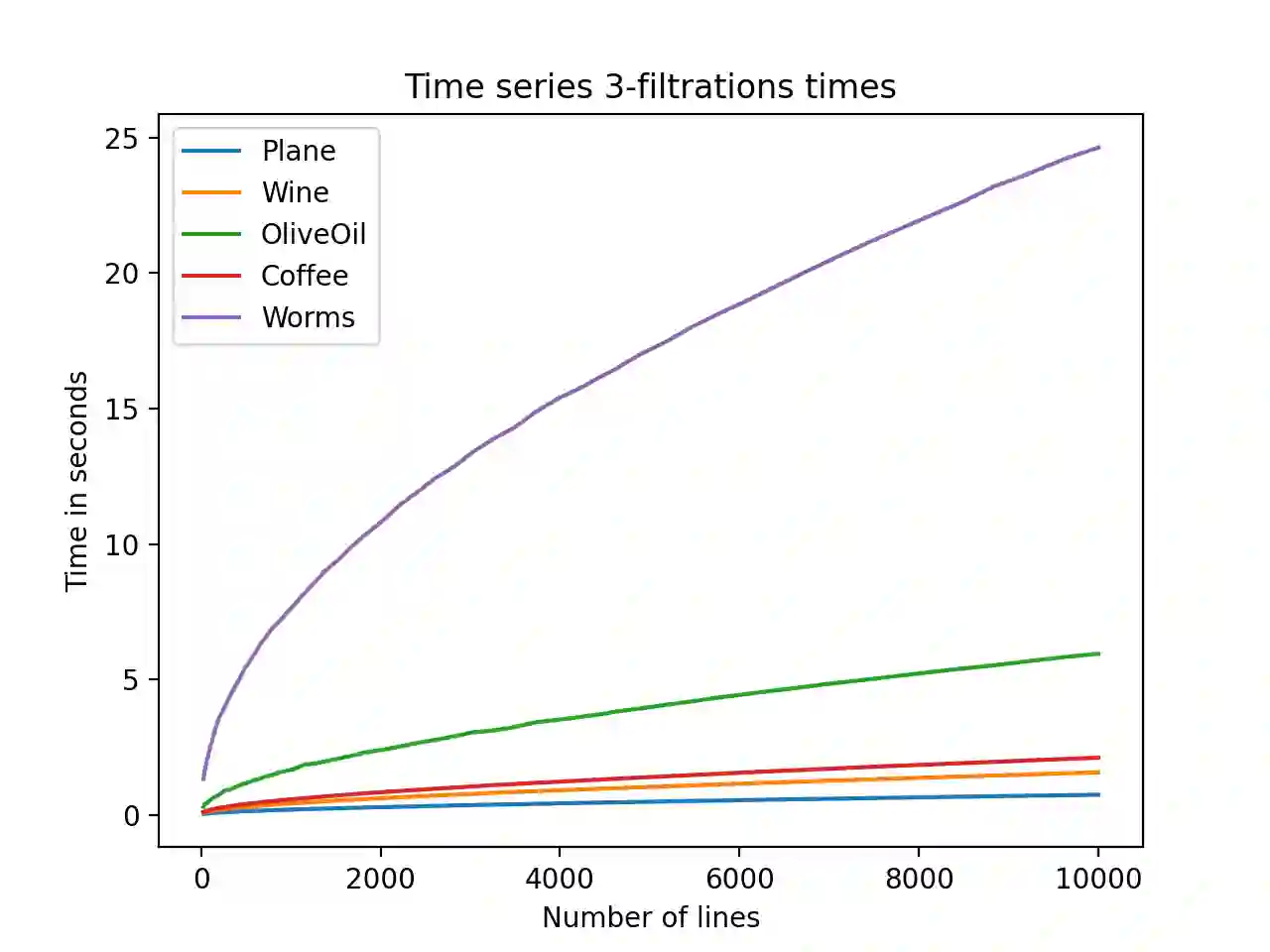
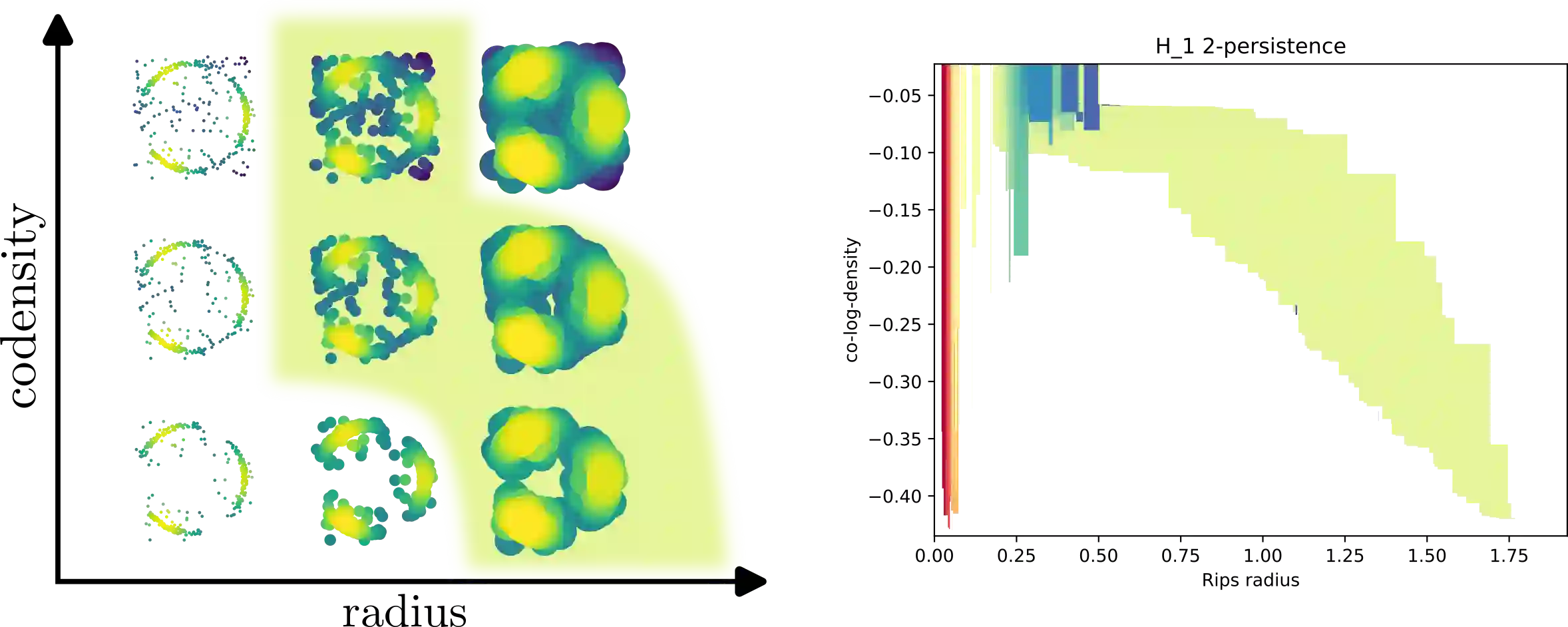Topological Data Analysis is a growing area of data science, which aims at computing and characterizing the geometry and topology of data sets, in order to produce useful descriptors for subsequent statistical and machine learning tasks. Its main computational tool is persistent homology, which amounts to track the topological changes in growing families of subsets of the data set itself, called filtrations, and encode them in an algebraic object, called persistence module. Even though algorithms and theoretical properties of modules are now well-known in the single-parameter case, that is, when there is only one filtration to study, much less is known in the multi-parameter case, where several filtrations are given at once. Though more complicated, the resulting persistence modules are usually richer and encode more information, making them better descriptors for data science. In this article, we present the first approximation scheme, which is based on fibered barcodes and exact matchings, two constructions that stem from the theory of single-parameter persistence, for computing and decomposing general multi-parameter persistence modules. Our algorithm has controlled complexity and running time, and works in arbitrary dimension, i.e., with an arbitrary number of filtrations. Moreover, when restricting to specific classes of multi-parameter persistence modules, namely the ones that can be decomposed into intervals, we establish theoretical results about the approximation error between our estimate and the true module in terms of interleaving distance. Finally, we present empirical evidence validating output quality and speed-up on several data sets.
翻译:拓扑数据分析是数据科学中一个快速发展的领域,旨在计算和表征数据集的几何与拓扑结构,从而为后续统计和机器学习任务生成有用的描述符。其核心计算工具是持续同调,即追踪数据集子集的增长族(称为过滤)中的拓扑变化,并将其编码为代数对象(称为持续模)。尽管单参数情形(即仅需研究一个过滤)下模的算法与理论性质已十分完善,但多参数情形(即同时给定多个过滤)下的研究仍相对匮乏。虽然复杂度更高,但多参数持续模通常包含更丰富的信息,可作为数据科学中更优的描述符。本文提出了首个基于纤维化条形码与精确匹配(两种源于单参数持续理论的结构)的逼近方案,用于计算与分解一般多参数持续模。该算法复杂度可控、运行时间有限,且适用于任意维度(即任意数量的过滤参数)。进一步地,当限制于特定类别的多参数持续模(即可分解为区间的模块)时,我们建立了理论结果,以交错距离度量本逼近与真实模之间的误差。最后,通过多个数据集上的实验验证了输出质量与加速效果。